把 400B 大模型塞进 48G 内存:LLM in a Flash 背后的魔法

最近有个视频在程序员圈子里疯传:有人在一台 48GB 内存的 MacBook Pro M3 Max 上,跑起了 Qwen3.5-397B-A17B——一个磁盘占用 209GB 的庞然大物,速度还能达到 5.5 tokens 每秒。
弹幕里一堆人问号脸:等等,48GB 怎么装下 209GB 的模型?
这个问题,Apple 三年前就回答过了。
01 论文的起源:把冰箱塞进小房间
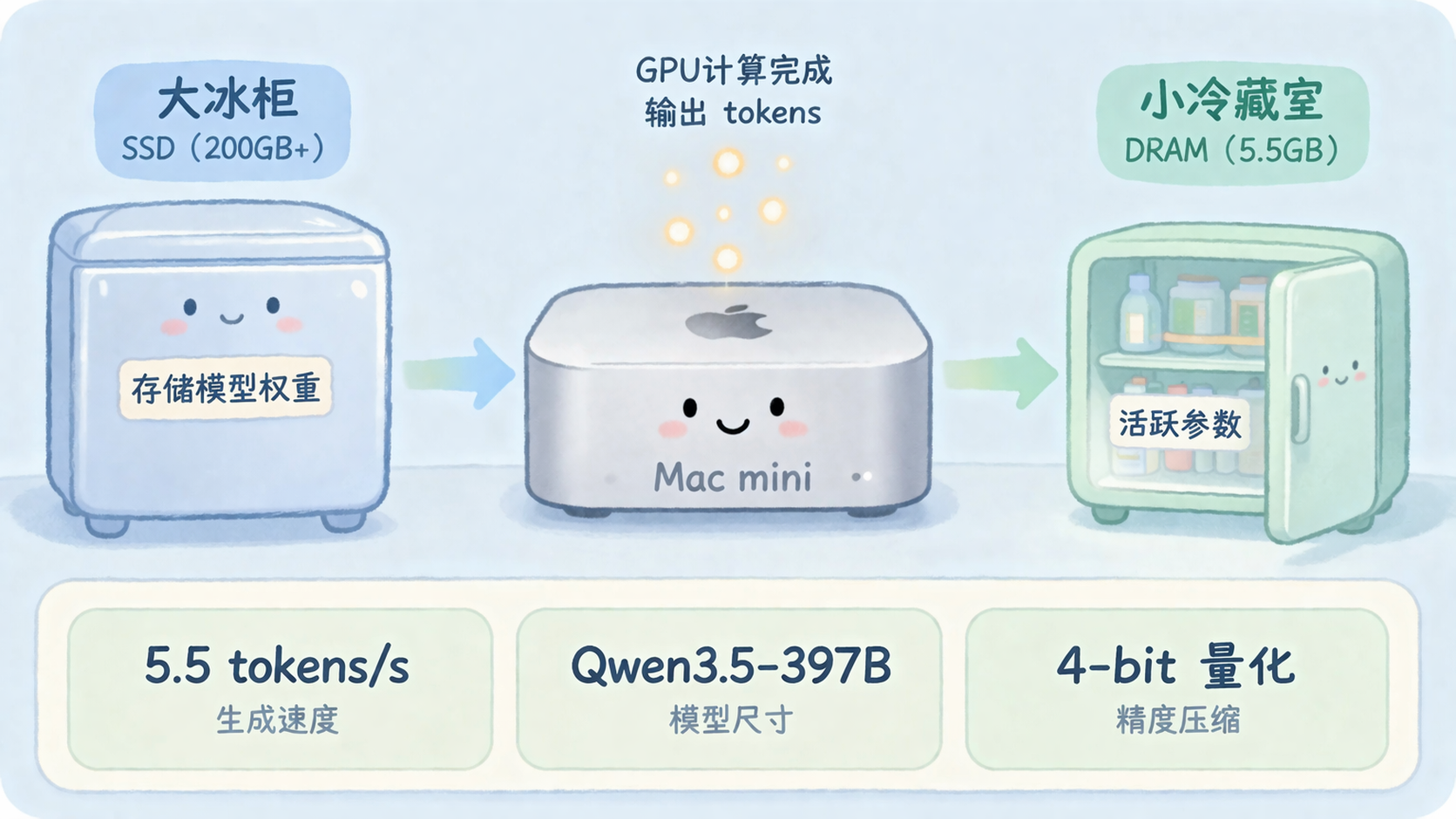
2023 年底,Apple 发了篇论文,名字叫《LLM in a Flash: Efficient Large Language Model Inference with Limited Memory》。核心思想就一句大白话:** DRAM 装不下,就用 SSD。**
你家 DRAM 是厨房的冷藏室,空间有限。SSD 呢,是旁边的大冰柜,容量大得多,但拿东西慢。传统方案是把所有食材(模型权重)都塞进冷藏室——塞不下就报错。
Apple 的思路反过来了:只把马上要用的那部分从冰柜里拿出来,用完再放回去。
论文还做了两件事:第一,算清楚从 SSD 读数据的成本,建立一个"数据搬运成本模型";第二,优化读取策略——要大块读、连续读,不要东一块西一块地随机读。SSD 顺序读的带宽比随机读高得多,这个特点被充分利用了。
Dan Woods 就是在这篇论文的基础上,把 Qwen3.5-397B-A17B 搬到了 Mac 上。
02 MoE 模型:不用全员上班
光靠 SSD 加速还不够。Dan Woods 能把 3970 亿参数的模型跑起来,关键靠的是 MoE(Mixture-of-Experts,混合专家)架构。
普通大模型(比如 GPT-3 175B)是全员上班制。每个 token 生成,都要动用全部 1750 亿个参数算一遍。人多力量大,但人多了也费粮。
MoE 不一样。它内部有多个"专家"——你可以理解成餐厅厨房里有好几个厨师。来了一个订单(token),不用全员下厨,路由层会决定派哪几个厨师去处理。
Qwen3.5-397B 里,正常情况下每处理一个 token 只会激活大约 10 个专家。这个比例大概是 1:8——原来要喂 3970 亿参数,现在实际参与运算的可能只有几百亿。
专家数量少,显存压力就小。最关键的是,专家权重可以按需从 SSD 读取——这个 token 需要这几位厨师,下个 token 换一批人,冰柜里的东西不用一次性全搬进来。
MoE 模型在端侧推理场景越来越火,原因就在这里:不是模型变小了,而是每次真正参与计算的部分变小了。
03 量化:给参数减肥的学问
有了 MoE 的"按需调用",还需要给参数本身减减肥。
Dan Woods 在实验里把专家权重从高精度(FP16)一路压到了 2-bit——相当于把每个参数从占用 2 个字节压缩到 0.25 个字节。压缩比接近 8 倍。
当然,减肥是有代价的。2-bit 量化会丢失一部分精度,影响模型输出的质量。更麻烦的是,实验到一半发现 2-bit 版本在 tool calling(工具调用)上出了问题——模型"手抖",调错了函数。
最终方案做了个折中:专家权重量化到 4-bit,非专家部分(比如 embedding 表和路由矩阵)保持原始精度。 这样常驻内存的部分只有 5.5GB 左右,剩下 200GB 以上的模型权重全放 SSD,按需流式读取。
最新版本的性能数据:209GB 模型文件,4.36 tokens/秒。 比你等 ChatGPT 响应快多了。
04 AI 帮 AI 做实验
整个研究过程最让人意外的地方,可能不是技术本身,而是实验是怎么完成的。
Dan Woods 把 Apple 的论文喂给了 Claude Code,然后用 Andrej Karpathy 提出的 autoresearch 模式——让 AI 自动跑实验、收集结果、调整参数、再跑。Claude 前后跑了 90 轮实验,最后产出了用于 MLX 框架的 Objective-C 和 Metal 代码,外加一篇由 Claude Opus 4.6 主写的 PDF 论文总结整个过程。
这就是 Andrej Karpathy 说的"Software 2.0"时代的味道:你描述目标,AI 在目标函数的空间里搜索最优解。 Dan Woods 本人只需要决定什么时候停下来。
05 这事对普通开发者意味着什么
现在回头看,最让人感慨的不是某个单点技术突破,而是整个技术链条的打通:
SSD 带宽越来越快,Apple Silicon 的统一内存架构让 GPU 和 CPU 共享大内存,MLX 框架把这一切封装好,加上 MoE 模型的结构性优化——这些因素凑在一起,才让"在笔记本上跑 400B 模型"从不可能变成了可能。
对于用 Mac 做开发的同学来说,这意味着:
- Coding Agent 可以跑更强的模型,不用一直盯着 API 调用次数
- 长上下文的成本可以进一步降低,本地跑完所有推理
- 隐私场景的天花板在抬高,代码和对话不需要离开你的设备
也许再过一两年,“在本地跑个几百B的模型"会成为理所当然的事,就像现在跑个 7B 模型一样。那时候大家讨论的问题,可能又是另一套了。
FAQ
Q: 我的 Mac 能跑这个吗? M3 Max(48GB 内存)起步。内存太小会严重影响速度,甚至跑不起来。
Q: 和 Ollama 比怎么样? Ollama 适合通用场景,LLM in a Flash + MoE 的方案在超长上下文和超大模型上有明显优势。
Q: 我自己怎么复现? GitHub 上有 danveloper/flash-moe 项目,支持 MLX 框架。不过需要一定的配置能力。
Q: 2-bit 和 4-bit 量化差别大吗? 在大多数任务上差别不明显,但在 tool calling 等精确任务上,4-bit 表现更稳定。