Mistral 3 Official Release: The Latest Work from Europe’s AI Giant
While OpenAI, Google, and Anthropic are fighting it out across the ocean, a contender in Europe has been quietly preparing a big move. On December 2, Mistral AI from the romantic city of Paris quietly launched its third-generation model family—Mistral 3.
This is not just a single model but a whole “model family” with 10 members. It ranges from lightweight versions that fly on your laptop to flagship versions that can arm wrestle with GPT-4, covering everything from edge devices to enterprise applications.
The most exciting part is that the entire Mistral 3 line comes as open-weight models. In practice, any developer can download them, modify them freely, and deploy them on their own servers without worrying about getting blocked. It is like open-sourcing a secret family recipe—AI suddenly feels within reach.

What Is Mistral 3?
Mistral 3 is not a single model but a complete family. The headliners this time are Mistral Large 3 and the Ministral series.
Mistral Large 3 is the flagship. It uses a sparse mixture-of-experts architecture with 675 billion total parameters but only activates 41 billion parameters per inference. Think of it as a panel of expert advisors where only the relevant few step in for each question—specialized yet efficient.
At its core, Mistral Large 3 supports a 256K context window—enough to digest a hefty book in one go. It handles text and also offers multimodal capabilities for images and audio. For language support, it is specially optimized for European languages (French, German, Spanish, Italian) and also supports Arabic and Chinese.
Together with the Ministral series, the Mistral 3 family spans parameter sizes from 3B, 8B, 14B up to 675B, and each size comes in base, instruct, and reasoning variants. This flexibility lets developers choose exactly the right fit for their needs.
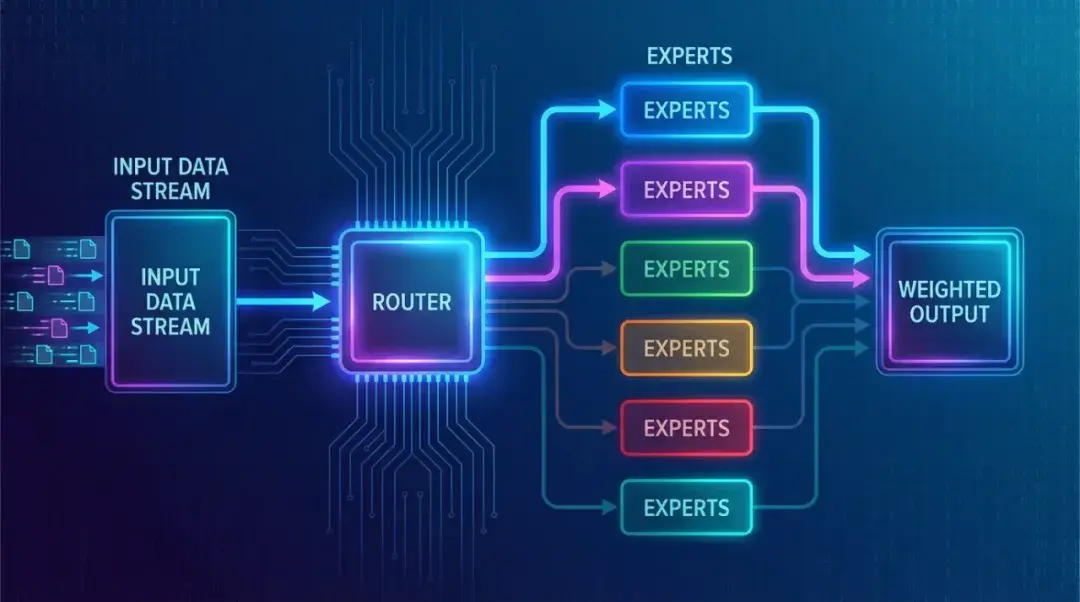
Sparse MoE Architecture: The Efficiency Trick
The core innovation of Mistral Large 3 is its sparse Mixture of Experts (MoE) architecture. It sounds complex, but the idea is straightforward.
Imagine working at a big consulting firm with top experts across finance, law, and tech. For each client problem, you would not bring everyone into the meeting—that wastes time and money. Instead, a “router” picks the 3–5 experts best suited to the question.
That is how the MoE setup works. The model contains multiple expert networks, each skilled at different tasks. When you ask a question, a routing system selects the best experts and only activates those to respond.
This design slashes compute, improves adaptability, and scales well:
- The total parameter count is huge, but only a small portion runs each time
- Different tasks can mix and match the experts they need
- Capacity can grow by adding experts without linearly increasing compute
Mistral was early to apply MoE in open-source large models. From the pioneering Mixtral series to today’s Mistral Large 3, the French team keeps proving that clever architecture lets smaller models punch above their weight.
Performance: A New Open-Source Benchmark
Enough theory—how does it perform?
Mistral Large 3 ranks among the top open-source non-reasoning models on the LMArena leaderboard. That might not sound flashy until you realize it is trading blows with closed models from giants like OpenAI and Anthropic.
Digging deeper, Mistral Small 3.1 scores 80.6% on MMLU and 88% on the HumanEval coding benchmark. For multilingual understanding, it averages 71% accuracy, beating many peers. Mistral Medium 3 hits 77.2% on MMLU Pro and an impressive 92.1% on HumanEval.
Costs matter too. Mistral’s own numbers show Mistral Medium 3 reaching over 90% of Anthropic’s Claude 3.7 Sonnet performance on benchmarks at a much lower price. That value proposition is especially attractive for indie developers and startups.
As an open-weight model, Mistral 3 also brings control. Companies can deploy it on their own servers, avoid data privacy concerns, and sidestep API limits. For finance, healthcare, and government teams with strict data requirements, this is a big deal.
The Ministral Series: AI at the Edge
Beyond the flagship, Mistral 3 introduces another key innovation: the Ministral series.
This lineup includes nine small models ranging from 3B to 14B parameters. Do not let the size fool you—they can run on laptops, smartphones, and even drones without needing a network connection.
Why does “edge AI” matter? Picture a factory where robots must spot part defects in real time. If every image had to be sent to the cloud and back, latency would kill throughput. With local AI, the robot decides in milliseconds.
Ministral 14B clocks 79.4% on MMLU and about 74% on multilingual understanding. The smaller 8B and 3B versions beat Google’s Gemma and Meta’s Llama models of similar sizes in Mistral’s tests.
Another highlight: these small models are multimodal. They handle text and vision, so you could run a phone-based assistant that understands your photos and the scenes you capture, offering suggestions entirely on-device—saving data and protecting privacy.
New Possibilities for Open AI
Mistral 3 is more than a product update. It shows that open models can rival closed giants, that smart design lets compact models do big-model work, and that AI can move to the edge instead of living only in the cloud.
For developers and businesses, Mistral 3 widens the menu. You do not need to hand data to a cloud provider or worry about API price swings or downtime. Download the model, deploy it on your servers, tune it as needed, and truly own your AI capabilities.
In a world where AI power is concentrating in a few hands, Mistral’s open stance feels refreshing. It is a reminder that progress does not have to mean closed walls—openness and cutting-edge performance can coexist.
OpenCSG community: https://opencsg.com/models/AIWizards/Ministral-3-3B-Base-2512
HF community: https://huggingface.co/mistralai/Ministral-3-3B-Base-2512
About OpenCSG
OpenCSG is a leading global open-source large-model community platform focused on building an open, collaborative, and sustainable ecosystem. AgenticOps is an AI-native methodology proposed by OpenCSG and serves as both the best practice and the guiding framework for Agentic AI. The core product, CSGHub, offers one-stop hosting, collaboration, and sharing for models, datasets, code, and AI applications, with industry-leading model asset management plus multi-role collaboration and efficient reuse.