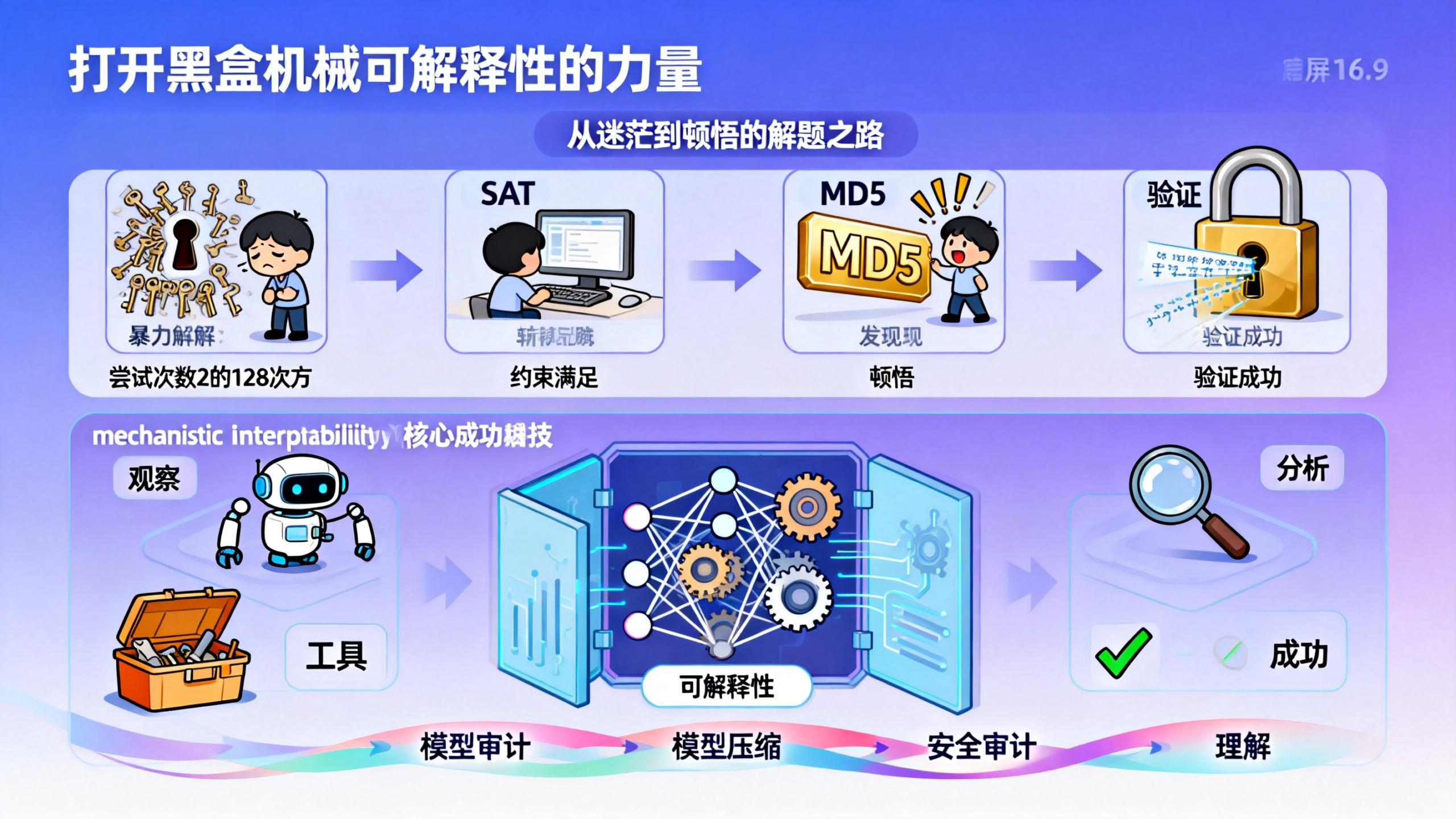
神经网络逆向工程:当机器学习变成解谜游戏

你有没有玩过那种"猜数字"游戏?对方心里想一个数,你猜,他告诉你大了还是小了。几次之后你就能锁定答案。
现在想象一个变种:对方不是一个人,而是一个神经网络。你喂给它一个输入,它只输出 0。不管你给什么,都是 0。问题是:存在一个特殊的输入能让它输出 1 吗?如果存在,怎么找到它?
这就是量化交易公司 Jane Street 去年发布的机器学习解谜游戏。跟普通的 CTF 不一样,他们直接把神经网络的全部权重给你了。没有黑盒,所有信息都在那儿。但即便如此,这道题还是难倒了一大堆人。
不一样的 ML 解谜
市面上大部分 ML 相关的 CTF 题目都是给你一个黑盒模型,让你想办法骗它输出特定的结果。常用的套路是对抗样本攻击,用梯度下降找一个能让网络"犯傻"的输入。
Jane Street 的题目不一样。他们把 model.pt 文件直接给你了,里面有完整的权重。问题陈述简单到离谱:
今天我去远足,在一个新石器时代的墓葬堆下面发现了一堆张量!模型几乎对所有输入都输出 0。如果你能找出它到底在干什么,请告诉我们。
PyTorch 模型文件就是个 pickle,load 出来就能看到所有参数。乍一看这不应该是送分题吗?所有信息都在你手里,还需要什么技巧?
但这个网络有个特殊的设计:你没法用传统的反向传播来求解。网络的结构决定了,从输出往回传梯度没什么用。你必须真正理解这个网络在算什么,才能找到答案。

第一眼:这不是训练出来的
一位叫 Alex 的大学生决定试试这道题。他把模型加载进来,先看最后一层的权重:
import torch
import plotly.express as px
model = torch.load('./model.pt')
linears = [x for x in model if isinstance(x, torch.nn.Linear)]
px.imshow(linears[-1].weight.detach())
一看就知道这不是正经训练出来的网络。所有权重都是整数,而且是精心设计过的整数。这个网络是人手写的,不是梯度下降优化出来的。
最后一层是个 48x1 的矩阵,明显分成了三段。再看倒数第二层,它的权重似乎是同一段模式重复了三次,偏置则是同一个 16 字节的向量依次加 1、加 2。
Alex 很快意识到这个模式在做什么。倒数第二层配合 ReLU 激活函数,实际上是在检查两个 16 字节的整数是否相等。每个字节用一个神经元来比较,三个副本分别检查 v-x-1、v-x 和 v-x+1。最后一层的权重 1, -2, 1 组合这三个值,只有当 v 恰好等于 x 时才会输出 1。
这就像是设计了一个精密的锁,只有输入正确的 16 字节"钥匙",最后一层才会被激活。
问题变成了:这把锁在锁什么?
既然网络最后在检查一个特定的 16 字节值,那前面的所有层肯定是在计算什么东西,然后拿计算结果跟这个值比对。
这个网络有 2500 多个线性层。Alex 开始逐层追踪,想找出每部分在算什么。但很快发现这是个体力活,网络结构太复杂了,手动画图追踪根本搞不定。
他换了个思路:把整个网络看作一个线性规划问题来求解。
ReLU 激活函数本身不是线性的,但可以引入一个整数变量来建模。如果某个神经元的激活值是负数,ReLU 会把它变成 0,那就可以用一个布尔变量来表示"这个神经元被截断了吗"。这样一来,整个网络就变成了一个混合整数线性规划(MILP)问题。
听起来很美好,实际跑起来是个灾难。网络有几百万个变量,整数规划求解器跑了一天也没出结果。
网络瘦身:砍掉 80% 的废节点
Alex 发现这个网络有个特点:大部分神经元什么都没干。
具体来说,如果一个神经元的输入只有一条边,权重恰好是 1,那它本质上就是把前一个神经元的值原封不动传过来。这种节点可以直接合并掉。
还有一些更复杂的简化规则。比如一个神经元的所有输入权重都是正数,那 ReLU 对它就没影响,永远不会被截断,可以直接把它的输入连到它的输出。又比如同一层里有两个神经元接收完全相同的输入,它们也可以合并。
一轮轮简化下来,网络从 200 万个节点缩到了 75,000 个。这是个巨大的进步,但求解器还是跑不动。
从线性规划到 SAT 求解器
节点数量还是太多,Alex 又想到一招:传播边界值。
从输入层开始,一层层往下推算每个神经元可能取的最大值和最小值。很多神经元经过这种分析后,取值范围变得非常窄,比如只能取 0 或 1。
既然很多变量只能取布尔值,不如直接转成 SAT 问题。每个神经元在每个可能取值上对应一个布尔变量,层与层之间的关系变成布尔约束。
转化后大约有 20 万个布尔变量。SAT 求解器跑了一天,把问题简化到 2 万个变量,然后就卡住了。核心程序还是太复杂,没法暴力破解。
灵光一现:这是哈希函数
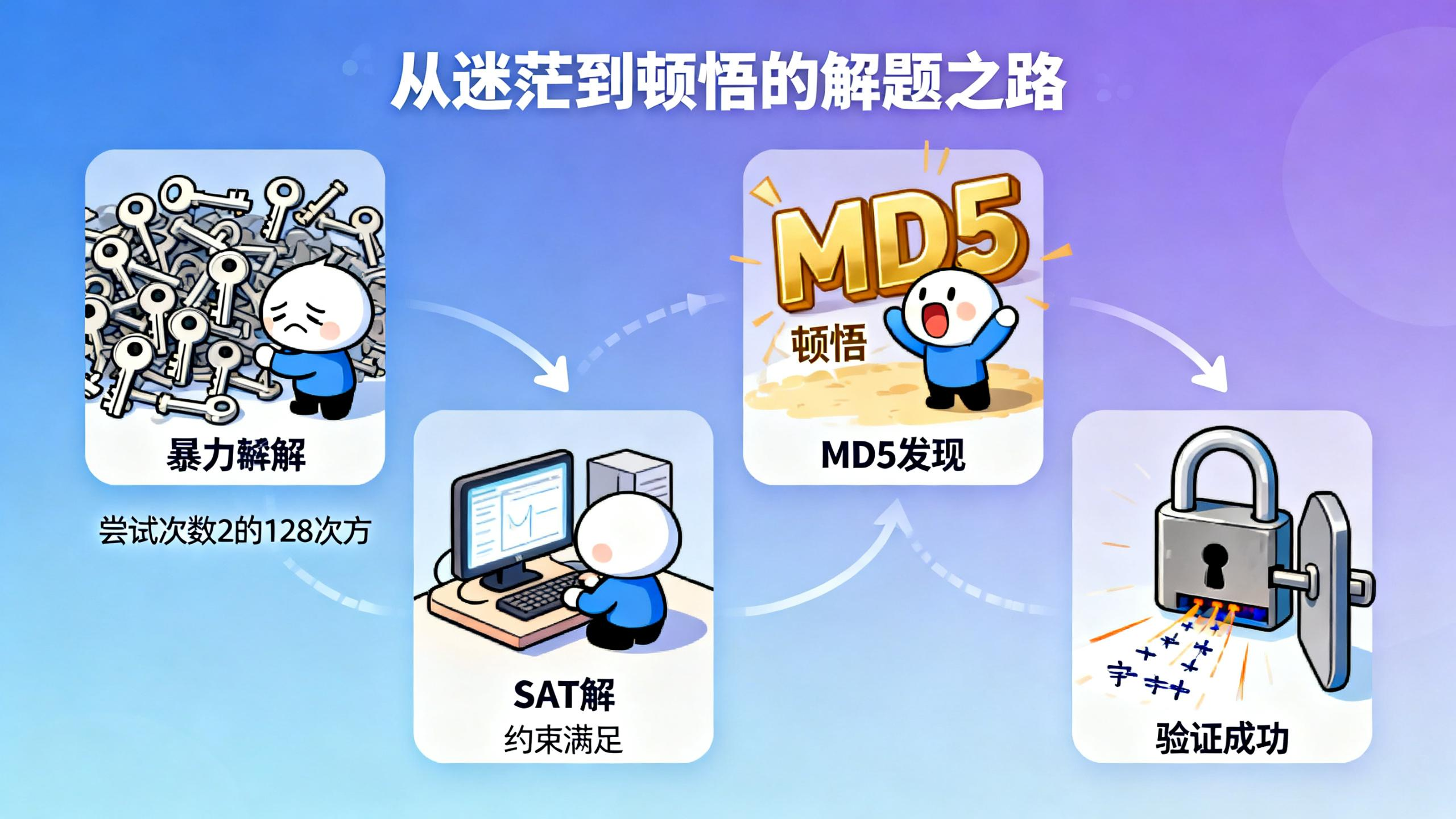
既然暴力求解走不通,Alex 换了个思路。这个网络是故意设计成这样的,那设计者肯定留了某种"后门"或者规律。
他注意到网络的层宽度呈现周期性变化:32 个周期,每个周期长度是 48。这种结构太规整了,不像是随机生成的。
什么算法会用 32 轮迭代,每轮处理 48 比特的数据?他问了问 ChatGPT,答案指向一个方向:哈希函数。
MD5、SHA-1、SHA-256 这些常见的哈希函数,都是通过多轮迭代来混淆数据的。Alex 开始逐个尝试,输入一个字符串,分别计算各种哈希值,然后跟网络倒数第二层的偏置对比。
答案揭晓:这个网络实现的正是 MD5 哈希函数。
哈希函数能逆向吗?
现在问题变得清晰了。网络的倒数第二层偏置编码了一个特定的 MD5 哈希值。你需要找到一个输入字符串,它的 MD5 哈希恰好等于这个值。
MD5 是单向函数,理论上没法逆向。但题目提示说答案是两个小写英文单词,中间用空格连接。这是一个重要的约束:搜索空间大大缩小了。
Alex 最初尝试用常用词表来暴力搜索,但前 10,000 个高频词里没有答案。他换了一个更大的词表,终于找到了解。
答案是什么?Jane Street 没有公开,但解题思路本身比答案更有价值。
一个意外发现的 Bug
在解题过程中,Alex 发现了这个网络的一个 bug。
MD5 算法需要把输入消息的长度编码进数据里。这个网络用 4 个字节来存储长度,用的是小端序。问题是,当输入长度超过 255 字节时,编码方式出了错。
正确的编码应该是把长度值拆成 4 个字节,但网络直接把长度数值存进了第一个字节。这意味着长度超过 255 时,编码就错了。
Alex 花了两天时间逆向分析这个 bug,想看看能不能利用它来简化问题。结果发现这个 bug 是无意的,不是题目设计的陷阱,对解题也没有帮助。但这个分析过程本身展示了非常扎实的逆向工程能力。
为什么这道题值得做
Jane Street 为什么要出这样一道题?
表面上看是个好玩的智力游戏,实际上是在招人。能解出来的人,大概率具备以下能力:
理解神经网络的内部结构,而不只是会调 API。能把抽象的数学问题转化成具体的求解策略。在面对复杂问题时,知道什么时候该暴力求解,什么时候该寻找规律。有耐心追踪细节,发现异常。
Jane Street 的研究团队经常需要理解复杂模型的内部运作机制。这道题考察的正是这种"mechanistic interpretability"的能力。
如果你对这类问题感兴趣,Jane Street 后来又发布了第二道题:一个神经网络的层被打乱了顺序,需要你把它们排回正确的顺序。感兴趣的话可以去他们的 Hugging Face 页面试试。
小结
这道题的核心不是机器学习,而是逆向工程。网络的所有权重都给你了,没有秘密可言。但要从几百万个整数中看出一个 MD5 哈希函数的轮廓,需要的是分析能力和耐心。
传统的深度学习思路在这里派不上用场。梯度下降、反向传播、对抗样本,这些工具都失效了。你不得不回到更基础的方法:分析结构、简化问题、寻找模式。
这种能力在实际工作中也很有用。当你需要调试一个表现异常的模型,或者理解一个第三方库的内部逻辑时,用的就是类似的技能。
Jane Street 说得对:能解出这道题的人,大概率能在他们团队干得不错。解题过程暴露出来的那股较真劲儿,正是他们想要的。
常见问题
为什么不能用梯度下降来求解这个问题?
这个网络的设计很特殊。它内部使用了大量的 ReLU 激活函数,这些函数在负值区间梯度为零。当网络对几乎所有输入都输出 0 时,反向传播传回去的梯度基本全是零,没法用梯度下降来优化。你必须真正理解网络在算什么,而不是把它当成一个可微分函数来求导。
mechanistic interpretability 是什么?
简单说就是"打开黑盒看齿轮"。传统的机器学习研究关注模型的效果,而 mechanistic interpretability 关注模型内部的运作机制——每个神经元在算什么、层与层之间怎么配合。这个 Jane Street 的题目本质上就是在考察这种能力。
这种逆向工程技术有什么实际用处?
用处挺多的。比如你的模型在生产环境突然表现异常,你需要搞清楚是哪一层出了问题。或者你要审计一个第三方模型,确认它没有隐藏的后门。又或者你想做模型压缩,需要找出哪些神经元是冗余的。理解模型内部逻辑,比单纯调参要有价值得多。