DeepSeek Drops a Bombshell: V3.2-Exp Sparse Attention Mechanism Debuts, API Prices Slashed in Half Again
Table of Contents
So yesterday (September 29th), the AI world exploded with another big piece of news - DeepSeek, our favorite “price slasher,” dropped another bombshell! This time they launched DeepSeek-V3.2-Exp, and you can tell from the name - this is experimental new architecture, a true technology pathfinder.
How Powerful Is This Upgrade? The Data Speaks Volumes
V3.2-Exp is truly a technological leap forward, with data that’ll make your eyes pop: 2-3x faster inference, 30-40% memory reduction, and 50% improvement in training efficiency. What does this mean?
It’s like if you used to run 5 kilometers in 30 minutes, now you only need 10-15 minutes, and you’re not even tired. What’s even better is that despite being so much faster, the quality hasn’t been compromised at all - performance on various public benchmarks remains on par with V3.1-Terminus.
DSA Sparse Attention: The AI World’s “Smart Filter”
The real killer feature of V3.2-Exp is the DSA (DeepSeek Sparse Attention) mechanism. If traditional attention mechanisms are like a micromanaging butler who processes every piece of information, then DSA is like a shrewd assistant who only focuses on what’s truly important.
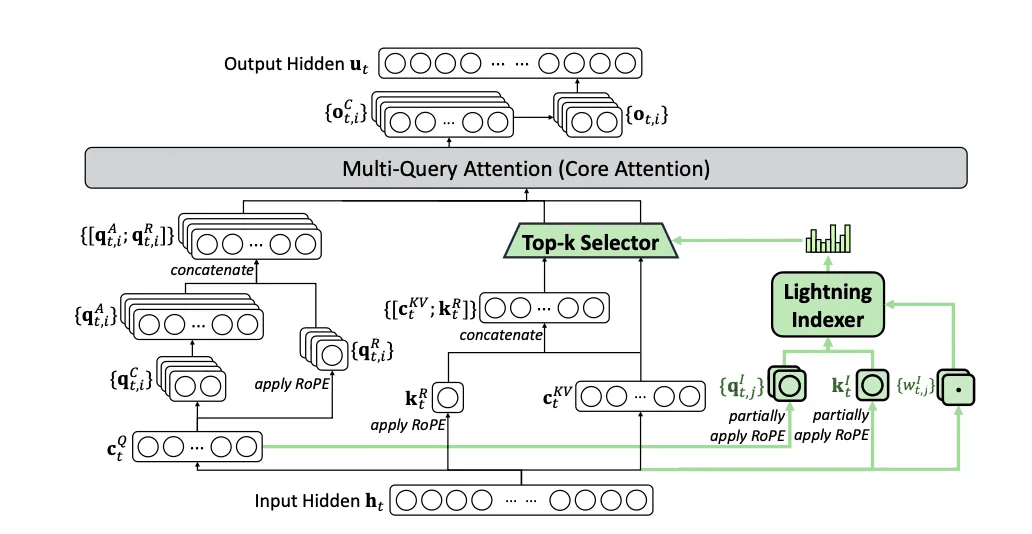
Imagine you’re reading a 300-page book. The traditional approach would be to carefully read every page, while DSA is like an experienced reader who can quickly identify which chapters are most important, skipping secondary content without missing key information.
DSA achieves fine-grained sparse attention - an industry-first technological breakthrough. Simply put: laser focus on what matters, skip what doesn’t, ensuring quality while dramatically boosting efficiency. This is the fundamental reason why V3.2-Exp can maintain performance while being so much faster.
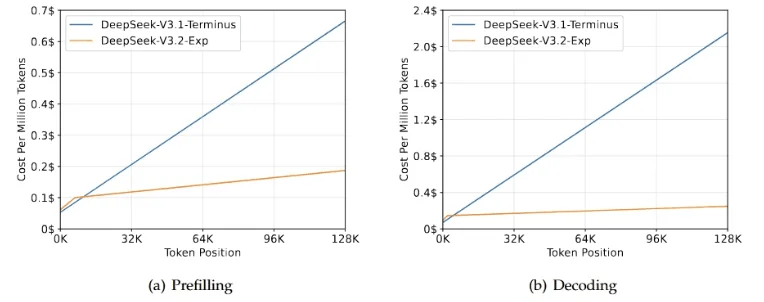
Prices Hit Rock Bottom Again: Another 50% Cut
The most exciting part is still the pricing - V3.2-Exp’s API prices have dropped by over 50%! Input costs are as low as $0.07/million tokens (with cache hits). What does this mean?

It’s like if a burger used to cost $30, now it’s only $15, and the burger actually tastes better too. For developers, this means you can do more with the same budget, or try projects that were previously too expensive.
This price advantage comes from two main sources: DSA sparse attention dramatically reduces computational costs, and the introduction of caching mechanisms reduces redundant calculations. Technological progress directly translates to cost advantages - this is the perfect embodiment of technological dividends.
Technical Architecture: A 671B Parameter Efficiency Beast
DeepSeek-V3.2-Exp is built on 671B parameters. This scale sounds massive, but the key is the efficiency improvement. It’s like a car engine - it’s not about displacement size, but about the balance between fuel consumption and power output.
More importantly, this brings a complete open-source ecosystem: MIT license open source, complete inference code, CUDA kernels, and multi-platform deployment solutions all available. It’s like a manufacturer not only selling you a car but also giving you the blueprints and repair manual - you can modify it however you want.
Showdown with Predecessor V3.1
The most direct comparison is with its predecessor V3.1-Terminus. In various public benchmark tests, V3.2-Exp performs on par with V3.1, but the efficiency improvement is revolutionary.
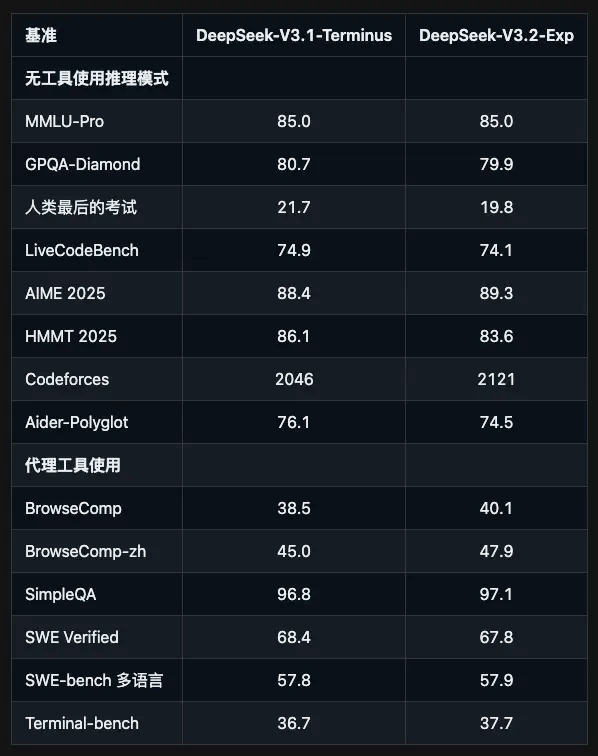
It’s like two students with similar test scores, but one took 3 hours while the other only needed 1 hour. While their scores are similar, the latter clearly has more potential. What’s more, DeepSeek thoughtfully kept the V3.1 API interface with consistent pricing, making it convenient for developers to run comparison tests - this service attitude is truly commendable.
The Significance of Open Source Ecosystem
V3.2-Exp has another major significance: complete open source. DeepSeek has opened up complete inference code, CUDA kernels, and multi-platform deployment solutions under the MIT license - meaning you can use it however you want.
What does this mean for developers?
- Further cost reduction: You can deploy it yourself without relying on API calls
- Technical control: You can adjust and optimize according to your specific needs
- Learning opportunities: You can see firsthand how the most advanced sparse attention mechanisms are implemented
- Ecosystem building: The entire community can build more innovations based on this technology
Final Thoughts
The release of DeepSeek-V3.2-Exp marks AI technology entering a new phase: no longer just competition on performance, but a revolution in efficiency. The breakthrough of DSA sparse attention mechanism shows us an important direction for AI technology’s future.
More importantly, DeepSeek has proven through action that top-tier AI technology can be both affordable and open source. This approach not only lowers the barrier for AI applications but also promotes technology adoption across the industry.
For developers, this is truly the best of times. Technical barriers are lowering, costs are dropping, and innovation opportunities are increasing. What remains is to see what kind of value we can create with these tools.
While V3.2-Exp is still experimental, the direction it shows is clear: more efficient, more open, more accessible. This might just be the future trend of AI technology development.
🔗 GitHub: https://github.com/deepseek-ai/DeepSeek-V3.2-Exp
🔗 HuggingFace: https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp
🔗 ModelScope: https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2-Exp
🔗 Paper: https://github.com/deepseek-ai/DeepSeek-V3.2-Exp/blob/main/DeepSeek_V3_2.pdf