Claude Code 记忆系统完全指南:让你的 AI 助手真正记住你的项目

Claude Code 记忆系统完全指南:让你的 AI 助手真正记住你的项目
你有没有遇到过这种情况?每次打开一个新项目,都得从头告诉 Claude:“嘿,我们用 pnpm 不用 npm"“记得用 TypeScript 的严格模式”。累不累?就像每次去一个新公司,都要重新写一遍入职简介。
好消息是,Claude Code 给你配了一个"超级记忆系统”。这个系统比你想象的要聪明得多,它不仅能记住你说了什么,还能自动学习你的项目习惯。今天我们就来好好聊聊这个记忆系统。
两种记忆类型:自动 vs 手动
Claude Code 有两种截然不同的记忆方式,各司其职。

自动记忆(Auto Memory) 就像一个勤快的实习生。它会在工作过程中自动记录有用的信息:项目是怎么构建的、测试有什么惯例、哪些坑已经踩过了。这些知识不是你说让它记的,而是它自己观察、总结出来的。
CLAUDE.md 文件 则是你亲手写的"员工手册"。你的偏好、项目的架构、团队的规范都写在文件里,Claude 每次都会认真阅读。区别在于:自动记忆是 Claude 写给自己的,CLAUDE.md 是你写给 Claude 的。
这两种记忆会在每次会话开始时加载到 Claude 的脑子里。不过自动记忆有个限制:它只会自动加载前 200 行内容——这倒不是因为 Claude 记性不好,而是它希望你把重要的东西放在 CLAUDE.md 里,别让它自己记一堆杂七杂八的。
记忆的层级结构:职级森严的公司
如果你同时设置了项目记忆、用户记忆、还有自动记忆,Claude 会优先听谁的?这就要说到记忆的层级结构了——像公司职级一样,越具体的记忆优先级越高。
| 记忆类型 | 存放位置 | 作用域 |
|---|---|---|
| 托管策略 | 系统级目录 | 全组织 |
| 项目记忆 | ./CLAUDE.md 或 ./.claude/ | 整个项目 |
| 项目规则 | ./.claude/rules/*.md | 按文件类型 |
| 用户记忆 | ~/.claude/CLAUDE.md | 你的所有项目 |
| 自动记忆 | ~/.claude/projects/项目名/ | 当前项目 |
有意思的是,CLAUDE.md 文件可以放在项目目录的任意位置,Claude 会自动往上看,一直看到根目录为止。这就像你在公司里汇报工作,先找直属领导,再逐级往上。同样地,如果你在 src/components/ 子目录下放一个 CLAUDE.md,Claude 只有在这个目录下工作时才会读取它。
自动记忆:Claude 自己的小本子
自动记忆可能是最容易被忽视、但又最有价值的特性。当你在一个项目里工作久了,Claude 会自动记录:
- 构建命令和测试惯例
- 调试问题的解决思路
- 项目架构和模块关系
- 你的工作习惯和偏好
这些记忆放在 ~/.claude/projects/<项目名>/memory/ 目录下。
Claude 会创建一个 MEMORY.md 作为入口,还可能生成各种主题文件,比如 debugging.md、api-conventions.md 之类的。
有个细节特别重要:MEMORY.md 只有前 200 行会被自动加载。所以如果你有重要的笔记,一定要放在前面,或者干脆写到单独的 topic 文件里,Claude 需要用的时候自己会读。
管理自动记忆
你可以用 /memory 命令打开记忆文件列表。这里不仅能看到自动记忆,还能看到所有 CLAUDE.md 文件。更方便的是,你可以在这里开关自动记忆功能,不想让 Claude 记笔记了?关掉就是。
如果你想手动让 Claude 记住点什么,直接告诉它就行。比如:“把我们用 pnpm 不用 npm 记下来"或者"记得测试 API 需要本地 Redis 实例”。它就会把这些写进记忆文件。
自动记忆也可以通过配置文件控制。在 ~/.claude/settings.json 里加上 "autoMemoryEnabled": false 可以全局关闭,对单个项目生效就写在 ./.claude/settings.json 里。最强势的还得是环境变量 CLAUDE_CODE_DISABLE_AUTO_MEMORY,设成 1 就彻底关掉,连配置文件都管不了。
CLAUDE.md 的进阶玩法
如果你以为 CLAUDE.md 只是个简单的笔记文件,那你就太小看它了。这玩意儿有几个骚操作。
导入其他文件

用 @路径 语法可以在一个 CLAUDE.md 里导入其他文件:
# 项目说明
欢迎来到本项目!更多信息请看 @README 和 @package.json。
# 开发规范
- Git 工作流见 @docs/git-workflow.md
相对路径、绝对路径都行,而且支持递归导入,最多 5 层。不过要注意,代码块里的 @ 不会被当成导入,Claude Code 精得很。
如果你有多个 git worktree(我们后面会聊到这个),每个 worktree 都有自己独立的 CLAUDE.local.md。如果你想让所有 worktree 共享一份个人配置,可以用 home 目录的导入:
# 个人偏好
- @~/.claude/my-project-notes.md
对了,CLAUDE.local.md 有个贴心设计:它会自动加入 .gitignore。这就意味着你可以把私人的项目配置写在这里,不用担心一不小心提交到代码库。
模块化规则:.claude/rules/
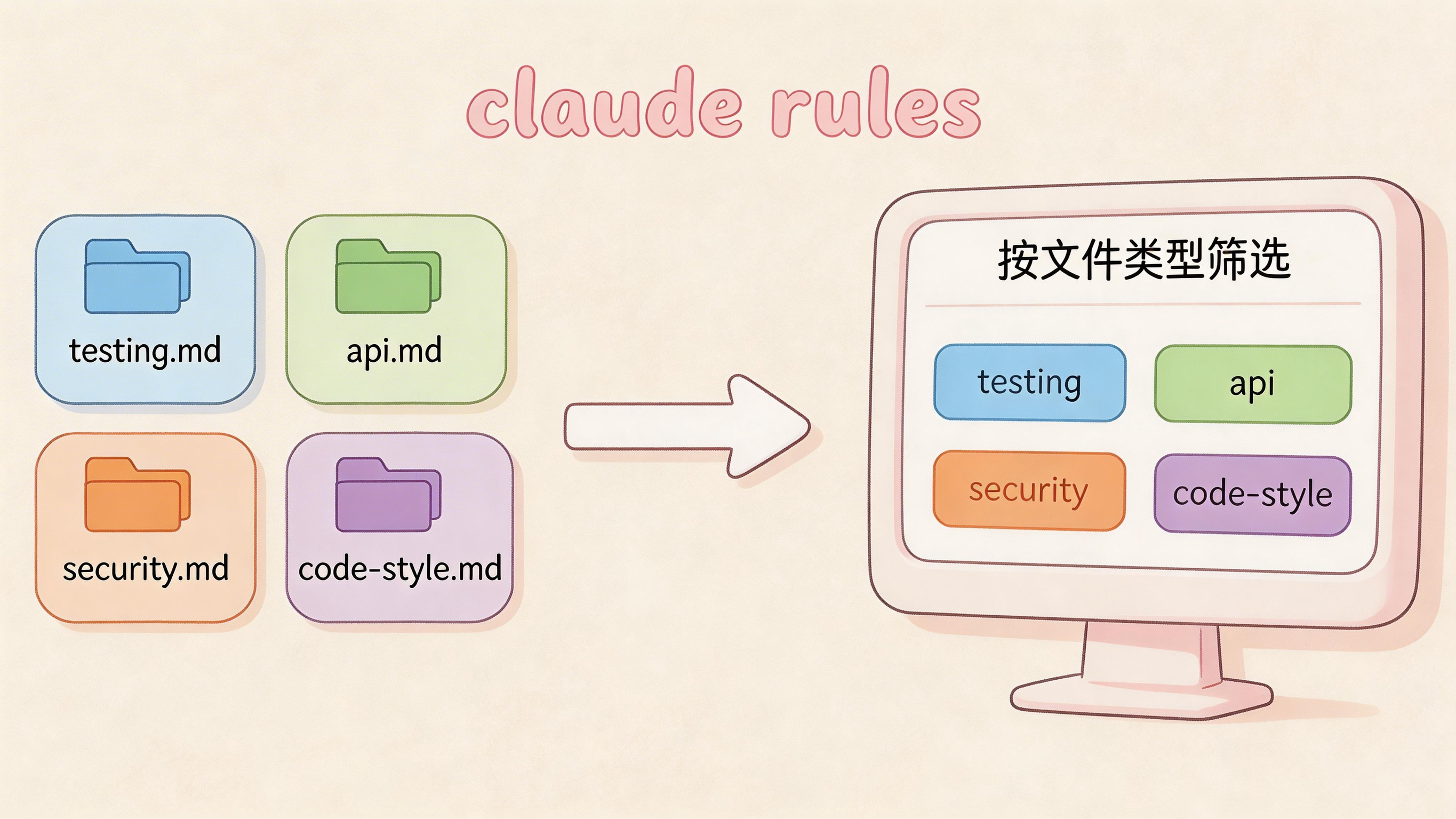
当你的项目变大变复杂,一个 CLAUDE.md 可能不够看。这时候 .claude/rules/ 目录就派上用场了。
在这个目录下放任意多的 .md 文件,Claude 会自动把它们全部加载进来。你可以按主题拆分:测试规范放 testing.md,API 设计放 api.md,安全要求放 security.md。
更厉害的是,规则还可以按文件类型筛选。用 YAML front matter 加上 paths 字段:
---
paths:
- "src/api/**/*.ts"
---
# API 开发规则
- 所有接口必须包含输入验证
- 使用标准错误响应格式
这样这条规则只会在处理 src/api/**/*.ts 文件时才生效。paths 支持标准 glob 模式,**/*.ts、src/**/*、*.md 都不在话下,还能用逗号分隔指定多个模式。
规则文件还可以组织成子目录结构,甚至可以用符号链接共享给多个项目。如果你有通用的编码规范,放在一个地方,然后 ln -s 到各个项目的 rules 目录就行。
给团队用的记忆:组织级管理
如果你是技术负责人,可能想让整个团队都遵循一套规范。没问题,Claude Code 支持组织级记忆管理。
在系统级目录(macOS 是 /Library/Application Support/ClaudeCode/CLAUDE.md,Linux 是 /etc/claude-code/CLAUDE.md)放一个 CLAUDE.md,所有使用这台机器的开发者都会自动加载它。这就像公司发了一本全员手册,入职第一天就开始生效。
当然,这种东西通常要靠配置管理工具(MDM、Ansible 之类的)来统一部署。总不能一个一个去手动设置吧?
实战技巧
说了这么多,怎么用起来才香?给你几个建议:
项目 CLAUDE.md 里,常用的命令一定要放进去:构建、测试、lint。代码风格偏好也写上,还有那些项目特有的架构模式。每次新建项目,跑一下 /init 让 Claude 帮你生成一个模板。
自动记忆这东西,别把它当成主力。主要的记忆还是靠你写的 CLAUDE.md。自动记忆适合记那些你不会主动想起来、但 Claude 需要知道的小细节,比如"上次排查这个 bug 花了我们一下午"。
规则文件什么时候拆?当你的 CLAUDE.md 超过 500 行,或者不同模块的规范差异很大的时候,就该拆了。前端代码和后端代码的测试规范肯定不一样,拆成两个文件好维护。
总结
Claude Code 的记忆系统本质上是一个多层次、可持续的学习机制。自动记忆让 Claude 能在工作中自我进化,CLAUDE.md 让你能精确控制它记住什么,而模块化规则则让大型项目的记忆管理变得井井有条。
用好这个记忆系统,你会发现 Claude 越来越"懂你"——就像一个配合默契的老同事,知道你的习惯,记得你的偏好。这才是真正的 AI 助手。
那么问题来了:你的下一个项目,准备让 Claude 记住什么?
FAQ
Q: 自动记忆会泄露隐私吗?
A: 自动记忆只存储在你本地的 ~/.claude/projects/ 目录下,不会发送到任何服务器。你甚至可以随时删除整个 memory 目录,Claude 不会记得任何东西。
Q: CLAUDE.md 和 auto memory 哪个更重要? A: CLAUDE.md 的优先级高于自动记忆。如果你同时在两处写了冲突的指令,Claude 会优先执行 CLAUDE.md 的内容。
Q: 多个 git worktree 会共享记忆吗?
A: 不会。每个 worktree 有独立的自动记忆目录。但如果你想共享配置,可以用我们前面说的 @~/ 导入语法。