Tokencake:多智能体KV缓存调度,把延迟打到 vLLM 一半以下
北航、北大、阿里提出 Tokencake,多智能体 KV Cache 框架,用时间+空间双调度、CPU 缓冲与渐进预留,在外部函数调用场景让端到端延迟相较 vLLM 降低 47%,GPU 内存利用率提升近 17%。
Table of Contents
多智能体调用外部工具时,GPU KV Cache 常常像合租房的冰箱:等外卖的同伴把半个冰箱占满,急着开火的人反而塞不进去,速度被拖垮。北航、北大、阿里的 Tokencake 给出了一套“先搬走闲人行李、再给关键房客留格子”的玩法,在典型基准下把延迟干到了 vLLM 的 53% 左右,还把 GPU 内存利用率抬高了 16.9%。

原理速写(5 分钟看懂 Tokencake)
- 先把业务画成图:Tokencake 的前端 API 把多智能体逻辑拆成有向图(节点是智能体或工具,边是消息流),调度器据此感知谁关键、谁可等。
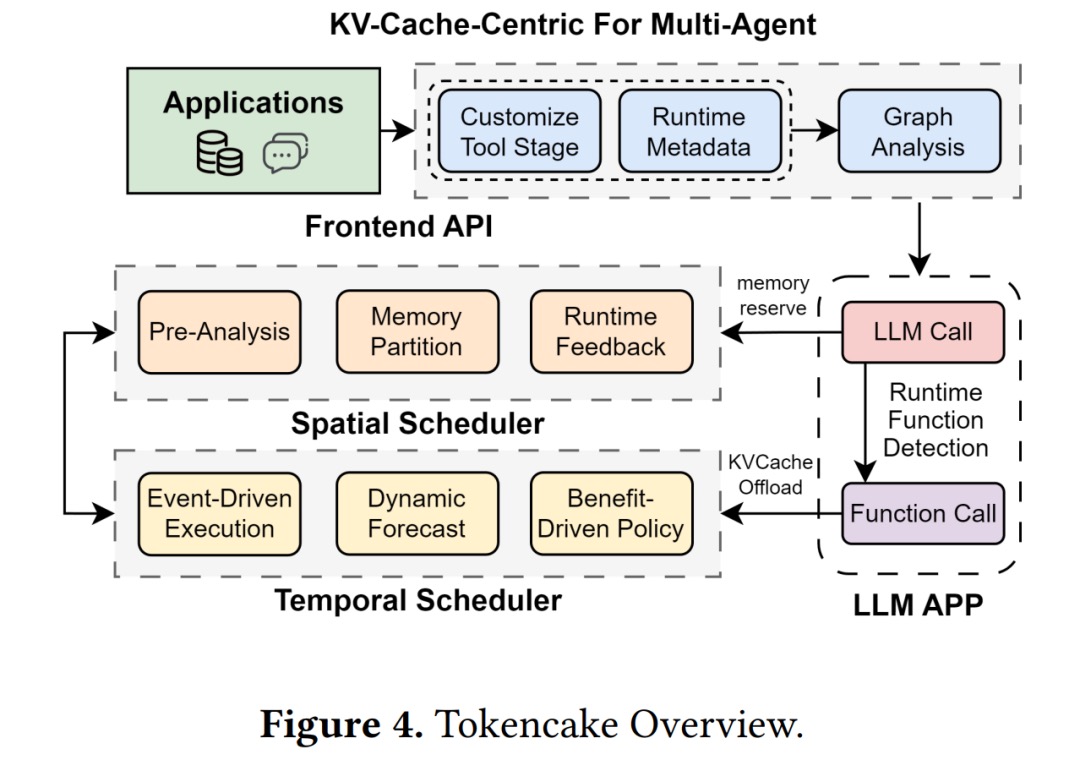
- 时间调度器:等外部调用时先“腾冰箱”:遇到长时间函数/工具调用,先把该智能体的 KV Cache 卸到 CPU,估算返回时间后再预测性地搬回 GPU,只有预期收益大于传输成本才执行。

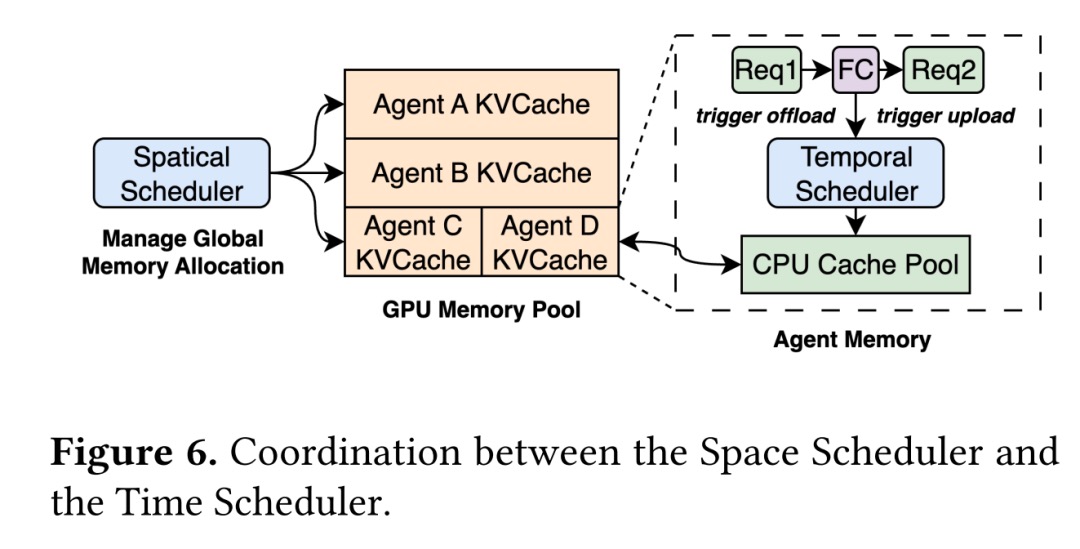
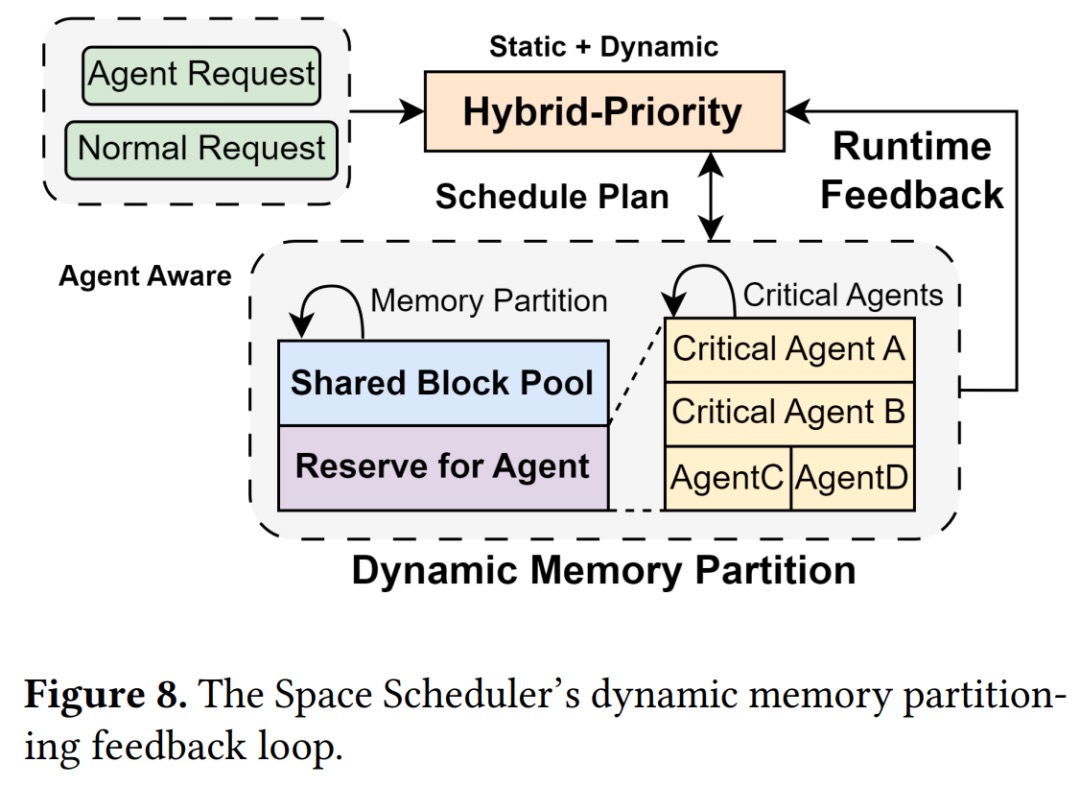
- 空间调度器:GPU 分两块:一块共享池给所有智能体,另一块预留池只给优先级高的(优先级来自“历史用量 + 业务重要度”的混合评分,动态重算)。

- 两项减摩擦小技巧:CPU 侧做块缓冲(不立刻还给 OS,后续卸载直接复用,延迟从接近秒级稳到亚毫秒),GPU 侧渐进预留(提前几个调度周期拆小单预留内存,避免一次性卡住)。
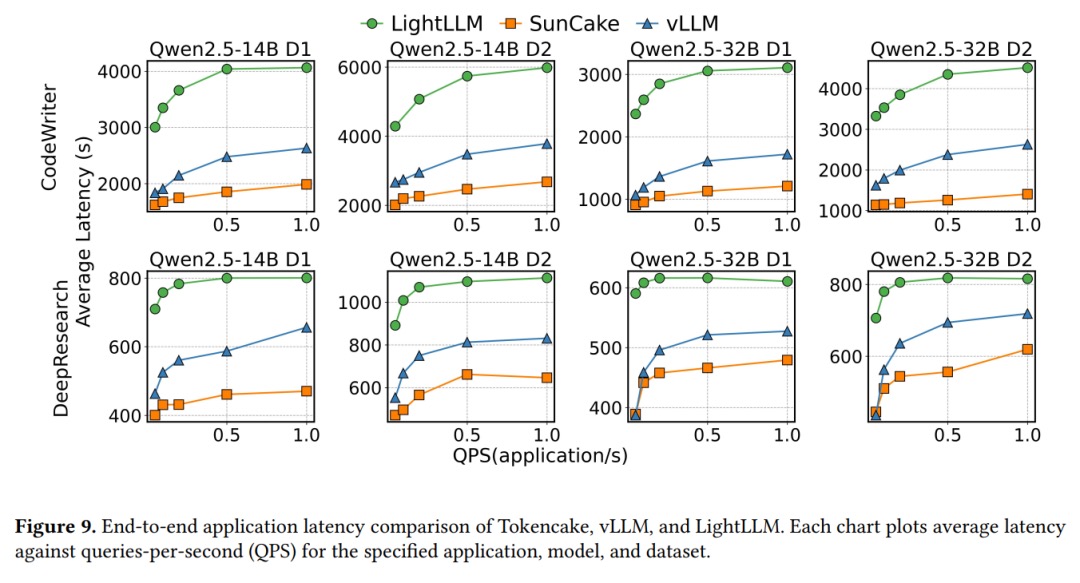
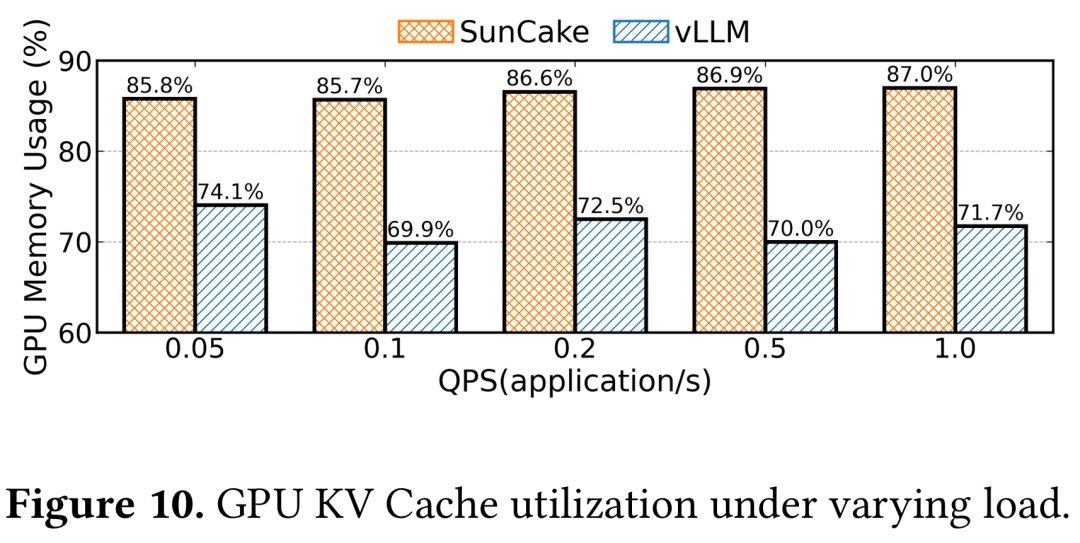
- 效果数据:在 Code-Writer、Deep-Research 等多智能体基准(请求来自 ShareGPT、AgentCode,泊松流量)下,1 QPS 高负载时端到端延迟比 vLLM 至少低 47%,GPU KV Cache 利用率最高多出 16.9%。

实战步骤(照着做就能跑)
Step 1:把业务画成节点图
先列出智能体/工具节点、消息通路、预期最长外部调用时长,把“谁不能被挤掉”写清楚。图越清晰,后面预留池越好配。Step 2:在推理循环里接入“等外部调用就卸载”逻辑
下面是一个极简模拟(Python 3.10+,纯标准库),演示如何在外部调用超过阈值时把 KV Cache 先搬去 CPU,返回前再搬回:
# tokencake_demo.py
import asyncio, random, time
GPU_BUDGET = 2 # 模拟 GPU 只够放两个 KV Cache
kv_pool = {}
async def external_call(agent: str) -> None:
await asyncio.sleep(random.uniform(0.8, 1.5))
def offload(agent: str):
kv_pool.pop(agent, None)
print(f"[{time.time():.2f}] offload {agent} -> CPU")
def load(agent: str):
if len(kv_pool) >= GPU_BUDGET:
victim = next(iter(kv_pool))
offload(victim)
kv_pool[agent] = "on-gpu"
print(f"[{time.time():.2f}] load {agent} -> GPU")
async def run_agent(agent: str):
load(agent)
print(f"[{time.time():.2f}] {agent} start tool call")
offload(agent) # 工具调用期间先挪走
await external_call(agent)
load(agent) # 预测调用结束前搬回
print(f"[{time.time():.2f}] {agent} resume decode")
async def main():
await asyncio.gather(*(run_agent(f\"agent-{i}\") for i in range(3)))
asyncio.run(main())
期望输出示例(可直接运行 python3 tokencake_demo.py):
[... ] load agent-0 -> GPU
[... ] agent-0 start tool call
[... ] offload agent-0 -> CPU
[... ] load agent-1 -> GPU
[... ] ...
Step 3:给关键智能体配预留池比例
如果某个规划/审核类智能体对全局质量最关键,就给它预留固定比例 GPU 块,其余走共享池。用“历史最大 KV 占用 + 业务权重”算出 0~1 的混合分数,再按分数分配配额。Step 4:压测观测点
关注三件事:外部调用的真实耗时分布(预测模型需要它),GPU/CPU KV 占用曲线是否抖动(如果抖,调高预留池或放宽渐进预留步长),以及是否出现“搬来搬去反而更慢”(传输成本大于收益时要禁止卸载)。
常见坑与对策
- 预测偏差:外部调用抖动大时先用保守阈值(只卸载超过 P95 耗时的调用),否则会频繁搬运。
- CPU 内存被吃爆:做块缓冲时加上上限,超过就直接丢回 OS,避免长尾请求把内存顶满。
- GPU 分区震荡:total_reserve_ratio 不要随使用率频繁跳动,可设“高/低水位 + 缓慢调节因子”。
- 批量分配卡顿:渐进预留的步长太大也会堵;改成多周期、小份额预留。
- 指标只看吞吐忽略延迟:多智能体场景延迟更关键,监控里分开记录“外部调用等待”“回迁时间”“解码时间”。
总结与下一步
- Tokencake 用“时间卸载 + 空间预留”两板斧解决多智能体的 KV Cache 争抢问题,让外部调用期间的闲置缓存不再浪费 GPU。
- CPU 块缓冲 + 渐进预留把内存分配的抖动压到亚毫秒级,是它比常规实现更平滑的关键。
- 实测在高负载(1 QPS)下,端到端延迟比 vLLM 至少低 47%,GPU 利用率最高多出 16.9%。
下一步可做:
- 把你现有的多智能体流程画成节点图,标出最长外部调用节点并设卸载阈值。
- 给最关键的 1~2 个智能体设预留池比例,观察延迟曲线是否变平。
- 参考原论文(https://arxiv.org/pdf/2510.18586)进一步把预测模型和阈值调优到业务场景。