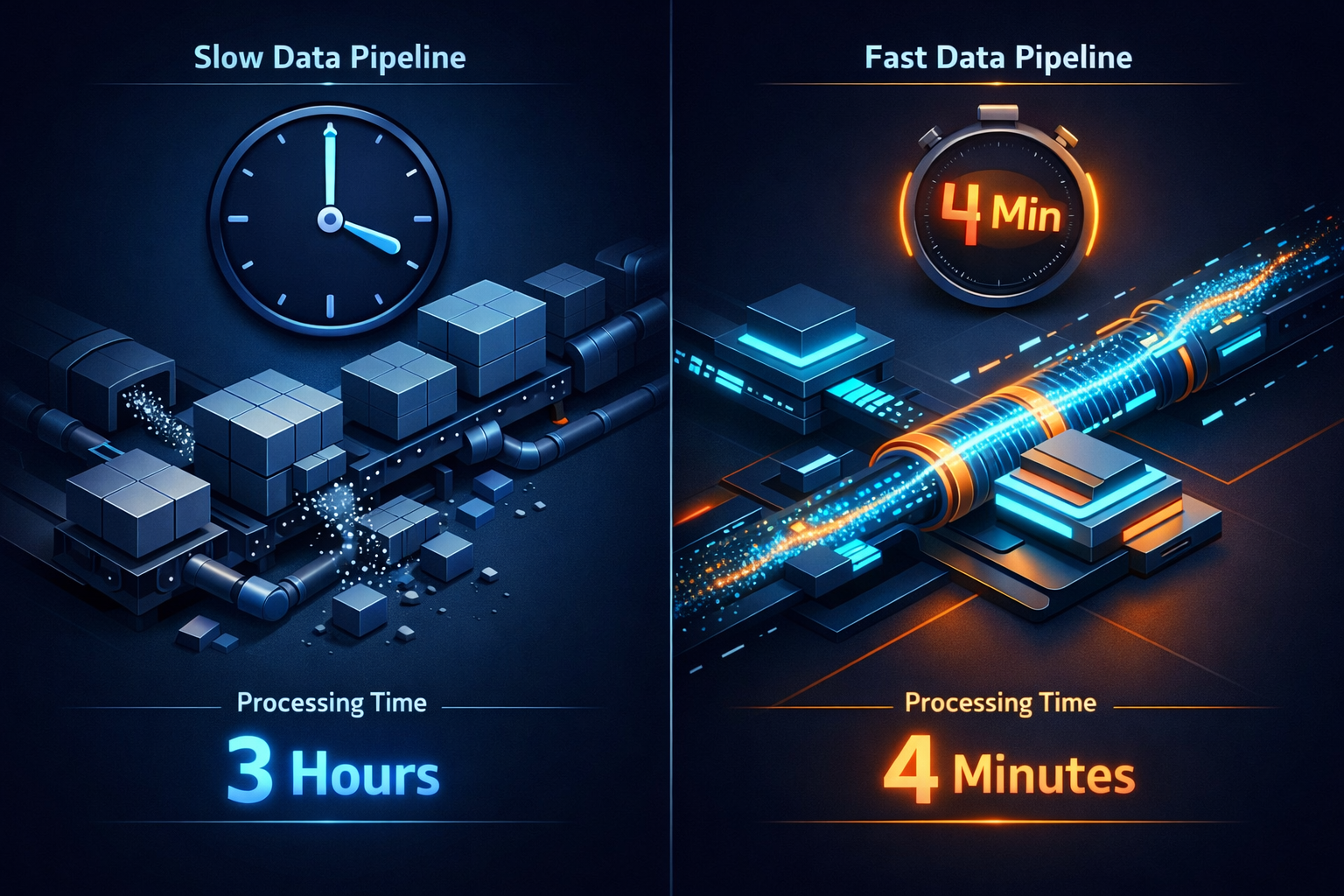
postsConst Generics:Rust 这个功能,让我们少了 85% 的代码从 8347 行到 1243 行,一个密码学库的重生故事January 18, 2026 · 2 min · 364 words · 梦兽编程