Tokencake: Multi-Agent KV Cache Scheduling That Cuts vLLM Latency by Half
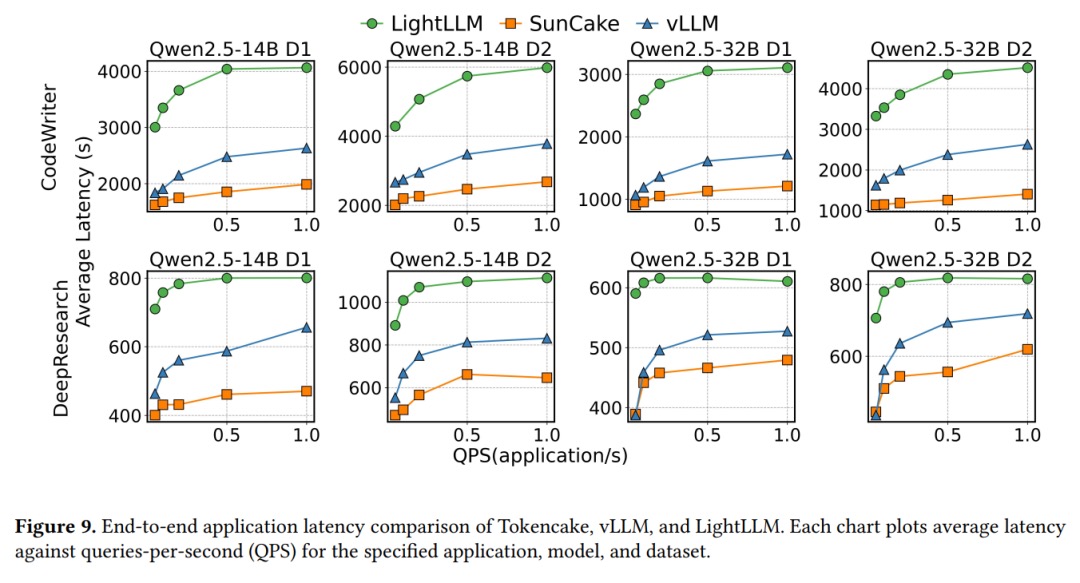
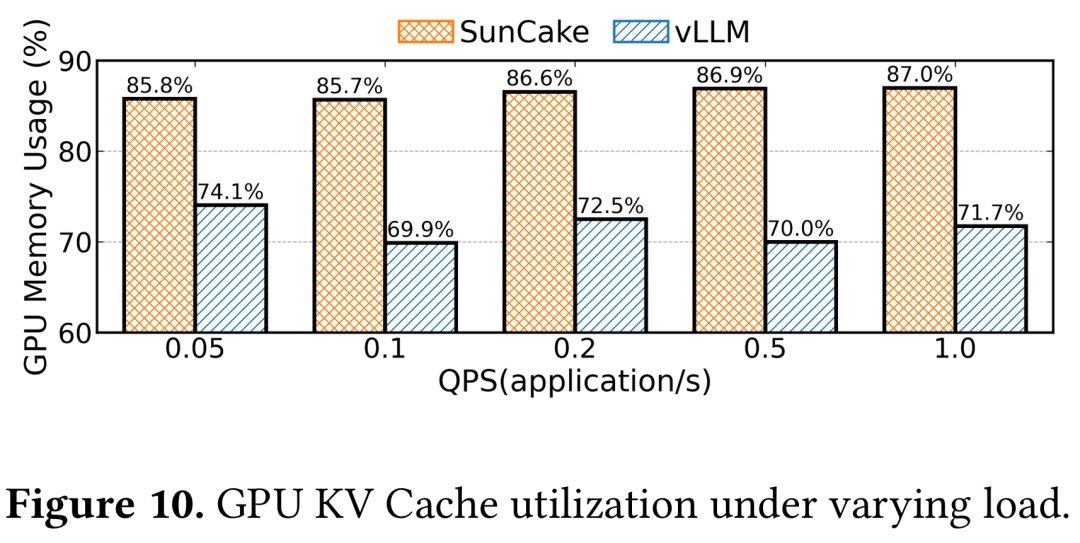
When multi-agents call external tools, GPU KV cache often feels like a shared fridge: someone waiting on delivery hogs half the shelves, while the chef who’s ready to cook can’t fit ingredients in, slowing everyone down. Tokencake’s answer is simple: move idle stuff to the hallway (CPU) and reserve shelf space for the VIP chefs. In benchmarks, that drops end-to-end latency to ~53% of vLLM and raises GPU cache utilization by 16.9%.

Quick sketch: how Tokencake works
- Model the workflow as a graph: The front-end API turns your multi-agent logic into a DAG (nodes are agents/tools, edges are message flows). Schedulers use this to know who’s critical and who can wait.
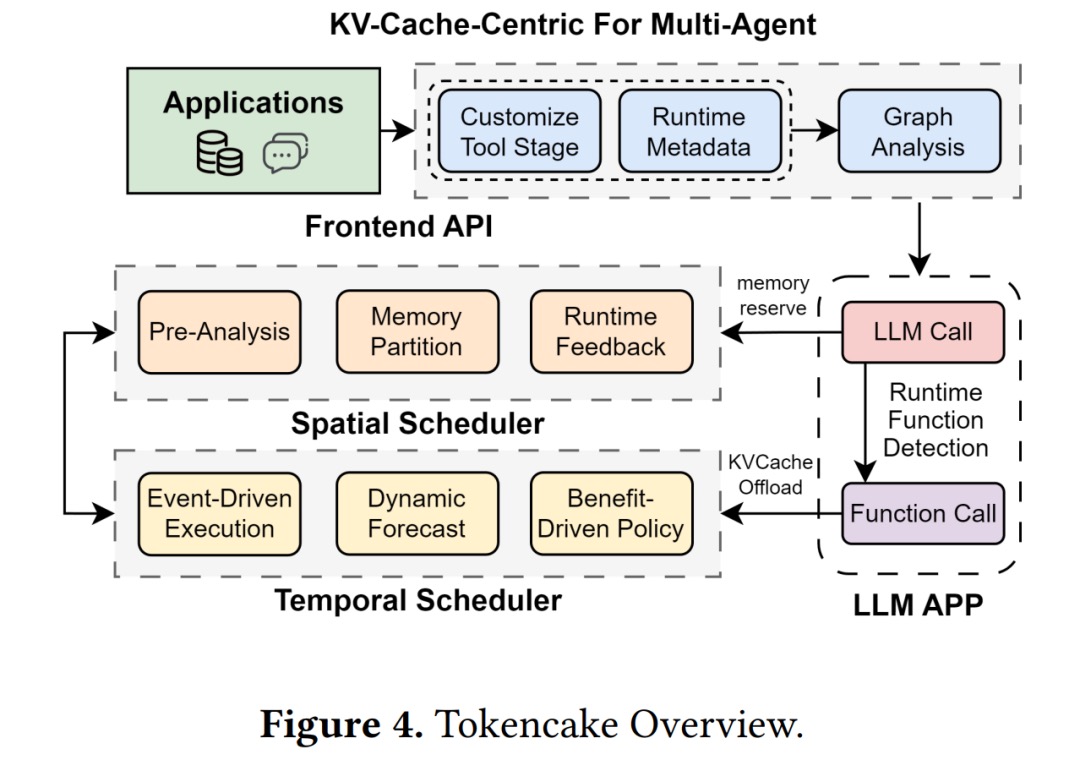
- Time scheduler: “waiting? offload first”: If an agent is blocked on a long tool/function call, unload its KV cache to CPU. When the return time is near (based on a prediction), prefetch it back to GPU—only if the expected gain beats transfer cost.

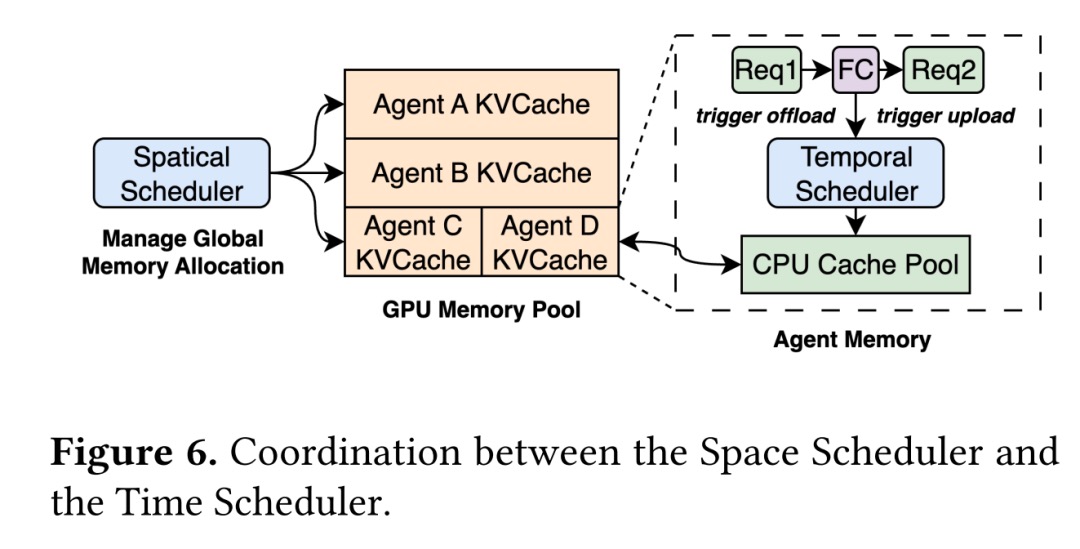
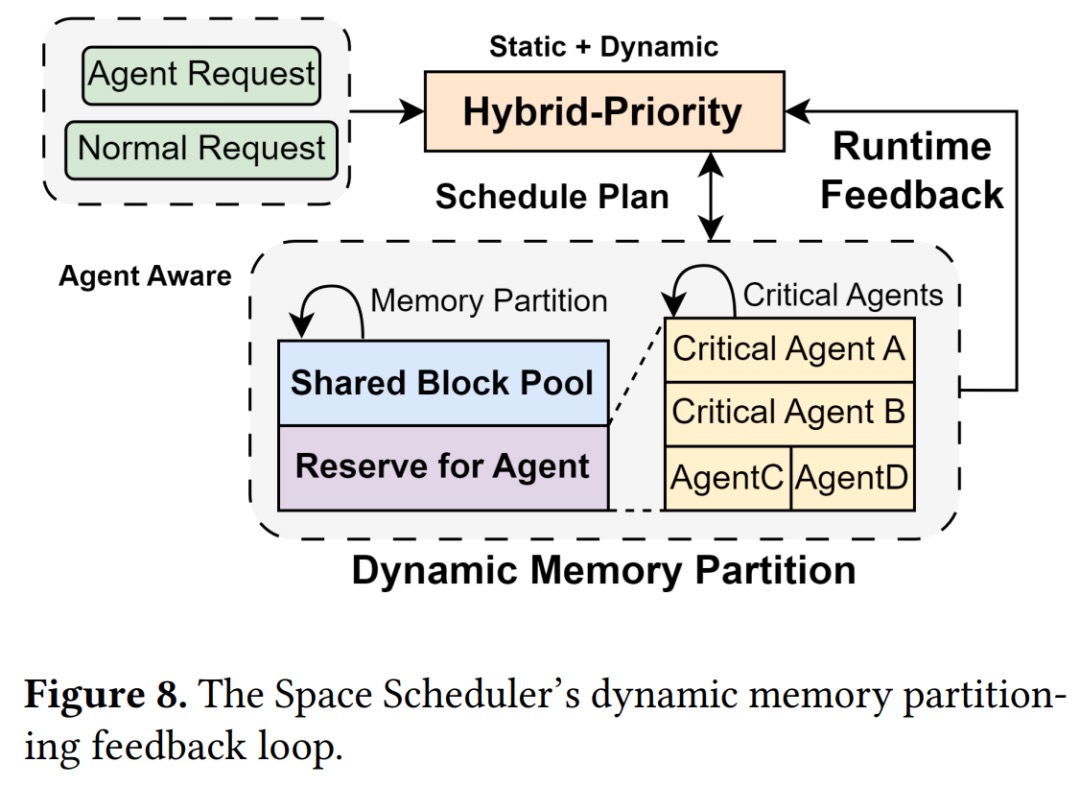
- Space scheduler: split GPU into two pools: A shared pool for everyone, and a reserved pool only for high-priority agents. Priority is a mix of “historical KV usage + business importance,” recomputed periodically.

- Two friction reducers: CPU-side block buffer (don’t return blocks to the OS; reuse them so large offloads stay sub-millisecond) and progressive GPU reservation (reserve in small chunks over several cycles to avoid one big blocking alloc).
- Results: On Code-Writer and Deep-Research workloads (ShareGPT + AgentCode requests, Poisson arrivals), end-to-end latency is 47%+ lower than vLLM at 1 QPS, and GPU KV utilization is up to 16.9% higher.

How to try it (minimal walk-through)
Step 1: Draw the agent graph
List agents/tools, message paths, and longest external-call durations. Mark “must-not-be-evicted” agents; this drives reserved pool sizing.Step 2: Add “offload while waiting” to your loop
Minimal simulation (Python 3.10+, stdlib only) showing offload during tool calls and prefetch before resume:
# tokencake_demo.py
import asyncio, random, time
GPU_BUDGET = 2 # pretend GPU fits only two KV caches
kv_pool = {}
async def external_call(agent: str) -> None:
await asyncio.sleep(random.uniform(0.8, 1.5))
def offload(agent: str):
kv_pool.pop(agent, None)
print(f"[{time.time():.2f}] offload {agent} -> CPU")
def load(agent: str):
if len(kv_pool) >= GPU_BUDGET:
victim = next(iter(kv_pool))
offload(victim)
kv_pool[agent] = "on-gpu"
print(f"[{time.time():.2f}] load {agent} -> GPU")
async def run_agent(agent: str):
load(agent)
print(f"[{time.time():.2f}] {agent} start tool call")
offload(agent) # move out while waiting
await external_call(agent)
load(agent) # prefetch back before decoding
print(f"[{time.time():.2f}] {agent} resume decode")
async def main():
await asyncio.gather(*(run_agent(f\"agent-{i}\") for i in range(3)))
asyncio.run(main())
Expected output (run python3 tokencake_demo.py):
[... ] load agent-0 -> GPU
[... ] agent-0 start tool call
[... ] offload agent-0 -> CPU
[... ] load agent-1 -> GPU
[... ] ...
Step 3: Reserve GPU for the VIPs
For mission-critical planners/reviewers, give a reserved fraction; others use the shared pool. Compute a 0–1 score from “historical max KV” + “business weight,” then allocate proportionally.Step 4: Observe under load
Track three things: real external-call latency distribution (feeds your predictor), GPU/CPU KV curves (if jittery, raise reserved ratio or slow the progressive steps), and whether transfers ever outweigh the gain (if yes, disable offload on those calls).
Traps and fixes
- Bad predictions: Start conservatively—only offload calls longer than P95; otherwise you’ll thrash.
- CPU buffer creep: Cap the buffer; above the cap, return blocks to the OS to avoid long-tail blowups.
- GPU partition thrash: Don’t swing
total_reserve_ratiotoo often; use high/low watermarks with a slow adjuster. - Blocking allocs: If progressive steps are too chunky, split them finer across more cycles.
- Only watching throughput: In multi-agent flows, watch latency components separately: “external wait,” “copy-back time,” “decode time.”
Wrap-up and next moves
- Tokencake pairs time-based offload with space-based reservation so idle KV cache stops hogging GPU during tool waits.
- CPU block buffering + progressive reservation tame allocation jitter, keeping ops in the sub-millisecond range.
- In 1 QPS high load, end-to-end latency is 47%+ lower than vLLM and GPU utilization is ~17% higher.
Next steps:
- Sketch your agent graph, mark longest external calls, set an offload threshold.
- Give the top 1–2 agents a reserved pool slice; watch whether your latency curve flattens.
- Read the paper for deeper tuning: https://arxiv.org/pdf/2510.18586