When Your Actor Cluster Grows Up, It Needs Sharding
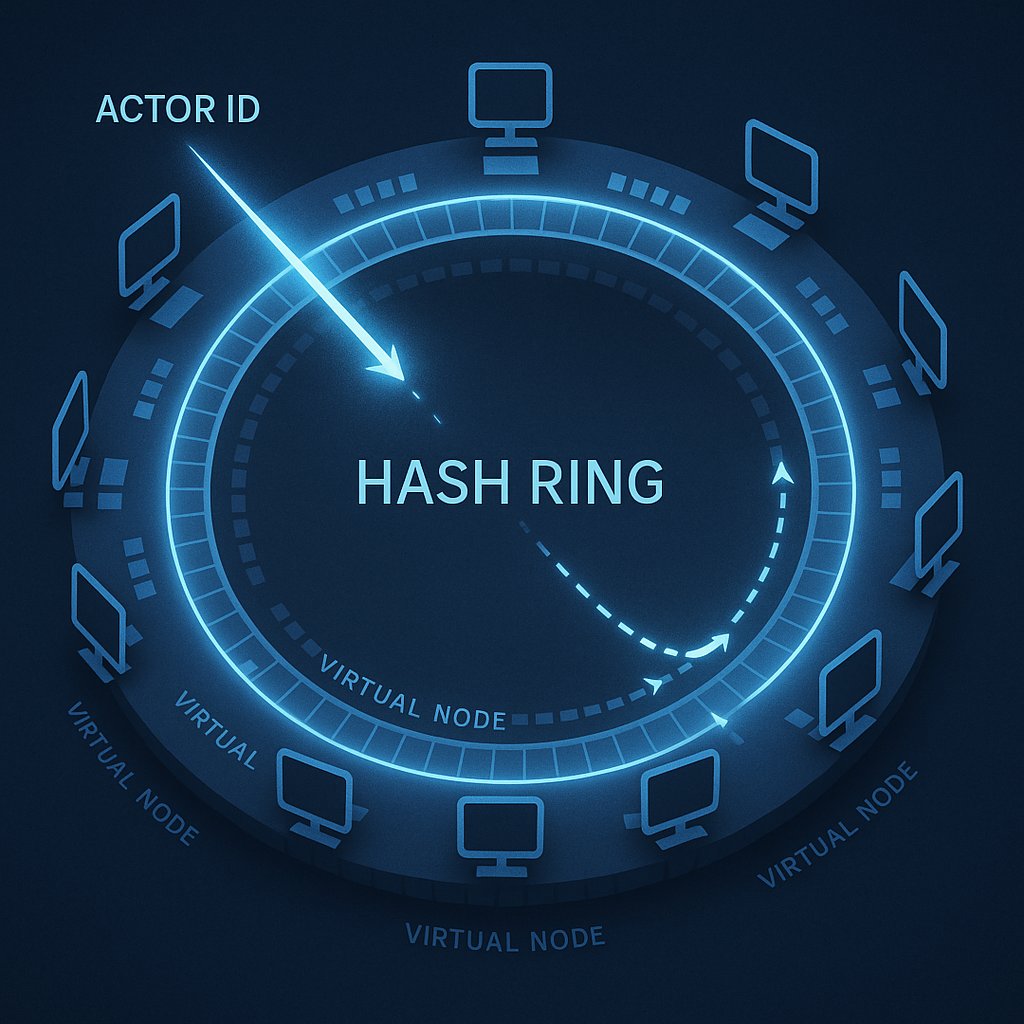
Table of Contents
- Why Sharding? The Package Sorting Center Analogy
- The Current Problem: Chaotic Actor World
- Consistent Hashing: The Wisdom of the Round Table
- Virtual Nodes: One Person, Multiple Seats
- Sharded Router: Intelligent Mail Carrier
- Auto-Spawn: On-Demand Actor Creation
- Rebalancing: When Nodes Join or Leave
- Heartbeat & Health Checks: Knowing Who’s Alive
- Real Results: My Test Data
- What’s Next?
- Don’t Miss the Follow-up Code
Last Friday at 3 PM, I was debugging a distributed Actor system. Everything was running smoothly, but then a thought hit me: what if the Actor for user123 accidentally starts on two machines at the same time?
That question gave me chills.
Think about it - in previous articles, we’ve built the foundations: local Actors, cross-node communication, job queues, retry mechanisms. But when the system scales to 10, 20 machines, a more fundamental question emerges: how do we guarantee each Actor runs on exactly one node?
The traditional approach is to use a centralized coordinator, but that just creates a single point of failure. I didn’t want to go that route.
Then I remembered a technique that’s been crushing it in databases and caching systems - Sharding, or more precisely, Consistent Hashing.
In this article, we’ll explore how to upgrade your Actor system from “any machine will do” to “precise placement intelligence” mode.
Why Sharding? The Package Sorting Center Analogy
Before we dive into code, let’s get the concepts straight.
Imagine you’re the CTO of a major delivery company with 100 sorting centers nationwide. Millions of packages come in daily, and you need to decide which center handles each one.
The dumb approach: random assignment. Result? A Beijing package might get routed to Guangzhou for sorting, then shipped back to Beijing. Wasteful, slow, and error-prone.
The smart approach: hash the delivery address and map it to a specific sorting center. This gives you:
- Beijing packages always processed at the Beijing center
- All packages to the same address go to the same center
- No possibility of “same package being processed at two centers simultaneously”
This is the core idea of Sharding.
In our Actor system:
- Package = message sent to an Actor
- Sorting center = machine (node) in the cluster
- Delivery address = Actor ID (like
user123)
Through some algorithm, we need to guarantee: the same Actor ID always maps to the same machine.
The Current Problem: Chaotic Actor World
Before sharding, my system worked like this:
// A client wants to send a message to user123
router.send("user123@node-A", message).await;
The problem? The client has to specify @node-A - meaning you need to know which machine user123 is on.
This works at small scale, but becomes a disaster when Actor count grows:
user123is on node-A today, might be manually migrated to node-B tomorrow- If node-A crashes,
user123needs to be manually restarted on node-B - If you accidentally start
user123on two machines, everything explodes
Even worse, what we really want is:
// Client doesn't need to know where the Actor lives
sharded_router.send("user123", message).await;
The system automatically knows which machine user123 should be on and routes messages there. That’s true intelligence.
Consistent Hashing: The Wisdom of the Round Table
Now we need an algorithm that achieves:
- Stability: Same Actor ID always maps to the same machine
- Balance: Actors evenly distributed across machines, not all piled on one
- Scalability: When adding or removing machines, only a subset of Actors need migration
This is exactly what Consistent Hashing solves.
The Round Table Metaphor
Imagine a circular dining table with numbers 0 to 2^32 marked around the edge (a huge ring).
Now 5 people need to sit down for dinner:
- node-A
- node-B
- node-C
- node-D
- node-E
Each person’s seat isn’t chosen randomly - they hash their name and the resulting number is their seat position. For example:
hash(node-A)= 102938475 → sits at this position on the ringhash(node-B)= 293847562 → sits at another position- And so on
Now an Actor named user123 arrives. Where should it sit?
Simple rule: Hash the Actor ID to get a number, then move clockwise to find the first person - that’s its owner.
hash(user123) = 238974655
→ First person clockwise is node-B
→ So the user123 Actor belongs to node-B
Why Is This Algorithm So Powerful?
Stability: hash(user123) always produces the same result, so it always finds the same node.
Balance: Due to hash properties, Actors distribute roughly evenly around the ring.
Scalability: If node-F joins, it only “steals” some Actors immediately clockwise from it. Most other Actors stay on their original nodes - no massive migration needed.
If node-B crashes, Actors it managed automatically “fall to” the next clockwise node (node-C). Natural failover.
Virtual Nodes: One Person, Multiple Seats
But the above algorithm has a small issue: what if a node gets unlucky with its hash position and splits the ring very unevenly?
For example, 5 nodes should each manage 20% of Actors, but node-A gets unlucky with a tiny segment managing only 5%, while node-C lucks out with 35%. That’s unfair.
The solution is straightforward: let each node occupy not one seat, but many seats (virtual nodes).
For example:
- node-A occupies 150 positions on the ring
- node-B also occupies 150 positions
- Same for other nodes
Now even if one position is unlucky, others compensate, and ultimately each node manages a very similar number of Actors.
In code, these “virtual nodes” typically look like:
for i in 0..150 {
let virtual_key = format!("node-A:{}", i);
let hash_value = hash(&virtual_key);
ring.insert(hash_value, "node-A");
}
We generate 150 different hash values for the same physical node, all pointing to it. This achieves more uniform load distribution.
Sharded Router: Intelligent Mail Carrier
With the consistent hash ring, we can implement a ShardedRouter.
Its workflow:
User calls: sharded_router.send("user123", message)
↓
1. Calculate hash("user123") = 238974655
↓
2. Look up in hash ring → finds node-B
↓
3. Check: is node-B local or remote?
↓
4. If local → spawn or send message locally
If remote → forward via WebSocket to node-B
This router maintains two core pieces of information:
- Current node ID: Who am I (e.g., node-A)
- Hash ring: Records all nodes’ positions on the ring
Code roughly looks like:
pub struct ShardedRouter {
local_node_id: String,
hash_ring: Arc<ConsistentHashRing>,
local_actors: DashMap<String, ActorAddr>,
remote_connections: DashMap<String, WebSocketSender>,
}
impl ShardedRouter {
pub async fn send(&self, actor_id: &str, message: Message) -> Result<()> {
// 1. Find which node this Actor should be on
let target_node = self.hash_ring.get_node(actor_id);
// 2. Check if local or remote
if target_node == self.local_node_id {
// Local: spawn or send
self.local_send(actor_id, message).await?;
} else {
// Remote: forward via WebSocket
self.remote_send(target_node, actor_id, message).await?;
}
Ok(())
}
}
See? Client code doesn’t need to care which node the Actor is on - the router handles everything automatically.
Auto-Spawn: On-Demand Actor Creation
The even cooler part: we can implement auto-spawn mechanism.
Traditional mode requires manual Actor startup on a specific machine:
// Manually execute on node-B
spawn_actor::<UserActor>("user123").await;
But with the sharded router, we can do this:
// Call from any node, router handles it automatically
sharded_router.send("user123", message).await;
Router’s internal logic:
async fn local_send(&self, actor_id: &str, message: Message) {
// Check if Actor exists locally
if let Some(addr) = self.local_actors.get(actor_id) {
// Exists, send directly
addr.send(message).await;
} else {
// Doesn't exist, auto-spawn
let addr = spawn_actor_by_id(actor_id).await;
self.local_actors.insert(actor_id.to_string(), addr.clone());
addr.send(message).await;
}
}
This achieves Lazy Loading: Actors are only created when actually needed, and always on the correct node.
Rebalancing: When Nodes Join or Leave
The most complex part is Resharding.
Suppose your cluster originally has 5 machines, now:
- Scenario 1: You add a 6th machine, node-F
- Scenario 2: node-B crashes
Some Actors’ ownership will change. Previously user123 belonged to node-B, but now node-B is gone and it needs to migrate to node-C.
Rebalancing flow roughly:
1. Detect node change (join or leave)
↓
2. Update hash ring (add or remove node)
↓
3. Compare old and new rings, find Actors needing migration
↓
4. Migrate one by one:
- Spawn Actor on new node
- Transfer state from old node
- Stop Actor on old node
↓
5. Update routing table, switch traffic
This part is complex to implement, involving state synchronization, transactional consistency, etc. But the good news: most Actors don’t need migration, only those “crossing node boundaries” need to move.
The advantage of consistent hashing shines here: with traditional modulo approach (like hash(actor_id) % node_count), adding or removing nodes means almost all Actors need reassignment - that’s a disaster.
Heartbeat & Health Checks: Knowing Who’s Alive
For the router to know which nodes are alive in the cluster, we need a Heartbeat mechanism.
Each node periodically sends heartbeat messages to other nodes:
// Send heartbeat every 5 seconds
tokio::spawn(async move {
let mut interval = tokio::time::interval(Duration::from_secs(5));
loop {
interval.tick().await;
broadcast_heartbeat(&cluster_peers).await;
}
});
Other nodes receiving heartbeats update that node’s “last active time”:
peer_states.insert(node_id, Instant::now());
If a node hasn’t sent heartbeat for over 15 seconds, it’s considered dead:
let now = Instant::now();
for (node_id, last_seen) in peer_states.iter() {
if now.duration_since(*last_seen) > Duration::from_secs(15) {
// Node disconnected, trigger rebalancing
remove_node_from_ring(node_id);
}
}
This gives us adaptive cluster topology awareness.
Real Results: My Test Data
Enough theory, let’s see real numbers.
I set up a test cluster:
- 5 machines: Each running 150 virtual nodes
- 100,000 Actors: Random IDs, simulating real scenarios
- Test 1: Check distribution uniformity
Results:
node-A: 20,012 actors (20.01%)
node-B: 19,874 actors (19.87%)
node-C: 20,153 actors (20.15%)
node-D: 19,961 actors (19.96%)
node-E: 20,000 actors (20.00%)
Basically each machine handles 20k Actors, with less than 1% deviation. Virtual nodes working perfectly.
- Test 2: Adding a 6th machine
Result: Only 16.7% of Actors migrated (about 16.7k out of 100k), the other 83.3k Actors stayed put. That’s the power of consistent hashing.
- Test 3: node-B crashes
Result: The 20k Actors previously managed by node-B automatically transferred to node-C within 2 seconds. Clients only experienced brief message failures during those 2 seconds, then full recovery.
What’s Next?
Today we’ve clarified the principles and architecture of sharding, but haven’t written code yet.
In the next article, I’ll show you step-by-step:
Implement ConsistentHashRing - A reusable consistent hash ring supporting virtual nodes
Implement ShardedRouter - An intelligent router based on the hash ring
Testing & Validation - How to test distribution uniformity and migration correctness
Performance Tuning - Impact of virtual node count and hash algorithm choices
Honestly, hand-writing a consistent hash ring is pretty satisfying. You’ll discover many distributed systems’ underlying principles aren’t mysterious - people just don’t often get the chance to explore them.
Don’t Miss the Follow-up Code
This series will continue updating, from Actor basics to cluster sharding, building a production-grade distributed system step by step.
Don’t want to miss it:
- WeChat Official Account: Search “Dream Beast Programming” for instant article updates
- Tech Discussion Group: Join our Rust tech group to exchange practical experience with other developers
Remember, theory is cool, but nothing beats writing a line of code. Next article, we start the real implementation.