Cramming a 400B Model into 48GB: The Magic Behind LLM in a Flash

A video has been making the rounds in programmer circles: someone got Qwen3.5-397B-A17B—a beast weighing 209GB on disk—running on a MacBook Pro M3 Max with just 48GB of RAM. The speed? 5.5 tokens per second.
The comments section was full of question marks. How does 48GB hold a 209GB model?
Apple answered that question three years ago.
01 The Paper That Started It All: Fitting a Fridge in a Tiny Kitchen
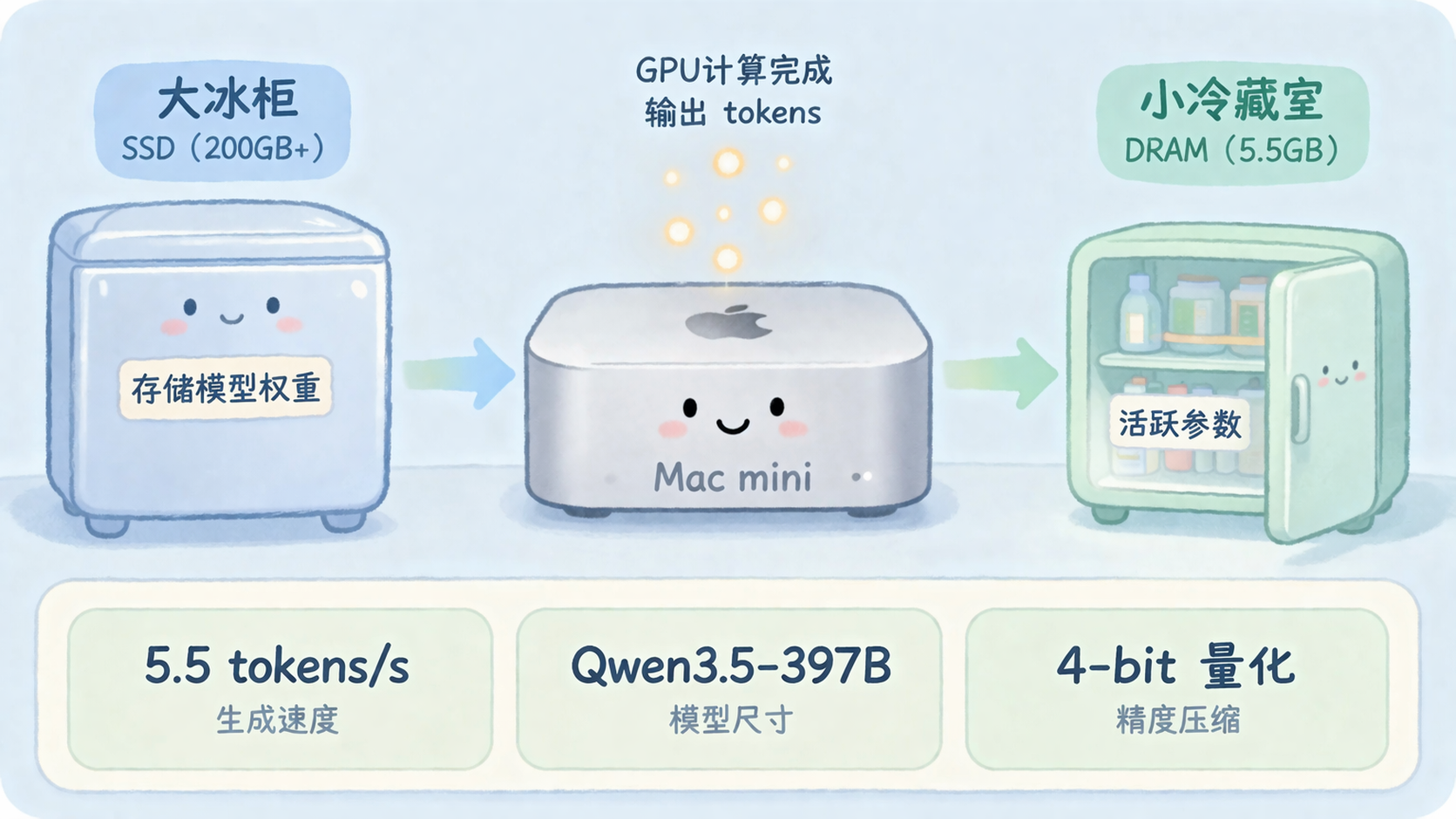
Late 2023, Apple published a paper titled “LLM in a Flash: Efficient Large Language Model Inference with Limited Memory.” The core idea in plain English: if DRAM can’t hold it all, use SSD.
Your DRAM is the fridge in your kitchen—limited space. The SSD? That’s the big freezer right next to it—much bigger, but slower to access. Traditional approaches tried to cram everything (the model weights) into the fridge. If it didn’t fit, crash.
Apple flipped the script: only pull from the freezer what you need right now, then put it back.
The paper did two key things. First, it modeled the cost of reading from SSD, building a “data搬运 cost model” to understand the trade-offs. Second, it optimized the read strategy—big chunks, sequential reads—avoiding scattered random access. SSD sequential bandwidth crushes random read performance, and the paper exploited that fully.
Dan Woods took Apple’s paper and ported Qwen3.5-397B-A17B to the Mac based on these ideas.
02 MoE Models: Not Everyone Punches In
SSD acceleration alone wasn’t enough. What let Dan run a 397 billion parameter model: MoE (Mixture-of-Experts) architecture.
Regular large models (like GPT-3 175B) run an all-hands-on-deck system. Every token generation touches all 175 billion parameters. More people, more power—but also more resources.
MoE plays it differently. Inside are multiple “experts”—think of a restaurant kitchen with several cooks. An order (token) comes in, and not everyone cooks. The router decides which few experts handle it.
In Qwen3.5-397B, each token typically activates only about 10 experts. That’s roughly a 1:8 ratio—the actual compute might involve a few hundred billion parameters instead of the full 397 billion.
Fewer active experts means less VRAM pressure. More importantly, expert weights can be loaded from SSD on demand—this token needs these cooks, the next token needs different ones. The freezer doesn’t need to empty everything at once.
That’s why MoE keeps gaining traction for on-device inference: the model didn’t shrink, only the actively-computed portion did.
03 Quantization: The Art of Weight Loss
After MoE’s on-demand loading, the weights themselves still needed trimming.
Dan pushed expert weights from FP16 down to 2-bit—roughly compressing each parameter from 2 bytes to 0.25 bytes. That’s nearly 8x compression.
But losing weight has costs. 2-bit quantization drops some precision, affecting output quality. Worse, during experimentation they found 2-bit broke tool calling—the model started “jittering,” calling the wrong functions.
The final compromise: 4-bit expert quantization, with non-expert components (embedding tables, routing matrices) kept at full precision. Active memory usage dropped to ~5.5GB, while the remaining 200GB+ of model weights stayed on SSD, streamed in on demand.
Latest performance numbers: 209GB model file, 4.36 tokens/second. Faster than waiting for ChatGPT to respond.
04 AI Helping AI Run Experiments
The most surprising part of this whole project wasn’t the technology—it was how the experiments got done.
Dan fed Apple’s paper to Claude Code and ran it through Andrej Karpathy’s autoresearch pattern—letting an AI automatically run experiments, collect results, adjust parameters, and repeat. Claude ran 90 rounds of experiments autonomously, eventually producing Objective-C and Metal code for the MLX framework, plus a PDF paper largely written by Claude Opus 4.6 documenting the whole process.
This is what Andrej Karpathy calls the flavor of the “Software 2.0” era: you describe the goal, and AI searches the objective function space for the optimal solution. Dan only had to decide when to stop.
05 What This Means for Everyday Developers
Looking back, the striking thing isn’t any single technical breakthrough—it’s the entire chain clicking together:
SSD bandwidth keeps climbing. Apple Silicon’s unified memory architecture shares large pools between CPU and GPU. The MLX framework wraps it all up. MoE’s structural optimizations do their part. Combine these, and running 400B on a laptop went from impossible to possible.
For developers using Macs:
- Coding Agents can run stronger models, without watching API call counts
- Long-context costs drop further, running all inference locally
- Privacy ceilings keep rising, code and conversations never leave your machine
In a year or two, “running a few hundred billion parameter model locally” will be ordinary—same as running a 7B model today. By then, the questions everyone asks will be something else entirely.
FAQ
Q: Can my Mac run this? M3 Max with 48GB minimum. Less RAM severely impacts speed, or simply won’t work.
Q: How does it compare to Ollama? Ollama is great for general use. LLM in a Flash + MoE clearly wins on very long contexts and very large models.
Q: How do I reproduce this? The danveloper/flash-moe project on GitHub supports MLX. That said, some configuration chops are required.
Q: How big is the gap between 2-bit and 4-bit quantization? On most tasks, not noticeable. On precise tasks like tool calling, 4-bit is noticeably more stable.