AI Agent开发实战指南:从新兵到兵王的六条黄金法则
Table of Contents
AI Agent开发实战指南:从新兵到兵王的六条黄金法则
本文总结了AI Agent开发中的核心经验和最佳实践,涵盖Prompt工程、上下文管理、工具设计等关键领域,助你快速掌握AI Agent开发精髓。
前言
在AI Agent开发领域,很多开发者经常面临这样的困惑:
“我刚开始搞AI Agent开发,感觉自己像个无头苍蝇,总觉得缺了点儿只可意会不可言传的’内功心法’。救救我,让我追上大部队吧!”
虽然有很多优秀的课程资源,如HuggingFace或伯克利大学的深度学习课程,但并非每个人都有时间和精力进行长期学习。
因此,我决定将实战中积累的宝贵经验,浓缩成这篇"心法秘籍"。这不仅仅是技术分享,更像是一份来自前线的作战手册,希望能帮你快速从"新兵"成长为"兵王"。
第一诫:给你的AI一份清晰的"圣旨",而不是让它猜谜
为什么清晰的指令如此重要?
我曾经也对所谓的"Prompt工程"嗤之以鼻,觉得那玩意儿与其说是工程学,不如说是"跳大神"。
什么"我给你100美元小费"、“我奶奶等着这个救命”、“你必须100%准确否则就完蛋”,这些小伎俩,顶多算是利用了模型某个阶段的局部漏洞,一阵风就过去了,根本上不了台面。
后来我才恍然大悟:现代的LLM,就像一个能力极强但有点"一根筋"的新兵,它不需要你那些花里胡哨的"PUA话术",它真正需要的是一份清晰、详尽、毫无矛盾的作战指令。
最佳实践建议
别再耍小聪明了,老老实实地去读读Anthropic或者Google官方的Prompt最佳实践文档。我们的经验是,把指令写得像一份给新手的工具说明书一样,直接、具体。比如,我们让Claude生成ast-grep规则时,就是把怎么用这个工具的细节掰开了、揉碎了喂给它,效果出奇的好。
一个小技巧是,你可以先让那些具备深度研究能力的LLM(比如Deep Research版的模型)帮你起草一份"圣旨"初稿。虽然还需要人工打磨,但作为起点,它已经相当扎实了。
记住,LLM是耿直的"指令跟随者",问题往往不在它,而在我们指令的模棱两可。
第二诫:别一口气喂成胖子,给AI的"记忆"减减肥
上下文工程的重要性
好,现在你有了一份完美的"圣旨"。但新的问题又来了,为什么现在大家都在谈"上下文工程(Context Engineering)“而不是"提示词工程(Prompt Engineering)"?

因为AI的"记忆”(上下文)是有限的,而且非常宝贵。
你给它的上下文太长,它就会"注意力涣散",记不住重点,就像一个听了半小时报告就开始打瞌睡的学生。这不仅会导致性能下降,还会让你的成本和延迟飙升。
上下文管理策略
我们的原则是:一开始只给最核心的"地图",然后给它一个"望远镜"(工具),让它自己去探索细节。
举个例子,我们不会把整个项目的代码一股脑塞给它,而是先给它一个项目文件列表,再给它一个read_file的工具,让它在需要时自己去读取相关文件的内容。当然,如果我们明确知道某个文件至关重要,也会提前把内容放在上下文里。
另外,那些在反馈循环中产生的日志和信息,会像滚雪球一样撑爆上下文。用一些简单的"上下文压缩"工具,能自动帮AI的"记忆"减负。把不同的信息模块化、封装起来,只给Agent当前任务绝对需要的信息,这比面向对象编程里的封装重要一百倍。
第三诫:打造一套"傻瓜式"工具箱,而不是一堆"专家级"手术刀
AI Agent工具设计原则
AI Agent的超能力,源于"调用工具"。LLM的大脑,加上一套好用的工具,再配合基础的控制流程,一个合格的Agent才算诞生。
给Agent设计工具,比给人类设计API还难。
因为人类开发者会察言观色、会读文档、会自己找歪路子。但AI Agent不行,它就是那个最"聪明"也最"爱钻空子"的实习生。你设计的工具集里但凡有一点漏洞或歧义,它就一定会以你意想不到的方式搞砸。
工具设计最佳实践
好的工具集,通常颗粒度相似,参数少而精,且类型严格。它们功能专注,经过千锤百炼。你就想象成,你在给一个虽然聪明但极易分心的初级开发者提供API,你敢有一丝马虎吗?
大多数软件工程Agent的核心工具都不到10个,比如read_file, write_file, edit_file这些,每个工具的参数也就1到3个。保持工具的"幂等性"(即多次调用和一次调用的结果相同)非常重要,能避免很多状态管理的噩梦。
第四诫:给他一个"演员",再配一个"严厉的导演"
Actor-Critic模式的应用
一个优秀的Agent系统,是LLM的创造力与传统软件的严谨性完美结合的产物。我们发现,类似"演员-评论家(Actor-Critic)“的双轨模式非常有效。
我们让"演员”(LLM)尽情发挥创造力,去编写代码、创建文件。然后,让"评论家"(一个严格的自动化系统)来评估它的"表演"是否合格。
这个"评论家"手握一堆硬指标:代码能不能编译通过?单元测试能不能跑通?类型检查和Linter有没有报警?这些都是铁面无私的"纪律委员"。
反馈循环的重要性
这也是为什么软件工程领域被AI Agent颠覆得最彻底的原因——它的反馈循环太高效了!编译器、测试、Linter这些现成的"评论家",能毫不留情地筛掉所有不合格的"表演",这使得模型在训练阶段和应用阶段都能获得极速的成长。
这个思路可以应用到任何领域。比如,一个旅游Agent规划的航班,你得先验证航班是否存在;一个记账Agent提交的报表,如果不符合复式记账原则,那它就是废品。
这个反馈循环,就是Agent的"护栏"和"纠错机制"。当它搞砸了,有时可以提醒它"喂,你上次的方案因为某某原因不行,再改改",有时则需要果断放弃,让它推倒重来。
第五诫:让AI自己"写检查",效率高到离谱
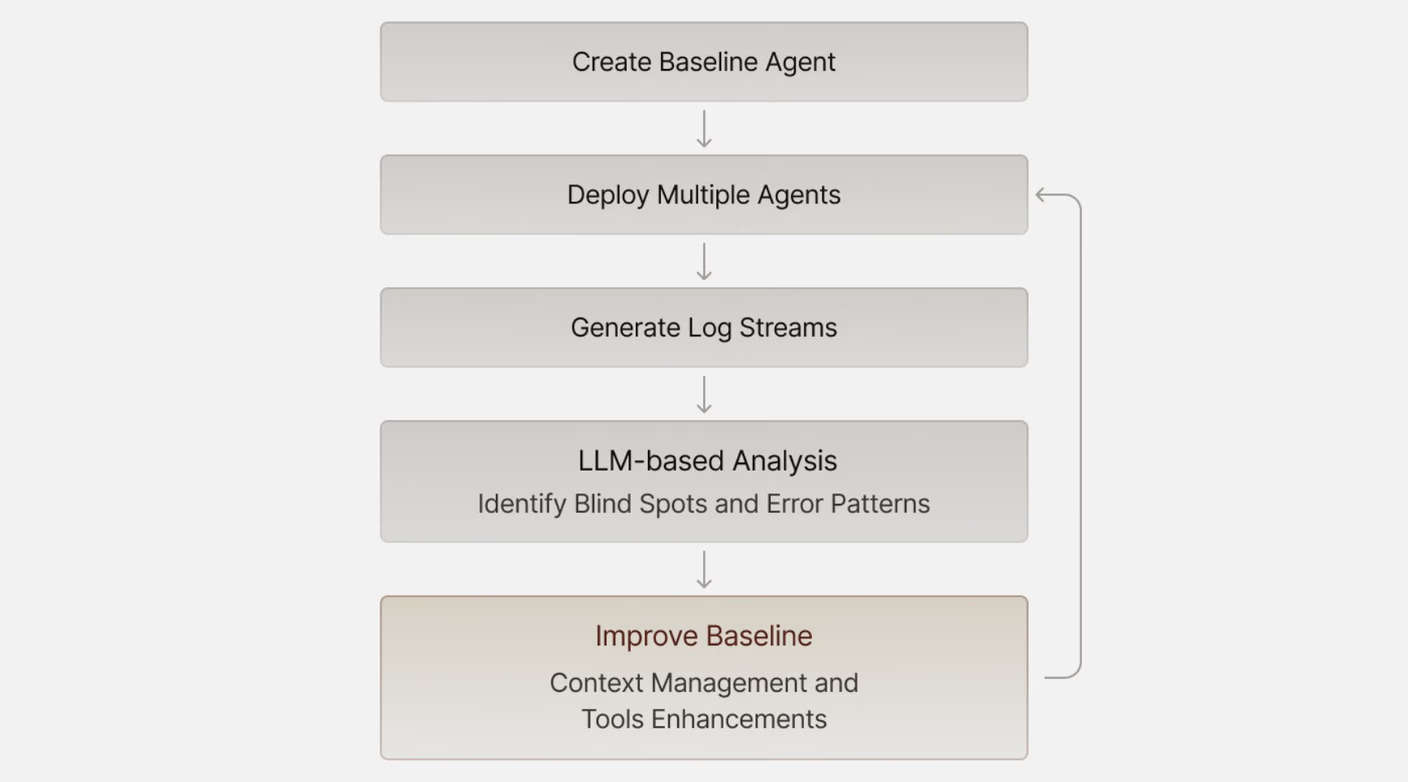
元认知循环的力量
当你有了基础的Agent和反馈循环,迭代和改进就开始了。错误分析,永远是AI/ML工程的基石。
但问题是,Agent太能干了!你可以轻松地启动几十个Agent,让它们并行处理任务,然后产生堆积如山的日志。光靠人力去复盘,无异于大海捞针。
所以,一个简单的"元认知循环"就显得异常强大:
- 建立一个基线版本的Agent。
- 让它去跑任务,收集大量的轨迹和日志。
- 用另一个LLM(向Gemini的1M上下文致敬!)去分析这些日志。
- 根据LLM的分析洞察,改进你的基线版本。
这个过程,就像是让AI自己开"总结会",自己"写检查"。它往往能帮你发现那些你做梦也想不到的系统盲点,比如工具的缺失或上下文管理的问题。
第六诫:你的AI"耍脾气"?先别骂它,查查你自己的"系统"
系统调试的重要性
现在的LLM已经非常强大了。所以,当Agent做出一些匪夷所思的"蠢事",或者完全无视你的指令时,我们很容易感到沮丧和愤怒。
但真相往往是:一个令人抓狂的问题,其根源可能不是LLM本身有缺陷,而是你的系统出了Bug。
它可能只是在用自己的方式,去"黑"掉那个它无法完成的目标。
常见问题排查
最近我就被气得破口大骂:为什么这个Agent死活不用我提供的接口去拿真实数据,非要用随机生成的假数据,我不是明令禁止了吗?!
直到我看了日志才发现,小丑竟是我自己——我忘了给它配置正确的API密钥。它试了好几次,每次都失败,最后只好选择了一个"曲线救国"的笨办法。
类似的事故还有很多,比如我们发现Agent在没有文件系统访问权限的情况下,还在拼命尝试写文件。
所以,当你的Agent开始"耍脾气",先别急着下结论说"这个模型不行",大概率是你这个"系统设计师"的锅。
总结:打造可靠的AI Agent伙伴
打造一个强大的AI Agent,不是靠找到一个万能的Prompt或者一个花哨的框架,而是回归到了软件工程最本质的东西——系统设计。
清晰的指令、精简的上下文、可靠的工具、自动化的验证循环。把错误分析当作你开发流程中与生俱来的一部分。让LLM帮助你理解你的Agent在哪里失败,然后系统性地解决它们。
我们的目标不是创造一个永不犯错的完美Agent,而是一个可靠、可恢复、能在失败后优雅地爬起来、并能被我们持续迭代改进的"伙伴"。
相关资源
关注梦兽编程微信公众号,解锁更多AI开发黑科技。