DeepSeek突发大招:V3.2-Exp稀疏注意力机制登场,API价格再砍一半
话说昨天(9月29日)AI圈又爆了一个大新闻,DeepSeek这个"价格屠夫"又放大招了!这次他们直接推出了DeepSeek-V3.2-Exp,听这个名字就知道——这是实验性的新架构,妥妥的技术探路者。
这次升级有多猛?数据震撼人心
V3.2-Exp这次真的是技术大跃进,数据直接让人眼前一亮:推理速度提升了2-3倍,内存使用减少30-40%,训练效率直接提升50%。这是什么概念?
就像你原来跑5公里要30分钟,现在只需要10-15分钟,而且还不怎么累。更牛的是,虽然速度快了这么多,但质量一点没打折扣,在各种公开测试中的表现和V3.1-Terminus基本持平。
DSA稀疏注意力:AI界的"智能筛选器"
这次V3.2-Exp的真正杀手锏是DSA(DeepSeek稀疏注意力)机制。如果说传统注意力机制像一个事无巨细的管家,每个信息都要处理,那DSA就是一个精明的助理,只关注真正重要的内容。
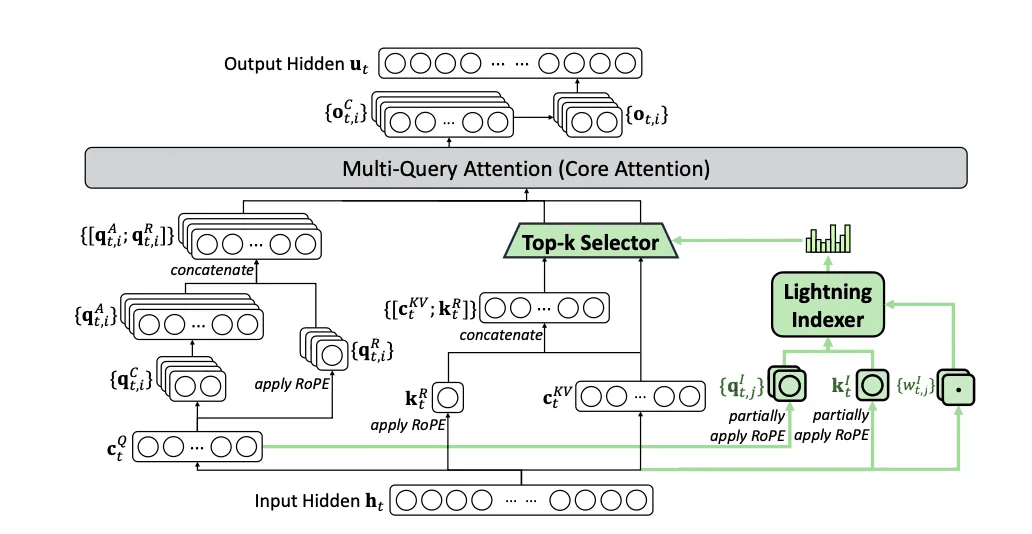
想象一下,你在看一本300页的书,传统方法是每一页都要仔细看,DSA就像一个经验丰富的读者,能迅速识别出哪些章节最重要,跳过那些次要内容,但又不会漏掉关键信息。
DSA实现了细粒度的稀疏注意力,这是业内首次做到的技术突破。简单说就是:该关注的地方死盯着不放,不重要的地方直接跳过,既保证了质量,又大幅提升了效率。这就是为什么V3.2-Exp能在保持性能的同时,速度快那么多的根本原因。
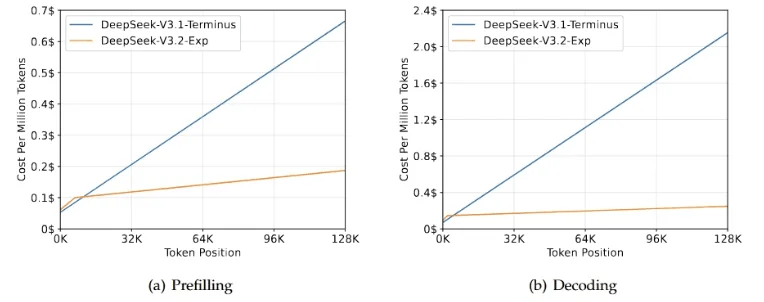
价格再次刷新底线:又降50%
最让人激动的还是价格,V3.2-Exp的API价格又降了50%以上!输入价格低至0.07美元/百万token(缓存命中时)。这是什么概念?

就像你原来买一个汉堡要30块,现在15块就够了,而且汉堡还变得更好吃了。对开发者来说,这意味着同样的预算能做更多事情,或者原来做不起的项目现在都能试一试了。
这个价格优势主要来自两个方面:一是DSA稀疏注意力大幅降低了计算成本,二是引入了缓存机制,减少了重复计算。技术进步直接转化为成本优势,这就是技术红利的最好体现。
技术架构:671B参数的高效巨兽
DeepSeek-V3.2-Exp基于671B参数构建,这个规模听起来很大,但关键是效率的提升。就像汽车发动机,不是看排量大小,而是看百公里油耗和动力输出的平衡。
更重要的是,这次还带来了完整的开源生态:MIT协议开源,完整的推理代码、CUDA内核、多平台部署方案全部开放。这就像一个厂商不仅卖给你汽车,还把图纸和维修手册都给你了,你想怎么改装都行。
和前辈V3.1的较量
最直观的对比就是和自家前辈V3.1-Terminus。在各种公开基准测试中,V3.2-Exp的表现和V3.1基本持平,但效率提升是颠覆性的。
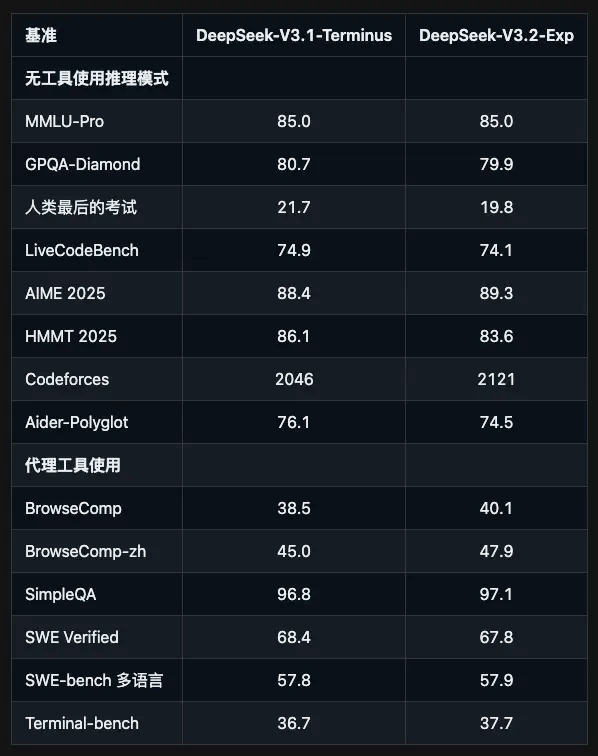
这就像两个学生考试成绩一样,但一个花了3小时,另一个只用了1小时。虽然分数差不多,但后者明显更有潜力。更何况DeepSeek还贴心地保留了V3.1的API接口,价格保持一致,方便开发者做对比测试,这个服务态度真的没得说。
开源生态的意义
这次V3.2-Exp还有一个重大意义:完全开源。DeepSeek把完整的推理代码、CUDA内核、多平台部署方案都开放了,MIT协议意味着你可以随便用。
这对开发者意味着什么?
- 成本进一步降低:可以自己部署,不依赖API调用
- 技术可控:可以根据自己的需求调整和优化
- 学习机会:能直接看到最先进的稀疏注意力机制是怎么实现的
- 生态建设:整个社区都能基于这个技术做更多创新
写在最后
DeepSeek-V3.2-Exp的发布,标志着AI技术进入了一个新阶段:不再只是性能的竞争,而是效率的革命。DSA稀疏注意力机制的突破,让我们看到了AI技术未来的一个重要方向。
更重要的是,DeepSeek用实际行动证明了:顶级的AI技术可以既便宜又开源。这种做法不仅降低了AI应用的门槛,也推动了整个行业的技术普及。
对开发者来说,现在真的是最好的时代。技术壁垒在降低,成本在下降,创新的机会在增加。剩下的,就看我们能用这些工具创造出什么样的价值了。
V3.2-Exp虽然还是实验性质,但它展示的方向很清楚:更高效、更开放、更普惠。这可能就是AI技术发展的未来趋势吧。
🔗 GitHub: https://github.com/deepseek-ai/DeepSeek-V3.2-Exp
🔗 HuggingFace: https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp
🔗 ModelScope: https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2-Exp
🔗 论文: https://github.com/deepseek-ai/DeepSeek-V3.2-Exp/blob/main/DeepSeek_V3_2.pdf