Just 'Know Python' on Your Resume? Hiring Managers Aren't Buying It in 2026

Table of Contents
- It’s 2026. You’ve Sent 100 Resumes That All Say “Proficient in Python.” How’s That Going?
- Why “Knowing Python” Became Table Stakes
- 1. Production-Grade Code: Can Your Code Survive the Real World?
- 2. Object-Oriented Design: Stop Memorizing Patterns, Learn When NOT to Use Classes
- 3. Data Handling: From “Can Read a CSV” to “Can Handle a Billion Rows”
- 4. API Development: Backend in 2026 Basically Means Building APIs
- 5. Cloud-Native: Writing Code Is Only Half the Job
- 6. AI Integration: You Don’t Need to Be a Scientist, but You Need to Be a General Contractor
- 7. Testing: Would You Ship Without a Safety Net?
- 8. DevOps and Automation: The Person Who Saves the Team Time Is Worth the Most
- 9. Collaboration: Git Is More Than Push and Pull
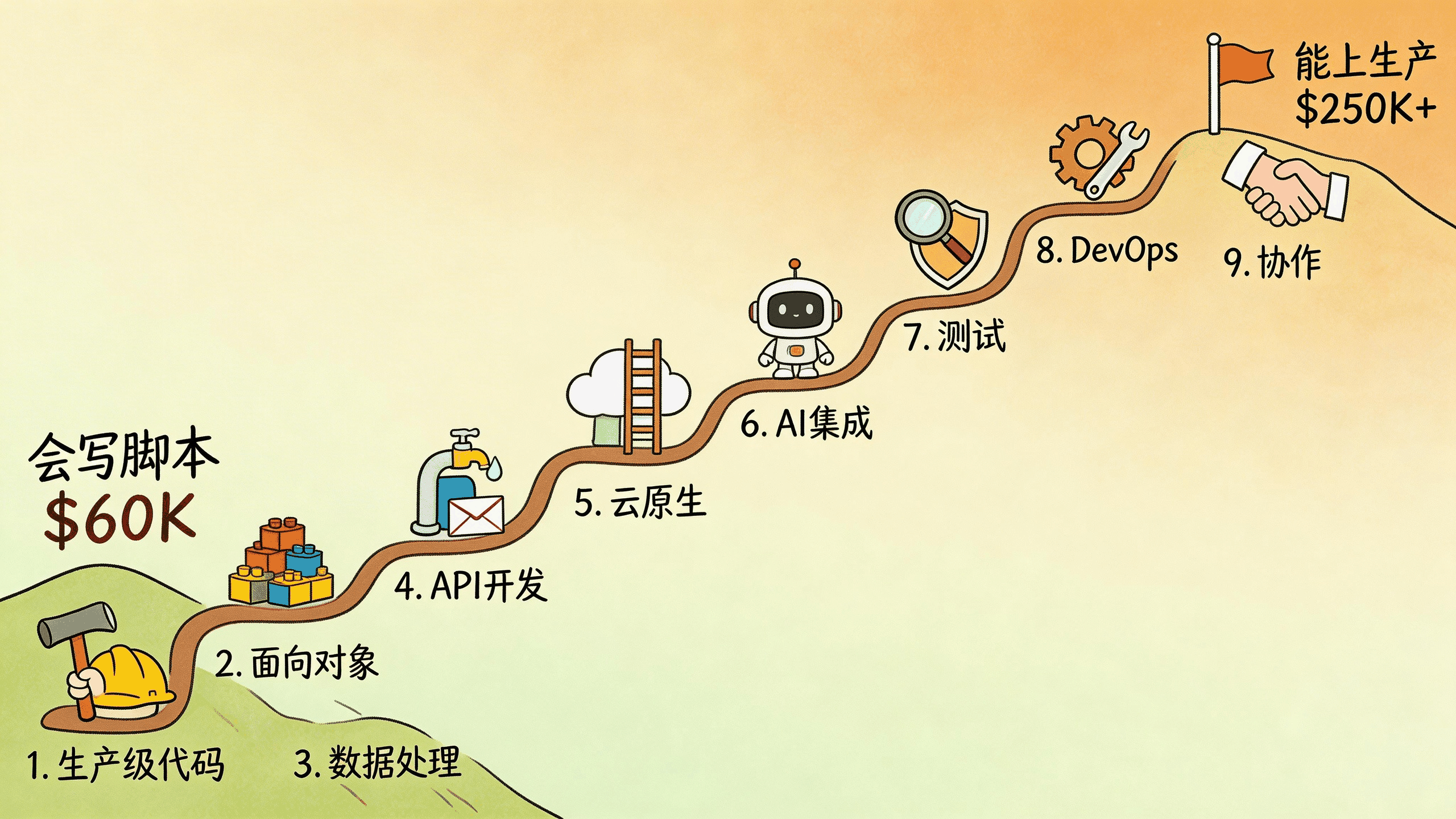
- Learning Roadmap: Four Phases From Zero to Interview-Ready
- Salary Reference: Your Specialization Sets Your Ceiling
- One Last Honest Take
- FAQ
It’s 2026. You’ve Sent 100 Resumes That All Say “Proficient in Python.” How’s That Going?
True story. A friend of mine switched careers last year and speed-ran Python in three months. Slapped “proficient in Python” on his resume and blasted it out to over a hundred companies. The result? Two interviews. Failed both at the first technical round.
He complained to me: isn’t Python the hottest language out there? Why is it so hard to land a job?
I took one look at his resume and GitHub. Every project was a “student management system,” a “web scraper for IMDB Top 250,” or a “Todo List.” The code ran, sure. But ask him to explain what the GIL is, when to pick asyncio over threading, or why you can’t debug production with print statements, and he’d go blank.
This is the reality of the 2026 Python job market: people who “know Python” are everywhere, but people who can actually build things with Python are still in high demand.
What’s the difference? Let me walk you through 9 areas, one by one.
Why “Knowing Python” Became Table Stakes
Here’s an analogy. Ten years ago, saying “I can drive” was a skill. Now? Pretty much everyone has a license. Say you can drive and the recruiter won’t even look up. What they want to hear is: can you handle highway driving? Would you drive in a storm? Do you know how to change a tire on the shoulder?
Python is the same deal. According to 2026 hiring data, Python developer salaries in the US range from $99K to $212K. That range is massive because “Python developer” is too vague a label. The person writing scripts to rename files is a Python developer. The person designing distributed AI inference pipelines is also a Python developer. 3x salary gap, and the skill gap is way more than 3x.
Interviewers stopped asking “do you know Python?” a long time ago. They want to know what you can ship with Python, whether your code can survive production traffic. If 10,000 users hit your API at once, does it hold up or fall over?
The 9 areas below are the upgrade path from “can drive” to “race-ready.”
1. Production-Grade Code: Can Your Code Survive the Real World?

Most people’s Python code is like a college class project – it demos fine, but it can’t take a hit.
Where’s the difference? A few details:
Type hints aren’t decoration. Python is dynamically typed, but in large projects, code without type hints is like a highway with no signs. You think it’s crystal clear when you write it. Your teammate who inherits it wants to throw their keyboard.
# Three months later, even you won't understand this
def process(data, flag):
if flag:
return data.split(",")
return len(data)
# Intent is obvious at a glance
def process_input(data: str, should_split: bool) -> list[str] | int:
if should_split:
return data.split(",")
return len(data)
Error handling means more than wrapping everything in try/except. The worst code I’ve seen is an entire function wrapped in try/except: pass. Something breaks? Silently swallowed. Logs are spotless. Then production goes down and debugging feels like finding a black cat in a dark room.
Production-grade means building exception hierarchies, using context managers for resources, and replacing print with structured logging:
import logging
from contextlib import contextmanager
logger = logging.getLogger(__name__)
@contextmanager
def database_connection(config: dict):
conn = None
try:
conn = create_connection(config)
yield conn
except ConnectionError as e:
logger.error("Database connection failed", extra={
"host": config.get("host"),
"error_type": type(e).__name__
})
raise
finally:
if conn:
conn.close()
Don’t hardcode your config. Putting database passwords in source code sounds like a joke, but companies make the news for this every year. Use Pydantic Settings for configuration management, separate environment variables by environment. That’s baseline.
Companies care about this because the code running fine on your laptop might blow up on a server due to memory leaks, race conditions, or unhandled edge cases. Understanding Python’s memory model, GIL limitations, and when to use asyncio vs. multiprocessing – that’s where the real value is.
2. Object-Oriented Design: Stop Memorizing Patterns, Learn When NOT to Use Classes
There’s an old joke in the Python community: Java developers who switch to Python still write Java-style code – classes everywhere, inheritance chains for days.
Interviewers actually care a lot about whether you can tell when a class is appropriate and when it isn’t. A simple data container? dataclass is enough, no need for a full class. A class with a single method? Usually cleaner as a function.
What you actually need to master:
Composition over inheritance. Inheritance chains more than two levels deep turn maintenance into Russian nesting dolls. Use Protocol to define interfaces, use dependency injection to assemble behavior:
from dataclasses import dataclass
from typing import Protocol
class Notifier(Protocol):
def send(self, message: str) -> None: ...
@dataclass
class SlackNotifier:
webhook_url: str
def send(self, message: str) -> None:
# Send to Slack
...
@dataclass
class OrderService:
notifier: Notifier # Injected, not inherited
def place_order(self, order_id: str) -> None:
# Order processing logic
self.notifier.send(f"Order {order_id} created")
Know your dunder methods. __repr__ saves you during debugging, __eq__ makes comparisons meaningful, __enter__ and __exit__ automate resource management. These aren’t party tricks – they’re real engineering skills.
The test is simple: hand someone a 500-line script. Can they refactor it into modular, testable components without creating a “god class” that does everything?
3. Data Handling: From “Can Read a CSV” to “Can Handle a Billion Rows”
Most Python tutorials teach data handling starting with pd.read_csv("data.csv"). Works fine with small data. But what happens when your file is 10 GB? Your machine locks up.
The 2026 data handling stack has evolved:
Polars has arrived. A DataFrame library written in Rust with multi-core parallelism, 5 to 10x faster than Pandas. The same group-by aggregation on 1 GB of data takes Pandas 4.6 seconds and Polars just 1 second. Lower memory usage too, thanks to Apache Arrow’s columnar storage under the hood.
import polars as pl
# Polars lazy evaluation - describe operations first, execute all at once
result = (
pl.scan_csv("huge_dataset.csv")
.filter(pl.col("amount") > 1000)
.group_by("category")
.agg(pl.col("amount").mean().alias("avg_amount"))
.sort("avg_amount", descending=True)
.collect() # This is when it actually runs
)
Data validation can’t wait until something breaks. Use Pydantic or Pandera to define schemas. Catch dirty data the moment it enters your system, not three days later when someone notices the reports don’t add up.
SQL isn’t optional. ORMs are handy, but they shouldn’t be your excuse to skip learning SQL. Complex queries, index optimization, query plan analysis – the ORM can’t help you there. SQLAlchemy 2.0 is the current standard.
ETL pipelines are a must. Apache Airflow, Prefect, Dagster – these tools turn data processing into monitorable, retryable workflows. The days of running one-off scripts to process data at your company are over.
4. API Development: Backend in 2026 Basically Means Building APIs
Modern backend development, stripped down to its essence, is building APIs. A request comes from the frontend, you return JSON. A request comes from mobile, you return JSON again.
FastAPI is the industry standard now. Async support, auto-generated OpenAPI docs, Pydantic data validation out of the box. Flask still works, Django fits large monoliths, but new projects pick FastAPI nine times out of ten.
from fastapi import FastAPI, HTTPException, Depends
from pydantic import BaseModel
app = FastAPI()
class UserCreate(BaseModel):
username: str
email: str
@app.post("/users", status_code=201)
async def create_user(user: UserCreate):
# Pydantic validates the request body automatically
# Bad email format? Returns 422 before your function even runs
existing = await find_user_by_email(user.email)
if existing:
raise HTTPException(status_code=409, detail="Email already registered")
return await save_user(user)
But CRUD skills alone won’t cut it. Interviewers will also ask:
- How do you handle auth? How does JWT token refresh work? Can you diagram the OAuth2 authorization code flow?
- 10,000 concurrent requests hit your service. What’s your rate limiting strategy?
- Your service goes down. How much damage does that cause upstream and downstream? What do you know about circuit breakers?
APIs don’t exist in isolation. Message queues (RabbitMQ, Kafka), service discovery, distributed tracing – these topics come with the territory in microservice architectures.
5. Cloud-Native: Writing Code Is Only Half the Job
I’ve met developers who have everything running perfectly on localhost, and it all falls apart at deployment. Ask if they’ve used Docker and the answer is “watched a tutorial, haven’t tried it.”
In 2026, finishing the code is only half the work. The other half is getting it to run in the cloud.
Docker is your entry ticket. Multi-stage builds for smaller images, understanding layer caching, writing sensible Dockerfiles – these are fundamentals:
# Multi-stage build: install dependencies first, then copy code
# Change code without reinstalling packages, leveraging cache
FROM python:3.12-slim AS builder
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
FROM python:3.12-slim
WORKDIR /app
COPY --from=builder /usr/local/lib/python3.12/site-packages /usr/local/lib/python3.12/site-packages
COPY . .
CMD ["uvicorn", "main:app", "--host", "0.0.0.0"]
Serverless matters. AWS Lambda, Google Cloud Functions, Azure Functions. Optimizing cold starts, packaging dependencies, local testing strategies – you need to have stepped on these landmines at least once to say you know the basics.
Infrastructure as Code. Define cloud resources with Python using Pulumi or AWS CDK. Way more reliable than clicking through console UIs. Environment consistency, version control, rollback capability – all depends on this.
Here’s the thing: Python in the cloud and Python on your laptop are two different animals. You need to handle stateless design, configure CloudWatch logging, and think about the bill behind every line of code. Lambda charges per invocation – your code efficiency directly affects company spend.
6. AI Integration: You Don’t Need to Be a Scientist, but You Need to Be a General Contractor
What’s the highest-paying Python role in 2026? AI/LLM Engineer, at $140K to $250K+ per year.
The good news: you don’t need to publish papers or derive equations. Most companies aren’t training models from scratch. They’re integrating existing AI capabilities into business systems. You’re doing the assembly and plumbing; the model architects draw the blueprints.
LLM orchestration is a core skill. LangChain, LlamaIndex, or direct API calls to OpenAI and Anthropic. Writing good prompts, managing conversation memory, controlling token consumption – that’s the day-to-day.
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field
class ProductReview(BaseModel):
sentiment: str = Field(description="positive/negative/neutral")
key_points: list[str] = Field(description="Key takeaways")
confidence: float = Field(description="Confidence score 0-1")
parser = PydanticOutputParser(pydantic_object=ProductReview)
prompt = ChatPromptTemplate.from_messages([
("system", "You are a product review analyst. {format_instructions}"),
("human", "Analyze this review: {review}")
])
chain = prompt | ChatOpenAI(model="gpt-4") | parser
Vector databases are essential. RAG (Retrieval-Augmented Generation) is the most common pattern in enterprise AI applications right now. Pinecone, Weaviate, pgvector – you need to know at least one. The concept is straightforward: chunk documents, convert to vectors, store them, retrieve relevant content when users ask questions and feed it to the LLM.
Model deployment basics. Wrap model interfaces with FastAPI, understand the difference between batch and real-time inference, know basic MLOps workflows. You don’t need to train models yourself, but you need to turn someone else’s trained model into a usable service.
7. Testing: Would You Ship Without a Safety Net?
I’ve talked to junior developers about why they don’t write tests. The most common answers are “no time” and “can barely finish features, who has time for tests?”
That’s like saying “I’m too busy driving to check the map.” Then three days later you realize you’ve been going the wrong direction.
pytest is the standard. Skip unittest – too verbose. pytest’s fixtures, parametrization, and plugin ecosystem are hard to leave once you’ve used them:
import pytest
from httpx import AsyncClient
from app.main import app
@pytest.fixture
async def client():
async with AsyncClient(app=app, base_url="http://test") as ac:
yield ac
@pytest.mark.parametrize("email,expected_status", [
("valid@test.com", 201),
("not-an-email", 422),
("", 422),
])
async def test_create_user(client, email, expected_status):
response = await client.post("/users", json={
"username": "testuser",
"email": email
})
assert response.status_code == expected_status
Testing should happen alongside coding. The best habit is to test as you write. Change a line, run the tests. Set up GitHub Actions or GitLab CI in your pipeline to automatically run tests, linting (ruff is way faster than flake8), and type checking (mypy) on every push.
Don’t chase coverage numbers – chase critical paths. 100% coverage doesn’t mean zero bugs, but if your core business logic is below 80% coverage, there are probably landmines waiting for you.
8. DevOps and Automation: The Person Who Saves the Team Time Is Worth the Most
Python’s position in DevOps is rock solid. Ops automation, log parsing, toolchain integration – Python scripts just feel good to write for this stuff.
But we’re not talking about scripts that rename files. We’re talking about:
- Exposing custom metrics with Prometheus client libraries, building monitoring and alerting
- Automating code review workflows with GitPython, or writing release pipelines
- Orchestrating server configs with Ansible, or batch server operations with Python scripts
People who automate away repetitive work earn serious respect on their teams. Picture this: everyone spends 4 hours a week on a manual task. You write a script that turns it into a one-click operation. Over a year, that’s 200 hours saved for the team. That kind of contribution is a concrete win in performance reviews.
9. Collaboration: Git Is More Than Push and Pull
Once technical ability reaches a certain level, what separates people is how well they work with others.
Git workflows need to be second nature. Feature branching, the tradeoffs between rebase and merge, semantic versioning. These aren’t theory – they’re things you use every day.
PRs should tell a story. A good PR description covers: what problem this change solves, why this approach was chosen, and what risks to watch for. Not a one-liner that says “fix bug.”
Code review goes both ways. Writing good code matters. Spotting problems in other people’s code matters just as much. Reviewing code isn’t about nitpicking style – it’s about finding logic flaws.
Keep your dependency management current. Poetry has been around for years, but uv (a Python package manager written in Rust) is absurdly fast. Lock files for reproducibility, plus pip-audit for dependency security scanning – that combo is standard now.
Learning Roadmap: Four Phases From Zero to Interview-Ready

Knowing what to learn isn’t enough – you need to know the order. This roadmap is based on actual hiring requirements in the current market.
Phase 1: Build the Foundation (Days 1-30)
Goal: write scripts independently, debug your own errors.
Core topics: variables and data types, control flow (if/for/while/list comprehensions), functions (arguments, return values, scope), data structures (lists, dicts, sets, tuples – when to use which), file I/O (text, CSV, JSON), error handling, virtual environments (venv or uv).
Practice projects:
- Calculator with error handling
- Password generator with user preferences
- Downloads folder auto-organizer script
- CSV data cleaner (dedup, handle missing values)
Spend 1-2 hours daily. After following a tutorial, modify it until you get different results. If you can’t explain a concept in plain English to someone else, you don’t actually understand it.
Phase 2: Connect to the Real World (Days 31-60)
Goal: evolve from isolated scripts to tools that interact with external systems.
Core topics: OOP (classes, inheritance, dunder methods), modules and packages (organizing your own code), API calls (requests library, HTTP methods, JSON parsing), regular expressions (text extraction and validation), database basics (SQLite for local storage, SQL fundamentals), Git workflows (commit, branch, merge, GitHub).
Practice projects:
- Weather dashboard: fetch API data, store in SQLite, show historical trends
- CLI expense tracker with data persistence and category stats
- Web scraper for job listings or product prices (respect robots.txt)
- Bulk personalized email sender
Push every project to GitHub. Write proper READMEs. These are the start of your portfolio.
Phase 3: Pick a Direction, Go Deep (Days 61-90)
Time to choose. Pick one of three mainstream tracks and dive in:
Track A - Backend Development: Deep dive into FastAPI or Flask, SQLAlchemy ORM + Alembic for database migrations, JWT auth and password hashing, pytest for API tests, Docker containerization + Gunicorn + Nginx reverse proxy deployment.
Track B - Data Science / AI: NumPy vectorized operations, Pandas data cleaning and groupby, Matplotlib/Seaborn for visualization, Scikit-learn for regression/classification/clustering, Jupyter Notebooks for reproducible analysis.
Track C - Automation / DevOps: System automation scripts (SSH with Paramiko, FTP operations), Excel/Word auto-generation (OpenPyXL, python-docx), CI/CD pipelines (GitHub Actions, pre-commit hooks), AWS basics (S3, Lambda, EC2).
The finish line for this phase is a complete capstone project. Not something built by following a tutorial – something you designed, built, and deployed from scratch.
Phase 4: Advanced Polish (Months 4-6)
Goal: understand the “why” behind the “how.”
Advanced topics: asyncio and concurrency patterns, design patterns in Python (Factory, Strategy, etc.), performance optimization (cProfile profiling, memory optimization, Cython basics), advanced testing (property-based testing with Hypothesis, mutation testing), contributing to open source.
Also start polishing your portfolio: refactor old projects with new knowledge, write technical blog posts about your solutions, get active in the community.
Salary Reference: Your Specialization Sets Your Ceiling
Same language, wildly different pay. Here’s 2026 data from US tech hubs:
| Role | Experience | Salary Range (USD) | Key Skills |
|---|---|---|---|
| Junior Python Developer | 0-2 years | $60K-$90K | Core Python, Git, SQL |
| Backend Engineer | 2-4 years | $90K-$140K | FastAPI/Django, PostgreSQL, Docker, AWS |
| Data Engineer | 2-5 years | $95K-$150K | Pandas, Spark, Airflow, SQL |
| ML Engineer | 3-5 years | $120K-$180K | Scikit-learn, TensorFlow/PyTorch, MLOps |
| AI/LLM Engineer | 3-6 years | $140K-$250K+ | LangChain, RAG, Vector DBs, Fine-tuning |
The trend is consistent globally: the closer you are to AI and cloud-native work, the higher the ceiling.
One Last Honest Take
Python has a low barrier to entry. That’s exactly why so many people flood in. When everyone’s at the same starting line, what determines who gets the offer is whether you can write code that other people on the team can actually read, and whether your service can run at 3 AM without catching fire. Hiring managers don’t care how many tutorial hours you’ve logged. They care whether that project on your GitHub is something you built from zero.
The most effective way to find a Python job in 2026 is to open your editor, create a blank project, and start writing code to solve a problem you personally care about. Ugly code is fine. Once you’ve finished it, deployed it, and it works – you’re already ahead of most people who only watch tutorials.
FAQ
How long does it take to get a Python job starting from zero?
Following the four-phase roadmap above, full-time study gets you interview-ready in roughly 4-6 months. Part-time, double that. But “how long” is the wrong question, really. What matters is whether your GitHub has 2-3 complete projects to show. A friend of mine didn’t even finish three months of study, but he built a genuinely useful job posting analytics tool. He spent 20 minutes walking through that project in the interview and got the offer on the spot. Time isn’t the metric – your work is.
Is Python still worth learning in 2026? Will AI replace Python developers?
Not in the near term. Python is actually becoming more important in AI/ML, not less. AI tools can definitely crank out boilerplate code for you, but architecture decisions, performance tuning, and production debugging still need a human behind the wheel. Instead of worrying about replacement, learn to use AI tools to boost your own productivity. According to 2026 survey data, Python developers who use GitHub Copilot and similar AI assistants are roughly 30% more productive than those who don’t.
Backend, data, or AI – which track should I pick?
Depends on your interests and background. If you like building systems and products, backend is the fastest to get started and has the most open positions. If you have a math or statistics background, the data track has a very high ceiling. If you’re chasing the highest possible salary, AI/LLM engineering currently pays the most ($140K-$250K+), but it also demands the broadest skill set – you need backend, data, and model deployment knowledge all at once. There’s no right answer. Pick one, do it for three months, and switch if it doesn’t fit. That beats standing at the door for six months wondering which way to go.