From 800ms to 90ms: How Rust Rayon Saved My Multithreading Nightmare
800ms: Not Long, Not Short
In the Rust concurrency world, performance optimization is a topic you cannot dodge.
Honestly, when I first saw a batch job take 800ms, I did not care at all.
800ms is under a second. I even told myself: users will not feel that.
But when that job runs hundreds or thousands of times in production, it adds up fast. Users start saying “the system feels slow” and the boss starts asking “can we optimize this?”
I stared at my carefully written multithreading code and went quiet for a second.
How My “Carefully Designed” Version Looked
Let me show you what I wrote back then. A classic “textbook” multithreading setup:
use std::thread;
fn process_data(v: &Vec<i32>) -> i32 {
v.iter().map(|x| x * 2).sum()
}
fn main() {
let data: Vec<i32> = (0..1_000_000).collect();
let chunks: Vec<&[i32]> = data.chunks(250_000).collect();
let mut handles = vec![];
for chunk in chunks {
handles.push(thread::spawn(move || {
process_data(&chunk.to_vec())
}));
}
let mut total = 0;
for h in handles {
total += h.join().unwrap();
}
println!("Result: {}", total);
}
Looks pretty standard, right? Split data into four chunks, spawn four threads, process in parallel, then merge the results.
When I wrote this, I felt proud. “Divide and conquer, parallel compute, perfect.” That was the vibe.
Reality slapped me.
So Where Did It Go Wrong?
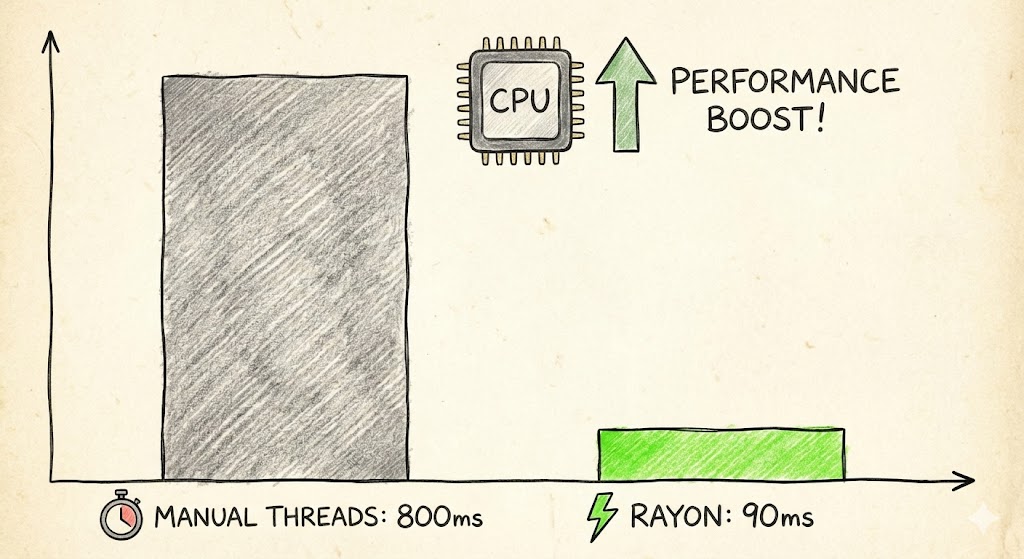
After benchmarking, the result was: 800ms +/- 10ms.
My first reaction was: wait, four threads should be four times faster, right? Why is this still so slow?
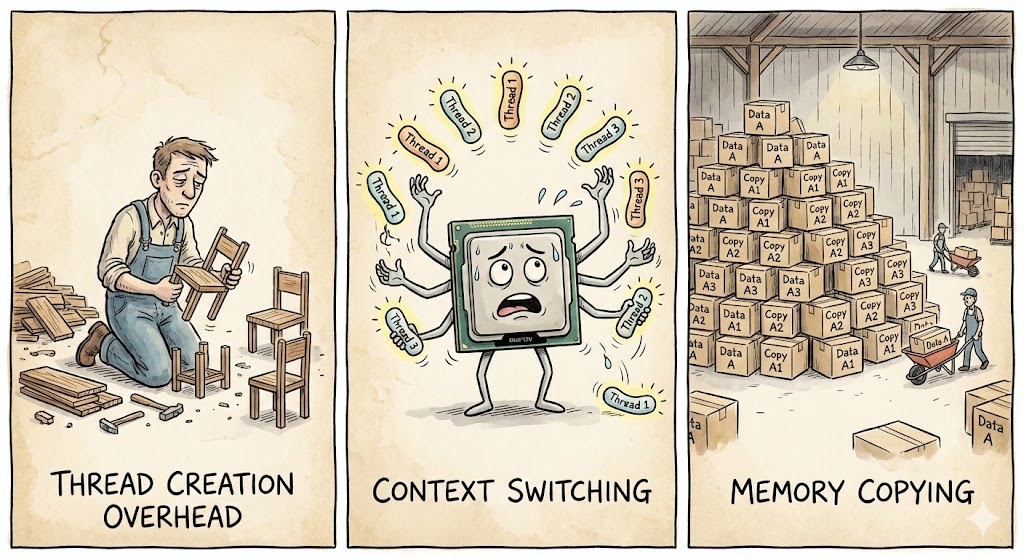
Then I looked closer. The problems were obvious:
First, thread creation overhead. Every run creates new threads. That cost is not small. It is like buying a full set of furniture every time you move, then throwing it away.
Second, context switching cost. The OS keeps switching between threads, saving and restoring state. All that time is just overhead.
Third, memory copying. See the chunk.to_vec()? Each chunk gets copied into a new thread. One million numbers copied four times. Your memory bandwidth just disappeared.
Stack those three together and your optimization effort turns into wasted work.
Meeting Rayon: Everything Changed
A colleague recommended Rayon. To be honest, I assumed it was just another wheel.
Then I changed the code to this:
use rayon::prelude::*;
fn main() {
let data: Vec<i32> = (0..1_000_000).collect();
let total: i32 = data.par_iter()
.map(|x| x * 2)
.sum();
println!("Result: {}", total);
}
Benchmark result: 90ms +/- 5ms.
I froze.
Same functionality, half the code, almost 9x faster. What is this.
What Magic Does Rayon Actually Do?
Calling it magic is unfair. Rayon has real engineering behind it. It is one of the most popular concurrency libraries in the Rust ecosystem, and its core trick is the work-stealing scheduler.
In plain English, it looks like this:
+-------------------+ +-------------------+
| Thread Pool |<----->| Task Queue |
+-------------------+ +-------------------+
| ^
v |
CPU Core 1 <--work stealing--> CPU Core N
The traditional approach pre-splits the data into fixed chunks, and each thread handles one chunk. But what if one thread finishes early? It just sits there, watching other threads keep working.
Rayon does it differently. It assigns tasks dynamically. When one thread finishes, it “steals” some work from a still-busy thread and keeps going.
It is like a group of friends making dumplings. The old way says everyone gets a pile of filling and stops once theirs is done. With work stealing, whoever finishes first jumps in to help others, and everybody keeps going until all the filling is gone. That is real load balancing.
When Should You Use Rayon?
By now you might be ready to rewrite everything. Slow down. A few guidelines first.
Good fits for Rayon:
- Large datasets (tens of thousands or more). Like inviting friends to make dumplings, it only makes sense when there is a mountain of filling.
- Similar work per element. Everyone is making the same dumplings, no one is chopping onions while someone else is boiling water.
- CPU-bound tasks. Most of the time is spent doing work at the table, not waiting on something outside.
Not a great fit:
- Small datasets (hundreds or a few thousand). A few plates of dumplings are faster solo than calling everyone over.
- Heavy I/O logic. If you are waiting on disk or network, helpers just end up waiting too.
- Complex dependencies between tasks. If you must season before rolling and roll before boiling, too many dependencies make parallel work messy.
Small datasets can even be slower with Rayon because scheduling itself costs time. It is like calling 10 couriers to deliver a single package: coordinating them takes longer than just doing it yourself.
Final Benchmark
Here is the final data:
| Version | Time (ms) | Speedup |
|---|---|---|
| Manual thread management | 800 | 1x |
| Rayon parallel iterators | 90 | ~8.9x |

Nearly 9x faster and the code is half the size. That is a good trade.
Wrapping It Up
The biggest lesson for me was this: the best optimization is not always a micro-tweak, sometimes it is picking the right tool.
I spent hours tweaking thread counts and chunk sizes, and a library swap solved it. It felt like trying to tighten a screw by hand while someone hands you a power drill.
If you are still manually managing threads in Rust, pause and ask: do you really need to?
Rayon already handles the messy stuff for you: thread pool management, work stealing, load balancing. You just swap iter() for par_iter() and let it do the rest.
And yes, do not forget to benchmark. The first rule of optimization is always: measure first, then touch the code.
If this helped, feel free to like, share, or bookmark. Follow me and I will keep posting Rust case studies and performance tips.
Got questions or ran into edge cases? Drop a comment and let us dig into it together.