500 Lines of Rust, 10 Seconds to Train: How Simple Is Building a Neural Network from Scratch?

Table of Contents
- Don’t Let “Neural Network” Scare You Off
- Why Rust for Machine Learning?
- What Are We Building?
- The Five-Step Pipeline
- Training: The Dumb Way Is the Right Way
- Project File Structure
- Try It Yourself
- What Can You Learn from This Rust Neural Network Project?
- Watch Out for These Pitfalls
- What’s Next?
- Cheatsheet: Quick Reference
Don’t Let “Neural Network” Scare You Off
When most people hear “neural network,” they picture some PhD in a plaid shirt whispering to three GPUs, desk buried under linear algebra textbooks, monitors flickering with incomprehensible Greek symbols.
The reality?
The core logic of a neural network is about as complicated as building a spreadsheet. Plug in some numbers, multiply by weights, add a bias, check if the result is right, adjust if it’s not, repeat a few hundred times. Done.
Today I’m going to walk you through building a spam-detecting neural network in Rust. 500 lines of code. 10 seconds to train. Runs on your laptop. This might be the friendliest Rust neural network starter project you’ll ever find.
No GPU needed. No Python needed. Just a machine with Rust installed and a bit of curiosity.
Why Rust for Machine Learning?
A lot of people think Rust machine learning is a niche choice. But let me put it this way: would you rather slice a steak with a proper knife or a plastic one? The plastic knife technically works, but the experience is worlds apart.
Python is convenient for ML, no question. Great ecosystem, tons of tutorials. But it has a few things that drive you up the wall:
- Python runs inference like a grandpa on a morning stroll. Production needs a sprint.
- The GIL is a single-lane bridge. No matter how many cars show up, they’re all waiting in line.
- You have to haul the entire PyTorch framework onto your server. That’s several gigabytes just for the framework, and cold starts are painful.
Rust? Compile it once and you get a single binary. Drop it on a server and it just runs. No runtime overhead, no garbage collection pauses, memory usage is exactly what you ask for.
Hugging Face built a lightweight ML framework specifically for Rust called Candle. The Candle framework has over 19,000 stars on GitHub, the community is active, and it’s the most mature option in the Rust deep learning ecosystem right now.
Candle’s idea is straightforward: the API looks a lot like PyTorch, so anyone who knows PyTorch can pick it up with almost zero friction, but underneath it’s running at Rust speed.
What Are We Building?
The goal is simple: a spam classifier.
You feed it a sentence, it tells you whether it’s spam or not:
"Win money now" --> SPAM (100%)
"Hello friend" --> HAM (100%)
"Free iPhone click" --> SPAM (100%)
"See you tomorrow" --> HAM (100%)
Humble, right? But don’t underestimate this little project. As a neural network starter exercise, you’ll learn the same theory that fills hundreds of pages in textbooks.
The Five-Step Pipeline
The entire system’s data flow looks like this:
Text --> Tokenizer --> Embedding --> Mean Pooling --> Linear Layer --> Softmax --> Prediction
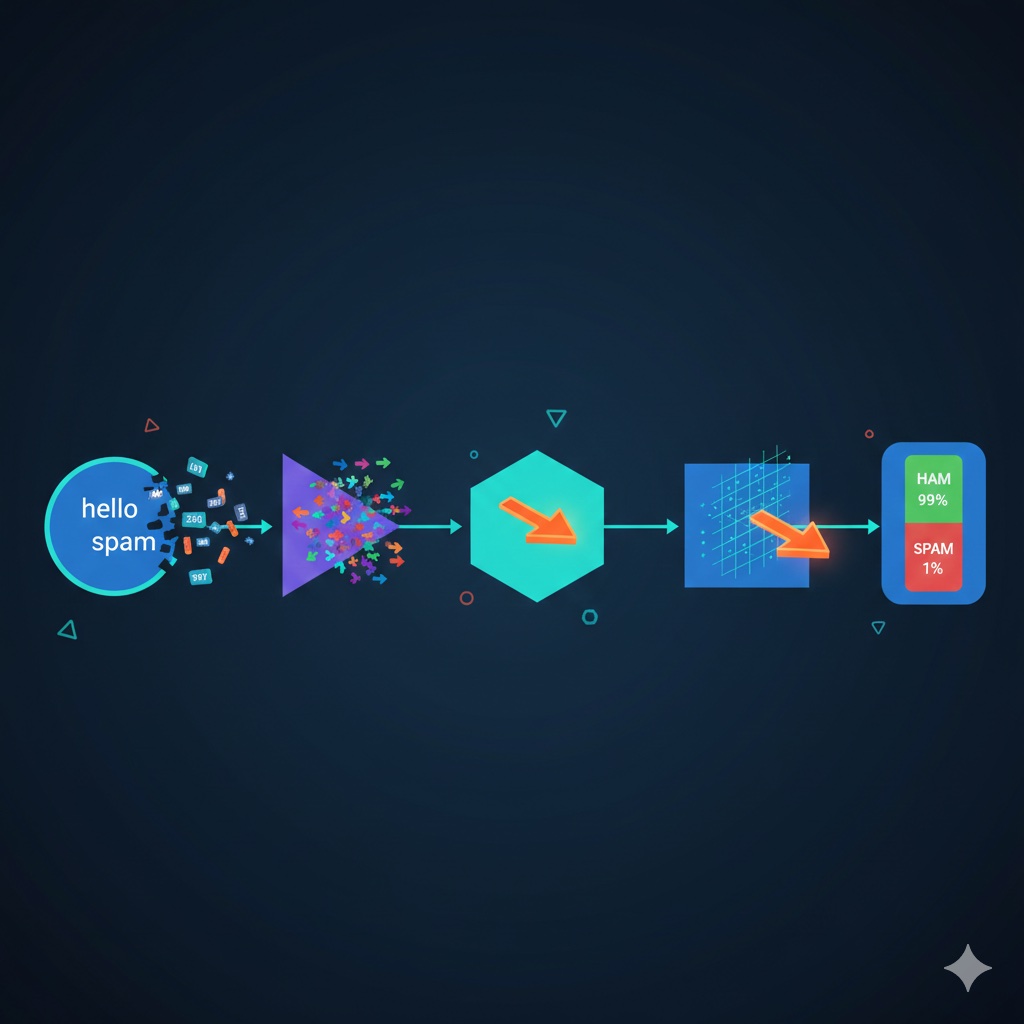
Think of it like a restaurant processing an order:
- The tokenizer is the front-of-house waiter, translating the customer’s words into order numbers the kitchen understands
- The embedding layer is the prep station, tagging each ingredient with a set of nutritional data
- Mean pooling is the blender, turning ingredients of different sizes into a uniform paste
- The linear layer is the head chef, looking at that paste and making a judgment call
- Softmax is the serving window, turning the chef’s judgment into a clear score
Let’s break each one down.
Step 1: Tokenizer, Turning Words into Numbers
Neural networks don’t read text. They only understand numbers. So the first thing we need to do is translate words into numbers.
How? Brute force. Build a dictionary, assign each word an ID:
"hello" --> 1
"friend" --> 2
"win" --> 3
"money" --> 4
Now “hello friend” becomes [1, 2].
No black magic here. Under the hood it’s just a HashMap with words as keys and IDs as values. Your phone’s contact list is basically a tokenizer: “Mom” maps to “555-0101,” “Boss” maps to “555-0102.”
pub struct Tokenizer {
vocab: HashMap<String, u32>,
next_id: u32,
}
impl Tokenizer {
pub fn build_vocab(&mut self, texts: &[String]) {
for text in texts {
for word in text.to_lowercase().split_whitespace() {
if !self.vocab.contains_key(word) {
self.vocab.insert(word.to_string(), self.next_id);
self.next_id += 1;
}
}
}
}
pub fn encode(&self, text: &str) -> Vec<u32> {
text.to_lowercase()
.split_whitespace()
.filter_map(|w| self.vocab.get(w).copied())
.collect()
}
}
A few lines and the tokenizer is done.
Step 2: Embedding, Giving Each Word a “Personality”
Just having IDs isn’t enough. The difference between ID 1 and ID 2 is 1, and between ID 1 and ID 100 is 99, but that doesn’t mean ID 1 and ID 2 are more “similar.”
The embedding layer assigns each word a 16-dimensional vector. Think of it as writing a 16-question personality profile for every word.
At first these personalities are randomly assigned, like freshmen getting randomly placed into dorms. But after a few rounds of training, words with similar meanings start moving closer together:
- “free,” “win,” “money” are spam regulars, and their vectors gradually cluster together
- “hello,” “friend,” “tomorrow” are normal words, and they form their own group
The model isn’t following rules we wrote. It figured out on its own which words tend to show up together in spam.
Step 3: Mean Pooling, Standardizing Variable-Length Inputs
“Hi” is one word. “Click here now free offer” is five words. Each word has a 16-dimensional vector.
Here’s the problem: one word produces one 16-dimensional vector, five words produce five. The linear layer downstream needs a fixed-size input. What do we do?
Mean pooling takes the simple approach: add up all the word vectors and take the average.
Whether the input was one word or a hundred, the output is always a single 16-dimensional vector. It’s like a juicer: whether you toss in one apple or a basket of strawberries, out comes one glass of juice, same size cup.
Step 4: Linear Layer, Making the Call
With a fixed-size vector in hand, the linear layer does what is essentially matrix multiplication plus a bias.
16-dimensional input, multiplied by a 16x2 weight matrix, plus bias, outputs two scores: one for “probability of spam,” one for “probability of ham.”
This is the head chef reviewing the ingredient report and making a call. The weight matrix is the chef’s experience. The bias is his gut feeling.
Step 5: Softmax, Turning Scores into Probabilities
The two scores from the linear layer can be any numbers, like 3.7 and -1.2. Not very intuitive for humans.
Softmax squashes them into probabilities between 0 and 1 that add up to 1. Say spam gets 0.99 and ham gets 0.01. Now it’s crystal clear: 99% confident it’s spam.
Training: The Dumb Way Is the Right Way
The core training code looks like this:
for epoch in 1..=300 {
for (tokens, label) in &training_data {
// Forward pass: feed data, get prediction
let logits = model.forward(&tokens)?;
let probs = softmax(&logits, 0)?;
// Compute loss: how far off is the prediction?
let loss = cross_entropy(&probs, label)?;
// Backward pass + update weights: adjust based on error
optimizer.backward_step(&loss)?;
}
}
In plain English:
- Grab a training example
- Let the model guess
- Check if it guessed right
- If not, adjust the parameters
- Repeat 300 times
It’s like learning to cook: make the dish, taste it, too salty means less salt next time, too bland means more. After 300 rounds you’ve pretty much got it down.
Loss values during training:
Epoch 1 | Loss: 0.5388
Epoch 100 | Loss: 0.0022
Epoch 200 | Loss: 0.0009
Epoch 300 | Loss: 0.0005
Loss near zero means the model has learned. The whole training process takes about 10 seconds on a regular laptop.
Project File Structure
The entire project is just four files, under 500 lines total:
| File | Purpose |
|---|---|
main.rs | Training loop + inference entry point |
model.rs | Neural network structure definition |
tokenizer.rs | Tokenizer |
dataset.rs | Training dataset |
After training, the model saves to spam_classifier.safetensors. Load it next time without retraining.
Try It Yourself
git clone https://github.com/aarambh-darshan/spam_candle_ai.git
cd spam_candle_ai
cargo run
After training completes, interactive mode lets you test whatever you want:
Enter text: hello friend
"hello friend" --> HAM (100.0%)
Enter text: click here free money
"click here free money" --> SPAM (99.9%)
Enter text: quit
Goodbye!
That’s it. No ceremony.
What Can You Learn from This Rust Neural Network Project?
The biggest thing I took away from building this: doing it once by hand beats reading ten tutorials. That’s also why I’d recommend Rust machine learning as a starting point. Rust’s type system forces you to think through every step clearly.
A few things that really sank in:
Tokenization is just a dictionary lookup. No magic. It’s a HashMap. That fancy NLP preprocessing you’ve been intimidated by is fundamentally no different from flipping through a bilingual dictionary.
Neural networks are matrix multiplication. Strip away all the jargon and it’s numbers being multiplied and added together. Layer after layer.
Backpropagation is about finding “who’s responsible.” The model got it wrong, so you trace back along the computation path, figure out which weight pulled things off course, and nudge it. Like reviewing a failed exam: was it the multiple choice or the essay questions? Then you focus your study accordingly.
Training has no eureka moment. It’s feeding data, computing errors, adjusting parameters, over and over. Going from loss 0.5 to loss 0.0005 takes patience, not talent.
Watch Out for These Pitfalls
Not Enough Training Data
This demo project uses only 40 training examples. Fine for learning, but nowhere near enough for real-world use. A real spam classifier needs thousands or tens of thousands of samples. Start by getting the full pipeline working with these 40 examples, then swap in a real spam dataset from Kaggle. Don’t try to go big from the start.
Model Is Too Simple
This model has no hidden layers, just a single linear layer doing classification. Complex text patterns like sarcasm or innuendo? It won’t catch them. The good news is that adding a hidden layer with ReLU activation significantly boosts expressiveness. Candle fully supports it, and it’s under 10 lines of code to change.
Unknown Words
If a user types a word that never appeared in the training data, the tokenizer just ignores it. The whole sentence might become an empty array. You can add an <UNK> (unknown word) fallback token that all unseen words map to. Not perfect, but at least it won’t crash.
What’s Next?
Once you’ve got the basic version running, there are a few directions to keep exploring:
- Scale up the data. 40 examples is just an appetizer. Swap in a real dataset and see how much the accuracy improves.
- Add hidden layers. Use ReLU activation to give the model more expressive power.
- Turn it into an API. Wrap the model in Axum or Actix as a web service with an endpoint.
- Go Transformer. The Candle framework supports attention mechanisms. You can go from a simple spam classifier all the way to a Transformer within the same framework, going deeper into Rust deep learning.
In one sentence: Candle handles “running fast,” you handle “thinking clearly.”
Cheatsheet: Quick Reference
# Clone the project
git clone https://github.com/aarambh-darshan/spam_candle_ai.git
# Run training + interactive inference
cargo run
# Project structure
main.rs --> Training loop + inference
model.rs --> Network definition (embedding + linear layer)
tokenizer.rs --> Tokenizer (HashMap lookup)
dataset.rs --> Training samples
# Core pipeline
Text --> Tokenize --> Embed(16-dim) --> Mean Pool --> Linear(2-class) --> Softmax --> Result
# Key dependencies
candle-core --> Tensor operations
candle-nn --> Neural network modules
That’s it. Today we built a Rust neural network from scratch. 500 lines of code, 10 seconds of training, four files, one laptop.
Rust machine learning is just math, code, and repetition. Nothing mysterious about it.
Build it yourself once. You see every weight update. You see every pattern the model picks up. That kind of understanding doesn’t come from reading papers.
What’s the step that’s tripping you up most in learning machine learning? The math foundations, choosing a framework, or just not knowing which project to start with? Drop a comment. The thing you’re stuck on might be a pothole someone else has already climbed out of.
Next time we’ll talk about adding attention mechanisms to this model, so it doesn’t just check whether words appeared, but understands the relationships between them. The gap between “it works” and “it works well” comes down to this.
If you found this helpful, share it with a friend who’s into Rust or machine learning. Writing these from-scratch tutorials takes real effort, but every time someone says “I finally get it,” it’s worth it. Follow Dream Beast Programming for more hands-on Rust content.
Resources: