PostgreSQL Query Parsing Too Slow? PgDog Ditched Protobuf and Got 5x Faster

Your SQL Proxy Is Slow? Maybe It’s Not the Parser — It’s the Middleman
The PgDog team recently published a blog post with a pretty direct title: “Replacing Protobuf with Rust to go 5 times faster.”
PgDog is a Rust-based PostgreSQL proxy that handles sharding and query rewriting. They found something unexpected: their SQL parsing was slow, but not because of the PostgreSQL parser itself. Protobuf serialization was the bottleneck.
So they ripped it out.
Why Does a Proxy Care About SQL Parsing?
PgDog is a PostgreSQL proxy that sits between your application and the database. It takes incoming SQL, parses it into an AST, does fingerprinting and query rewriting, and sometimes converts the AST back into SQL text.
As a proxy, the latency budget is tight. Every extra millisecond is noticeable to users.
PgDog uses pg_query.rs under the hood, which wraps libpg_query — the battle-tested PostgreSQL native parser. But pg_query.rs adds a Protobuf layer for cross-language compatibility, so Ruby, Go, and other languages can all work with the same AST structure.
Is Protobuf fast? Yes. But it still has to serialize C structs into bytes, then deserialize them into Rust structs. That’s two extra steps.
When the PgDog team profiled with samply and looked at the flame graph, pg_query_parse_protobuf was eating up most of the CPU time. The actual PostgreSQL parser pg_query_raw_parse? Barely visible.
Think of it this way: you ask a coworker to send you a file, but instead of emailing it directly, they print it out, scan it to PDF, then email the PDF. No wonder it’s slow.
Caching Helped, But Not Enough
The first instinct was to add a cache. LRU cache with query text as the key and the AST as the value. Works well with prepared statements since the query text stays the same across calls.
But two situations break the cache:
Some ORMs generate tons of unique queries:
-- ORM-generated, different parameter count every time, cache miss
SELECT * FROM users WHERE id IN ($1, $2, $3, $4, $5, ...);
-- Should really be written as
SELECT * FROM users WHERE id = ANY($1);
And legacy client drivers that don’t support prepared statements send different SQL text every time.
Caching helped somewhat, but Protobuf was still the dominant cost in the flame graph.
Ditching Protobuf, Connecting C to Rust Directly
PgDog forked pg_query.rs and replaced the Protobuf serialization layer with direct C-to-Rust bindings:
- Used
bindgento generate Rust structs directly fromlibpg_query’s C headers - Wrote
unsafewrapper functions to convert C AST nodes into Rust structs - Kept the original Protobuf structs around for comparison testing
Tedious work — 6,000 lines of recursive Rust code mapping C types to Rust types. But the results were fully verifiable: for every test case, they ran both parse (Protobuf path) and parse_raw (direct FFI path), and if even a single byte differed, the test failed.
They used Claude to generate a lot of the repetitive glue code. Given a well-defined input/output spec, having AI handle this kind of verifiable grunt work turned out pretty well.
Why Recursion?
For converting C structs to Rust structs, PgDog went with recursion. The AST is a tree — each node may have child nodes, so the converter recurses into children.
unsafe fn convert_node(node_ptr: *mut bindings_raw::Node) -> Option<protobuf::Node> {
if node_ptr.is_null() {
return None;
}
match (*node_ptr).type_ {
bindings_raw::NodeTag_T_SelectStmt => {
let stmt = node_ptr as *mut bindings_raw::SelectStmt;
Some(protobuf::node::Node::SelectStmt(
Box::new(convert_select_stmt(&*stmt))
))
}
// ... hundreds more node types
_ => None,
}
}
Recursion is faster than iteration here. Stack space is allocated at program startup — no extra heap allocation needed. The same function’s instructions stay hot in the CPU cache. And tree traversal with recursion is just more intuitive to read and debug.
They tried an iterative version. It was actually slower — extra HashMap lookups and memory allocations added more overhead than Protobuf itself.
The Numbers
PgDog published benchmarks on GitHub:
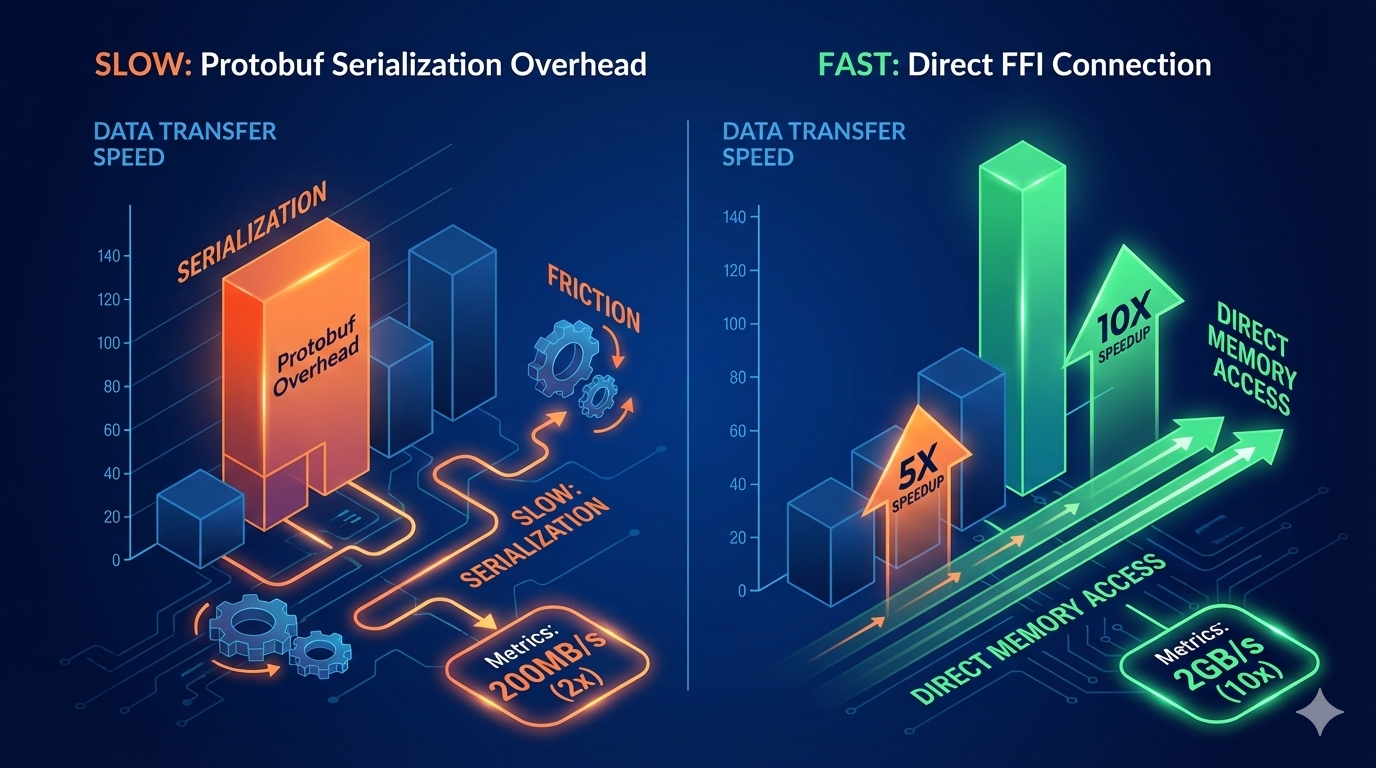
| Function | Protobuf Path | Direct FFI Path | Speedup |
|---|---|---|---|
| Parse | 613 queries/sec | 3,357 queries/sec | 5.45x |
| Deparse | 759 queries/sec | 7,319 queries/sec | 9.64x |
In real-world pgbench tests, overall throughput improved by 25%. Parsing got faster, the query rewrite engine had less pressure, and cache hit rates stabilized.
Pitfalls They Hit
ABI drift. PostgreSQL upgrades can change AST node definitions. Code generated by bindgen changes along with it. Without pinning the version, a database upgrade can break the build. They locked the PostgreSQL header version in CI.
Null pointers. In FFI land, treat every pointer as hostile. If you use something from C without checking is_null() first, you’re going to have a bad time. Their approach: keep each unsafe block as small as possible, validate pointers on entry, return safe Rust types on exit.
Cross-language compatibility. If your team has Ruby, Go, or Python consumers depending on the Protobuf structs, you still need to keep the schema around. PgDog just stopped using Protobuf internally.
If You Want to Try This
PgDog shared some practical advice:
Start with samply and Firefox profiler to get a flame graph — don’t guess. Keep Protobuf around for comparison testing, and make sure old and new paths produce identical output. Pin the PostgreSQL header version in CI, and require review when AST structures change. Add a feature flag or environment variable so you can switch back to the Protobuf path instantly. Keep unsafe blocks small and only expose safe interfaces externally.
They also recommend a dual-path implementation controlled by environment variable, so you can roll back in seconds without redeploying.
Final Thoughts
This is an interesting case. The performance bottleneck wasn’t where you’d expect (the PostgreSQL parser) — it was in a seemingly “standard” middle layer (Protobuf serialization). In high-frequency SQL parsing scenarios, every layer of abstraction has a cost. PgDog chose to trade cross-language convenience for performance, connecting C and Rust directly, and the results were immediate.
Of course, not every scenario warrants this approach. If your parsing frequency isn’t that high, Protobuf’s overhead is a non-issue. Engineering is about tradeoffs.
Found this useful? Give it a like or share it around.
What’s the most surprising performance bottleneck you’ve found hiding in your project?