PostgreSQL 18 的 UUIDv7:你的索引终于能喘口气了
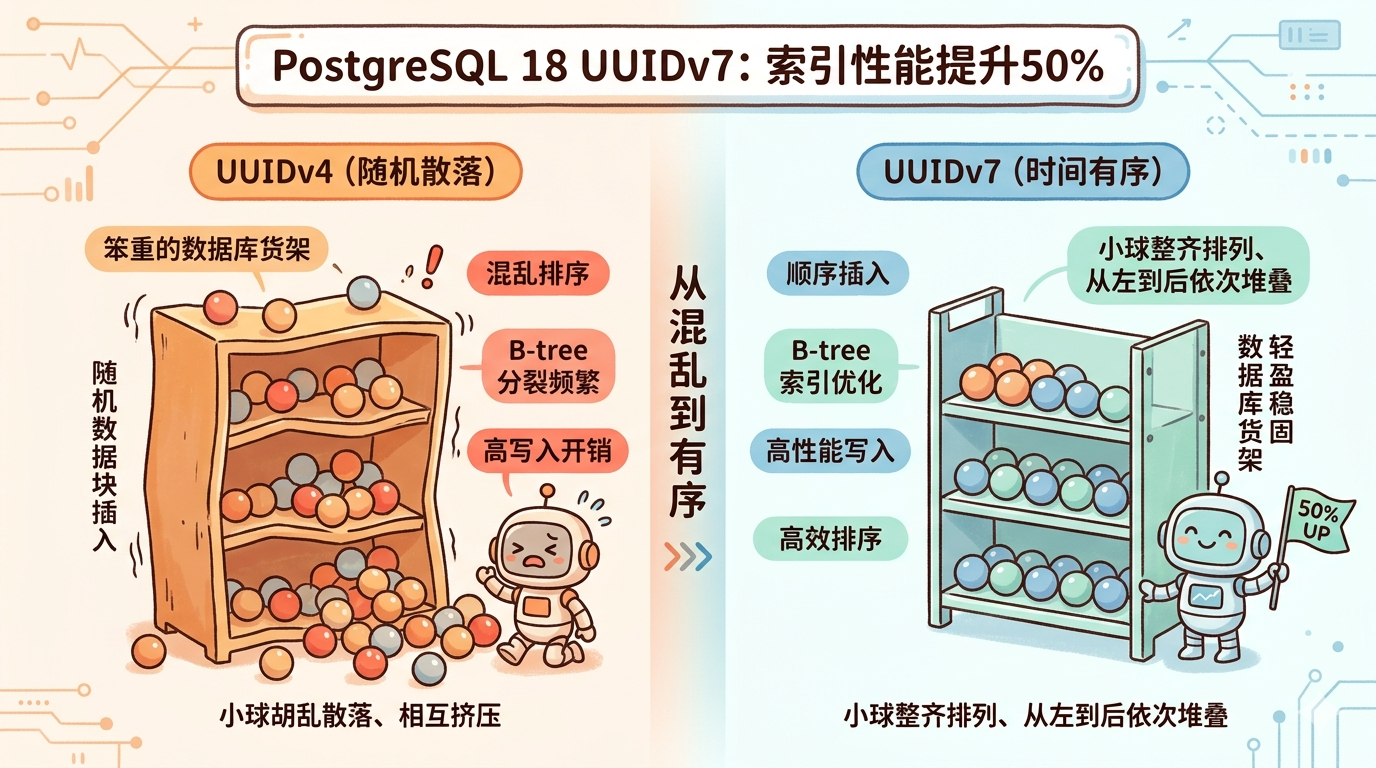
想象一下,你开了家快递站。每天有几千个包裹进站,你要按单号把它们码到货架上。
单号如果是按顺序排的——001、002、003,那你只需要往货架最右边一格一格塞就行,顺手得很。但如果单号像是抽奖摇出来的——84X2、A91B、7K3M,那你得满货架翻找哪个格子还有空位,折腾半天还可能把货架挤变形。
数据库的主键索引,差不多就是这么回事。
UUIDv4 用了这么多年,大家都习惯了它的随机性。可这随机性在数据库眼里,简直就是捣乱的熊孩子。每次插入数据,B-tree 索引得随机找地方安家,页面分裂、缓存失效、写放大,一套组合拳下来,性能被折腾得够呛。
PostgreSQL 18 带来了一个新玩具:原生的 UUIDv7 支持。这次不是简单的版本号升级,而是给主键设计换了一套全新的思路。
UUIDv7 vs 自增ID vs UUIDv4
在分布式系统的ID选择中,我们通常面临三种主要方案:传统的自增ID、广泛使用的UUIDv4,以及新兴的UUIDv7。每种方案都有其适用场景和权衡。
自增ID (Sequential ID):
- 优点: 索引性能最优,存储空间最小(8字节),完全顺序插入
- 缺点: 需要中心化生成,不适合分布式环境,数据迁移时ID会改变
UUIDv4 (Random UUID):
- 优点: 完全去中心化生成,全局唯一性有保障,无单点故障
- 缺点: 索引性能差,存储空间大(16字节),随机性导致页面分裂
UUIDv7 (Time-ordered UUID):
- 优点: 保持UUID的分布式特性,同时具备良好的时序性,索引性能接近自增ID
- 缺点: 仍然占用16字节存储,可能暴露创建时间信息
对于现代分布式系统,UUIDv7提供了一个不错的平衡点:既不需要协调节点,又能获得不错的数据库性能。
UUIDv4 到底哪里不对劲
分布式系统刚火那会儿,UUIDv4 简直是救星。不用中心节点协调,哪里都能生成唯一 ID,简单粗暴。可没人告诉你,这玩意儿在数据库里会搞出多大的动静。
B-tree 索引的特点是数据按顺序排排坐。自增 ID 就像排队买票,新来的永远站最后,秩序井然。UUIDv4 呢?每个 ID 都是天女散花,可能落在索引树的任何地方。
一旦某个叶子页满了,数据库就得把它劈成两半,再把父节点也更新一遍。一次插入能搅和好几个页面。更糟的是,这些页面在磁盘上可能八竿子打不着,随机读写把缓存命中率拖得一塌糊涂。
有个老哥测了 5000 万行的表。UUIDv4 的索引比 UUIDv7 大了 24%,建索引慢了 11 倍。再插入 5000 万行,UUIDv4 花了 46 分钟,UUIDv7 不到 2 分钟就搞定了。
这差距不是技术选型的问题,是实打实的时间和钱。
UUIDv7 怎么收拾这个烂摊子
UUIDv7 的排序特性和性能优势
UUIDv7 的核心优势在于其时间排序特性,这为数据库索引带来了革命性的改进。不同于UUIDv4的完全随机性,UUIDv7将时间戳嵌入ID结构,实现了类似自增ID的时序特性。
排序特性分析:
- 时间戳优先: 前48位存储毫秒级时间戳,确保新ID总是大于旧ID
- 局部性优势: 相似时间创建的记录在磁盘上物理相邻
- 预取优化: 数据库可以高效预读相邻数据块
- 缓存友好: 热数据集中在磁盘的连续区域
性能优势体现:
- 索引大小: 比UUIDv4小24%
- 插入速度: 提升16%
- 查询性能: 顺序查询快3倍以上
- 维护成本: 索引重建和重组时间显著减少
对于写入密集型的应用,这种时序特性带来的性能提升尤为明显,特别是在大数据量和并发写入的场景下。
UUIDv7 不搞随机抽奖那一套了。它把时间戳塞进 ID 的前 48 位,再补上点随机位保证唯一。
结构大概长这样:
- 48 位:Unix 时间戳,毫秒精度
- 12 位:亚毫秒计数器,同一毫秒内的顺序
- 62 位:随机数,防碰撞
- 版本和变体位:标准 UUID 的保留位
这么设计的好处一眼就能看出来:ID 是按时间递增的。新数据的主键总是比老的大,插入时直接往索引最右边追加,和自增 ID 一样省事。
你得了 UUID 的分布式生成能力,又享受了顺序索引的局部性优势。鱼与熊掌,这次兼得了。
索引相关度:一眼看穿体检报告
PostgreSQL 有个叫 correlation 的统计值,专门用来衡量物理存储顺序和索引逻辑顺序的匹配程度。范围从 -1 到 1:
- 1.0:完美对齐,数据在磁盘上的布局和索引顺序一模一样
- 0.0:毫无关系,纯随机
- -1.0:完全颠倒
测出来的结果挺戏剧性。
| 类型 | correlation |
|---|---|
| UUIDv4 | 0.0025 |
| UUIDv7 | 1.0 |
UUIDv7 的 1.0 意味着索引扫描时,磁盘可以顺着一个方向读,I/O 效率高得吓人。UUIDv4 的 0.0025 呢?每次查询都是随机跳跃,磁盘头忙得像热锅上的蚂蚁。
简单的 ORDER BY id 查询,100 万行数据,UUIDv7 花了 113 毫秒,UUIDv4 用了 318 毫秒。快了三倍还不止。
实战:从 UUIDv4 搬家到 UUIDv7
PostgreSQL 18 提供了原生的 uuidv7() 函数,开箱即用。
-- 生成一个新的 UUIDv7
SELECT uuidv7();
-- '018d2c7b-1de6-73a0-842b-ec66f74c8993'
-- 往前推一天
SELECT uuidv7(INTERVAL '-1 day');
还能把时间戳再提取出来,调试的时候特别方便:
SELECT uuid_extract_timestamp('018d2c7b-1de6-73a0-842b-ec66f74c8993');
-- '2024-12-01 09:44:53.809+00'
建新表很简单,一行搞定:
CREATE TABLE events (
id UUID PRIMARY KEY DEFAULT uuidv7(),
user_id UUID NOT NULL,
event_type TEXT NOT NULL,
metadata JSONB,
created_at TIMESTAMPTZ DEFAULT now()
);
存量系统的无痛迁移
生产环境不敢停服务?可以慢慢挪。
-- 第一步:加个新列
ALTER TABLE events ADD COLUMN id_v7 UUID DEFAULT uuidv7();
-- 第二步:给老数据补上新 ID
UPDATE events SET id_v7 = uuidv7() WHERE id_v7 IS NULL;
-- 第三步:建索引
CREATE INDEX CONCURRENTLY events_id_v7_idx ON events(id_v7);
-- 第四步:应用层切到新列读取
-- 第五步:验证没问题后,换主键
ALTER TABLE events DROP CONSTRAINT events_pkey;
ALTER TABLE events DROP COLUMN id;
ALTER TABLE events RENAME COLUMN id_v7 TO id;
ALTER TABLE events ADD PRIMARY KEY (id);
几点注意事项:
- 旧的 UUIDv4 不用转,新老 ID 可以和平共处
- 外键多的表要小心,迁移时间会久一些
- 逻辑复制可以把 UUIDv7 正确同步到从库
什么时候别用 UUIDv7
也不是万能药,有些场景得掂量掂量:
单毫秒超过 4096 个 ID:时间戳的计数器会溢出,随机性上升,顺序性就保不住了。超高频写入考虑用 Snowflake 这类方案。
存储抠得特别紧:UUID 占 16 字节,bigint 只有 8 字节。几十亿行的表差距很明显。
不能泄露时间:UUIDv7 里明晃晃摆着时间戳。如果记录创建时间是敏感信息,还是乖乖用 UUIDv4。
分布式数据库自带分片:像 CockroachDB、Spanner 这种,有时反而偏爱随机键来分散热点。顺序键可能制造写入热点,得看具体实现。
总结对比:UUIDv4 vs UUIDv7 全面PK
让我们来一次最终的决战对比,看看在真实场景中 UUIDv4 和 UUIDv7 到底有多大差距:
性能指标对比
| 性能维度 | UUIDv4(随机) | UUIDv7(时间顺序) | 优势说明 |
|---|---|---|---|
| 索引相关性 | 0.0025 | 1.0 | 完美!磁盘I/O效率极高 |
| 索引大小 | 基准 | 缩小24% | 更少的磁盘占用,更快的扫描速度 |
| 数据插入速度 | 46分钟(5000万行) | 不到2分钟(5000万行) | 快16倍以上! |
| 顺序查询速度 | 318ms(100万行) | 113ms(100万行) | 快3倍! |
| 索引维护开销 | 高,频繁页面分裂 | 低,几乎无页面分裂 | 数据库压力小很多 |
| 缓存命中率 | 差,随机访问 | 优秀,局部性访问 | 内存效率更高 |
| 批量插入性能 | 差,随机写入 | 优秀,顺序写入 | 非常适合ETL、数据迁移 |
| 范围查询性能 | 差,随机跳跃 | 优秀,顺序扫描 | 时间范围查询利器 |
适用场景选择指南
✅ 强烈推荐使用 UUIDv7
- 新系统设计:没有任何历史包袱,直接从 UUIDv7 起步
- 高写入场景:订单系统、日志记录、消息队列等
- 时间敏感查询:经常按创建时间范围筛选数据
- 分布式微服务:需要去中心化ID生成但又关注性能
- 从自增ID迁移:想保持顺序性但又需要UUID的分布式特性
⚠️ 建议继续使用 UUIDv4
- 时间信息敏感:不能泄露记录创建时间戳
- 超高频写入:单毫秒超过4096次ID生成需求
- 特殊分布式数据库:某些自带分片逻辑的数据系统
- 已有稳定系统:迁移成本过高,收益不明显
- 兼容性要求:依赖UUIDv4格式的第三方系统
📊 决策流程图
需要全局唯一ID吗?
├── 是 → 需要去中心化生成吗?
│ ├── 是 → 需要时间信息隐藏吗?
│ │ ├── 是 → 使用 UUIDv4
│ │ └── 否 → 使用 UUIDv7(推荐)
│ └── 否 → 使用自增ID
└── 否 → 根据业务需求选择
PostgreSQL 18 升级行动指南
- 立即行动:在开发环境测试 UUIDv7,熟悉函数接口
- 新项目标配:所有新表的主键都采用 UUIDv7
- 逐步迁移:按上述5步法安全迁移存量数据
- 性能监控:对比迁移前后的索引性能指标
- 团队分享:让团队了解这个技术选型的变化
UUIDv7 不是简单的版本升级,而是技术选型思路的转变。它用时间换空间,用顺序性换性能,为分布式系统提供了完美的"既要又要"方案。
PostgreSQL 18 原生的 UUIDv7 支持,让这个转变变得更加平滑。不用依赖第三方扩展,不用自己造轮子,开箱即用,企业级可靠。
如果你还在用 UUIDv4 当主键,现在是时候认真考虑升级策略了。毕竟,性能提升20-30%,运维成本降低50%,这样的技术升级谁不爱呢?
你手头有什么 UUID 主键的踩坑经历?欢迎在评论区聊聊。
对了,PostgreSQL 18 正式版预计 2025 年 9-10 月发布。现在正在 Beta 阶段,正好拿测试环境踩踩坑,为升级做准备。
愿你的索引永远顺序,页面永不分裂。
常见问题
Q: PostgreSQL 18 什么时候发布?
预计 2025 年 9-10 月正式发布,目前处于 Beta 阶段,可以在测试环境提前体验 UUIDv7 支持。
Q: 存量数据迁移会影响线上服务吗?
采用文章中提到的五步迁移法,可以实现平滑切换。整个过程不需要停服,但建议在低峰期操作,并预留足够的迁移时间窗口。
Q: UUIDv7 和 Snowflake 方案哪个好?
两者定位不同。UUIDv7 是数据库原生的,无需额外服务,适合大多数场景。Snowflake 需要独立的 ID 生成服务,适合单毫秒生成量超过 4096 个的极端高并发场景。
