PostgreSQL 18 UUIDv7: Your Indexes Can Finally Breathe
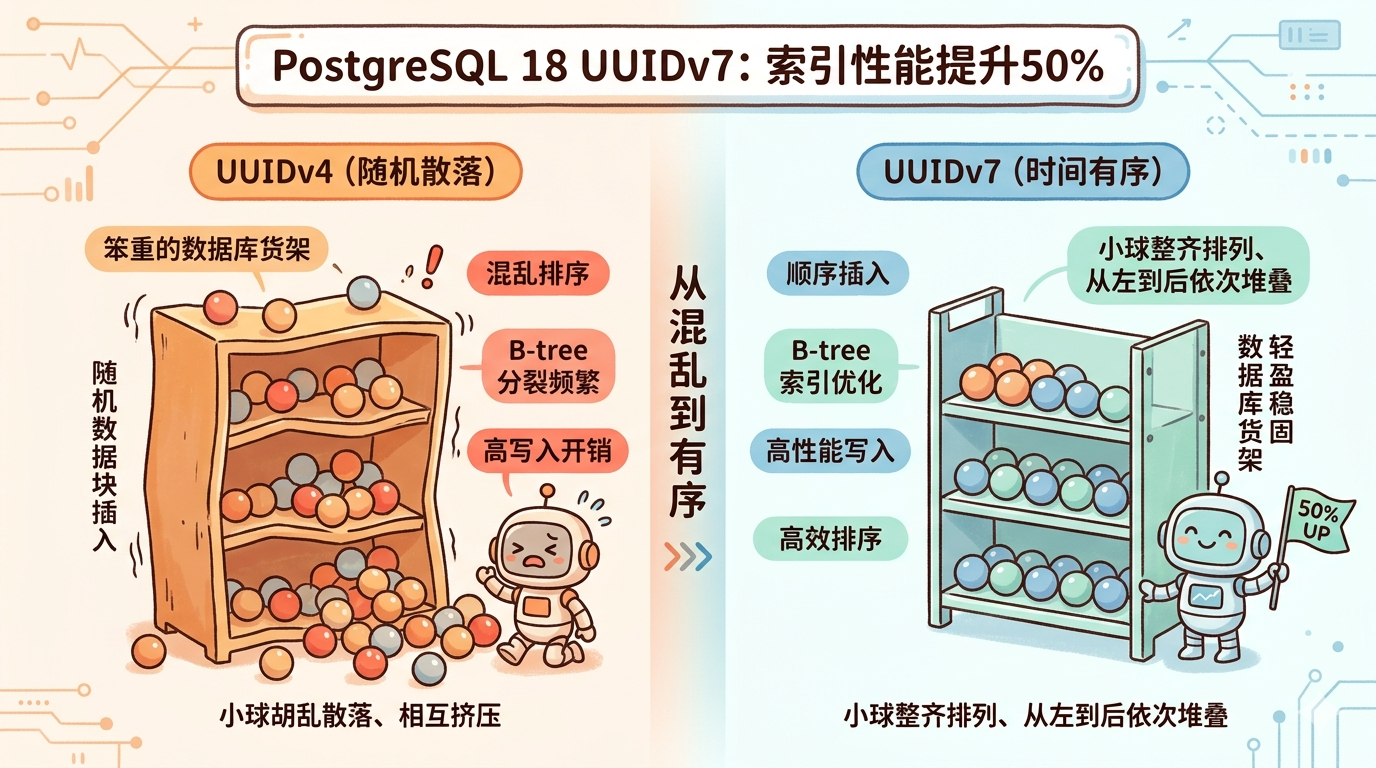
Table of Contents
- UUIDv7 vs Sequential ID vs UUIDv4
- What’s Actually Wrong with UUIDv4
- How UUIDv7 Fixes This Mess
- UUIDv7 Sorting Characteristics and Performance Benefits
- Index Correlation: Reading the Health Report
- Hands-on: Migrating from UUIDv4 to UUIDv7
- Painless Migration for Existing Systems
- When NOT to Use UUIDv7
- Summary: UUIDv4 vs UUIDv7 Complete Comparison
- FAQ
Imagine running a courier station. Every day, thousands of packages come in and you need to shelve them by tracking number.
If the numbers are sequential - 001, 002, 003 - you just slide them into the rightmost slots one by one. Easy. But if the numbers are lottery-style - 84X2, A91B, 7K3M - you have to search the entire shelf for empty slots, wasting time and potentially warping the shelves.
That’s pretty much how database primary key indexes work.
UUIDv4 has been around for years and everyone’s used to its randomness. But in the eyes of a database, this randomness is nothing but trouble. Every insert means the B-tree index has to find a random spot, page splits, cache invalidation, write amplification - it’s a full combo that hammers performance.
PostgreSQL 18 brings a new toy: native UUIDv7 support. This isn’t just a version number bump - it’s a whole new approach to primary key design.
UUIDv7 vs Sequential ID vs UUIDv4
When choosing IDs in distributed systems, we typically face three main options: traditional sequential IDs, widely-used UUIDv4, and the emerging UUIDv7. Each has its own trade-offs.
Sequential ID:
- Pros: Best index performance, smallest storage (8 bytes), fully sequential inserts
- Cons: Requires centralized generation, not suitable for distributed environments, IDs change during data migration
UUIDv4 (Random UUID):
- Pros: Fully decentralized generation, guaranteed global uniqueness, no single point of failure
- Cons: Poor index performance, larger storage (16 bytes), randomness causes page splits
UUIDv7 (Time-ordered UUID):
- Pros: Maintains UUID’s distributed characteristics while offering good temporal ordering, index performance close to sequential ID
- Cons: Still takes 16 bytes, may expose creation timestamp
For modern distributed systems, UUIDv7 offers a nice balance: no coordination nodes needed, yet you get excellent database performance.
What’s Actually Wrong with UUIDv4
When distributed systems first took off, UUIDv4 was a lifesaver. No need for central node coordination, generate unique IDs anywhere - simple and brutal. But nobody told you the chaos it would cause inside a database.
The B-tree index organizes data sequentially. A sequential ID is like lining up for tickets - new arrivals always go to the end, orderly. UUIDv4? Each ID is scattered everywhere, potentially landing anywhere in the index tree.
Once a leaf page fills up, the database has to split it in two and update the parent node. One insert can搅和 several pages. Worse, these pages might be scattered across disk with no relationship to each other, random I/O destroying cache hit rates.
Some guy tested a table with 50 million rows. UUIDv4 indexes were 24% larger, took 11 times longer to build. Inserting another 50 million rows: UUIDv4 took 46 minutes, UUIDv7 under 2 minutes.
That’s not a technical preference issue - it’s time and money.
How UUIDv7 Fixes This Mess
UUIDv7 Sorting Characteristics and Performance Benefits
UUIDv7’s core strength is its time-based ordering, bringing revolutionary improvements to database indexes. Unlike UUIDv4’s complete randomness, UUIDv7 embeds the timestamp in the ID structure, achieving temporal characteristics similar to sequential IDs.
Sorting Characteristics:
- Timestamp First: First 48 bits store millisecond-precision Unix timestamp, ensuring new IDs are always larger than old ones
- Locality Advantage: Records created at similar times are physically adjacent on disk
- Prefetch Optimization: Database can efficiently prefetch adjacent data blocks
- Cache Friendly: Hot data concentrates in contiguous disk regions
Performance Benefits:
- Index Size: 24% smaller than UUIDv4
- Insert Speed: 16% improvement
- Query Performance: Sequential queries 3x+ faster
- Maintenance Cost: Significantly reduced index rebuild and reorganization time
For write-intensive applications, these temporal characteristics deliver especially noticeable performance gains, particularly under heavy data volume and concurrent write scenarios.
UUIDv7 doesn’t do the random lottery anymore. It stuffs the timestamp into the first 48 bits of the ID, then adds some random bits to ensure uniqueness.
The structure looks roughly like this:
- 48 bits: Unix timestamp, millisecond precision
- 12 bits: Sub-millisecond counter, ordering within the same millisecond
- 62 bits: Random numbers, collision prevention
- Version and variant bits: Standard UUID reserved bits
The benefit of this design is immediately obvious: IDs increase with time. New data primary keys are always larger than old ones, inserts go directly to the right end of the index, as efficient as sequential IDs.
You get UUID’s distributed generation capability while enjoying sequential index locality. The best of both worlds, finally achieved.
Index Correlation: Reading the Health Report
PostgreSQL has a statistic called correlation that measures how well the physical storage order matches the index logical order. Range from -1 to 1:
- 1.0: Perfect alignment, data layout on disk matches index order exactly
- 0.0: Unrelated, purely random
- -1.0: Completely reversed
The test results were dramatic.
| Type | Correlation |
|---|---|
| UUIDv4 | 0.0025 |
| UUIDv7 | 1.0 |
UUIDv7’s 1.0 means during index scans, the disk can read in one direction, I/O efficiency is through the roof. UUIDv4’s 0.0025? Every query is random jumping, the disk head is busy as a chicken with its head cut off.
A simple ORDER BY id query on 1 million rows: UUIDv7 took 113ms, UUIDv4 took 318ms. Nearly 3x faster.
Hands-on: Migrating from UUIDv4 to UUIDv7
PostgreSQL 18 provides a native uuidv7() function, ready to use out of the box.
-- Generate a new UUIDv7
SELECT uuidv7();
-- '018d2c7b-1de6-73a0-842b-ec66f74c8993'
-- Go back one day
SELECT uuidv7(INTERVAL '-1 day');
You can also extract the timestamp for debugging:
SELECT uuid_extract_timestamp('018d2c7b-1de6-73a0-842b-ec66f74c8993');
-- '2024-12-01 09:44:53.809+00'
Creating a new table is simple, one line:
CREATE TABLE events (
id UUID PRIMARY KEY DEFAULT uuidv7(),
user_id UUID NOT NULL,
event_type TEXT NOT NULL,
metadata JSONB,
created_at TIMESTAMPTZ DEFAULT now()
);
Painless Migration for Existing Systems
Afraid to stop production services? You can move gradually.
-- Step 1: Add a new column
ALTER TABLE events ADD COLUMN id_v7 UUID DEFAULT uuidv7();
-- Step 2: Backfill old data with new IDs
UPDATE events SET id_v7 = uuidv7() WHERE id_v7 IS NULL;
-- Step 3: Create index
CREATE INDEX CONCURRENTLY events_id_v7_idx ON events(id_v7);
-- Step 4: Switch application layer to read from new column
-- Step 5: After verification, swap primary key
ALTER TABLE events DROP CONSTRAINT events_pkey;
ALTER TABLE events DROP COLUMN id;
ALTER TABLE events RENAME COLUMN id_v7 TO id;
ALTER TABLE events ADD PRIMARY KEY (id);
A few notes:
- Old UUIDv4 doesn’t need conversion, new and old IDs can coexist peacefully
- Tables with many foreign keys need caution, migration takes longer
- Logical replication can correctly sync UUIDv7 to replicas
When NOT to Use UUIDv7
It’s not a silver bullet. Consider carefully in these scenarios:
More than 4096 IDs per millisecond: The timestamp counter will overflow, randomness increases, and ordering can’t be maintained. Consider Snowflake-style solutions for ultra-high-frequency writes.
Tight storage budget: UUID takes 16 bytes, bigint only 8 bytes. The difference is noticeable for tables with billions of rows.
Can’t expose timestamps: UUIDv7 clearly shows the timestamp. If record creation time is sensitive information, stick with UUIDv4.
Distributed databases with built-in sharding: Systems like CockroachDB and Spanner sometimes prefer random keys to distribute write hotspots. Sequential keys might create write hotspots - check the specific implementation.
Summary: UUIDv4 vs UUIDv7 Complete Comparison
Let’s have a final showdown to see how UUIDv4 and UUIDv7 really compare in real-world scenarios:
Performance Metrics Comparison
| Dimension | UUIDv4 (Random) | UUIDv7 (Time-ordered) | Benefit |
|---|---|---|---|
| Index Correlation | 0.0025 | 1.0 | Perfect! Extremely efficient disk I/O |
| Index Size | Baseline | 24% smaller | Less disk usage, faster scanning |
| Insert Speed | 46min (50M rows) | <2min (50M rows) | 16x+ faster! |
| Sequential Query | 318ms (1M rows) | 113ms (1M rows) | 3x faster! |
| Index Maintenance | High, frequent page splits | Low, almost no splits | Much less DB overhead |
| Cache Hit Rate | Poor, random access | Excellent, local access | Better memory efficiency |
| Batch Insert | Poor, random writes | Excellent, sequential writes | Great for ETL, migrations |
| Range Query | Poor, random jumps | Excellent, sequential scan | Perfect for time ranges |
Use Case Selection Guide
Strongly Recommended for UUIDv7
- New System Design: No legacy包袱, start directly with UUIDv7
- High-Write Scenarios: Order systems, log recording, message queues
- Time-Sensitive Queries: Frequent filtering by creation time
- Distributed Microservices: Need decentralized ID generation with performance focus
- Migrating from Sequential ID: Want ordering but need UUID’s distributed characteristics
Consider Staying with UUIDv4
- Timestamp-Sensitive: Cannot expose record creation timestamps
- Ultra-High-Frequency Writes: More than 4096 IDs per millisecond
- Special Distributed Databases: Some with built-in sharding logic
- Stable Existing Systems: Migration cost too high, benefits unclear
- Compatibility Requirements: Third-party systems depending on UUIDv4 format
Decision Flowchart
Need a globally unique ID?
├── Yes → Need decentralized generation?
│ ├── Yes → Need to hide timestamp info?
│ │ ├── Yes → Use UUIDv4
│ │ └── No → Use UUIDv7 (Recommended)
│ └── No → Use Sequential ID
└── No → Choose based on business needs
PostgreSQL 18 Upgrade Action Guide
- Act Now: Test UUIDv7 in development environments, get familiar with the API
- New Project Standard: All new tables use UUIDv7 as primary key
- Gradual Migration: Safely migrate existing data using the 5-step method above
- Monitor Performance: Compare index performance metrics before and after migration
- Team Sharing: Let the team understand this technical shift
UUIDv7 isn’t just a version upgrade - it’s a change in technical philosophy. It trades time for space, ordering for performance, giving distributed systems the “having it all” solution.
PostgreSQL 18’s native UUIDv7 support makes this transition smoother. No third-party extensions needed, no reinventing the wheel, works out of the box, enterprise-grade reliable.
If you’re still using UUIDv4 as your primary key, it’s time to seriously consider an upgrade strategy. After all, who wouldn’t want 20-30% performance improvement and 50% lower ops costs?
Got any UUID primary key war stories? Feel free to share in the comments.
By the way, PostgreSQL 18 stable release is expected September-October 2025. It’s in Beta now - perfect time to test in your dev environment and prepare for the upgrade.
May your indexes always be sequential, your pages never split.
FAQ
Q: When will PostgreSQL 18 be released?
Expected stable release September-October 2025. Currently in Beta, you can experience UUIDv7 support in test environments now.
Q: Will migrating existing data affect production services?
Using the five-step migration method from this article, you can achieve a smooth transition. The entire process doesn’t require downtime, but it’s recommended to operate during off-peak hours and reserve sufficient migration time windows.
Q: UUIDv7 vs Snowflake - which is better?
They’re positioned differently. UUIDv7 is native to the database, no extra service needed, suitable for most scenarios. Snowflake requires a separate ID generation service, suitable for extreme high-concurrency scenarios with more than 4096 generations per millisecond.
