智谱GLM-4.5发布:挑战GPT-4的AI代码能力新标杆
智谱GLM-4.5发布:挑战GPT-4的AI代码能力新标杆
引言:AI格局的新变革
就在所有人都以为AI格局已定时,牌桌被一个新玩家掀了。
今天,别再只盯着OpenAI和谷歌了,把目光转向东方,智谱AI带着他们最新的"王炸"——GLM-4.5系列模型,正式向全世界宣告:“我,全都要!”
这不是一次常规升级,这可能是一次AI能力的"物种跃迁"。过去,我们总在纠结,哪个模型数学好,哪个模型代码强,哪个模型更会聊天。而GLM-4.5给出的答案是:小孩子才做选择,成年人的世界里,顶级的能力我必须全部拥有。
GLM-4.5系列模型概览
认识一下新来的"怪物"
这次智谱AI一口气放出了两兄弟:
- GLM-4.5: 完全体的"六边形战士",拥有3550亿总参数,是本次的绝对主角,对标的就是全球最顶尖的那几个名字。
- GLM-4.5-Air: 轻量级的"敏捷刺客",参数更少,响应更快,但实力同样不容小觑。
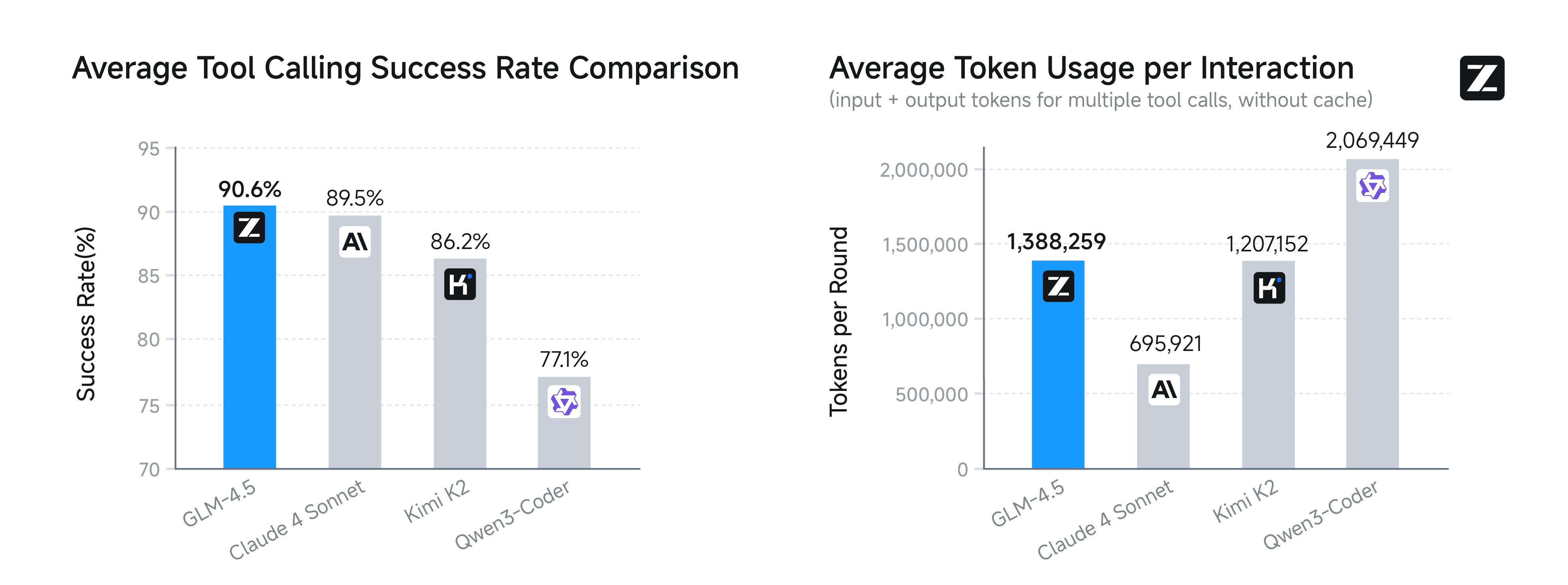
它们最可怕的地方,在于一个叫做"智能体(Agent)“的能力。如果说以前的AI是在跟你"对话”,那GLM-4.5就是在"替你办事"。
革命性的代码生成能力
它不止会写代码,它在"建工厂"!
别再拿"能写个排序算法"来衡量AI了,那都是"石器时代"的玩法。
GLM-4.5的代码能力已经进化到了"创世纪"的级别。在发布的技术演示中,它就像一个经验丰富的全栈工程师,你只需要动动嘴,它就能:
- 开发一个完整的网站: 从前端界面到后端数据库,一条龙服务。演示中的"宝可梦图鉴"网站,就是它从零开始构建的,用户体验和功能完整度堪比专业团队作品。
- 制作一个游戏: 像"Flappy Bird"这样的小游戏,它能直接生成可玩的HTML文件,让你在对话框里当场开玩。
- 设计精美的PPT: 你丢给它一份PDF文档,或者只给一个主题,比如"介绍环法自行车赛冠军Pogačar的成就",它能自己上网搜集资料、找图片,然后生成一份图文并茂、设计感十足的PPT。
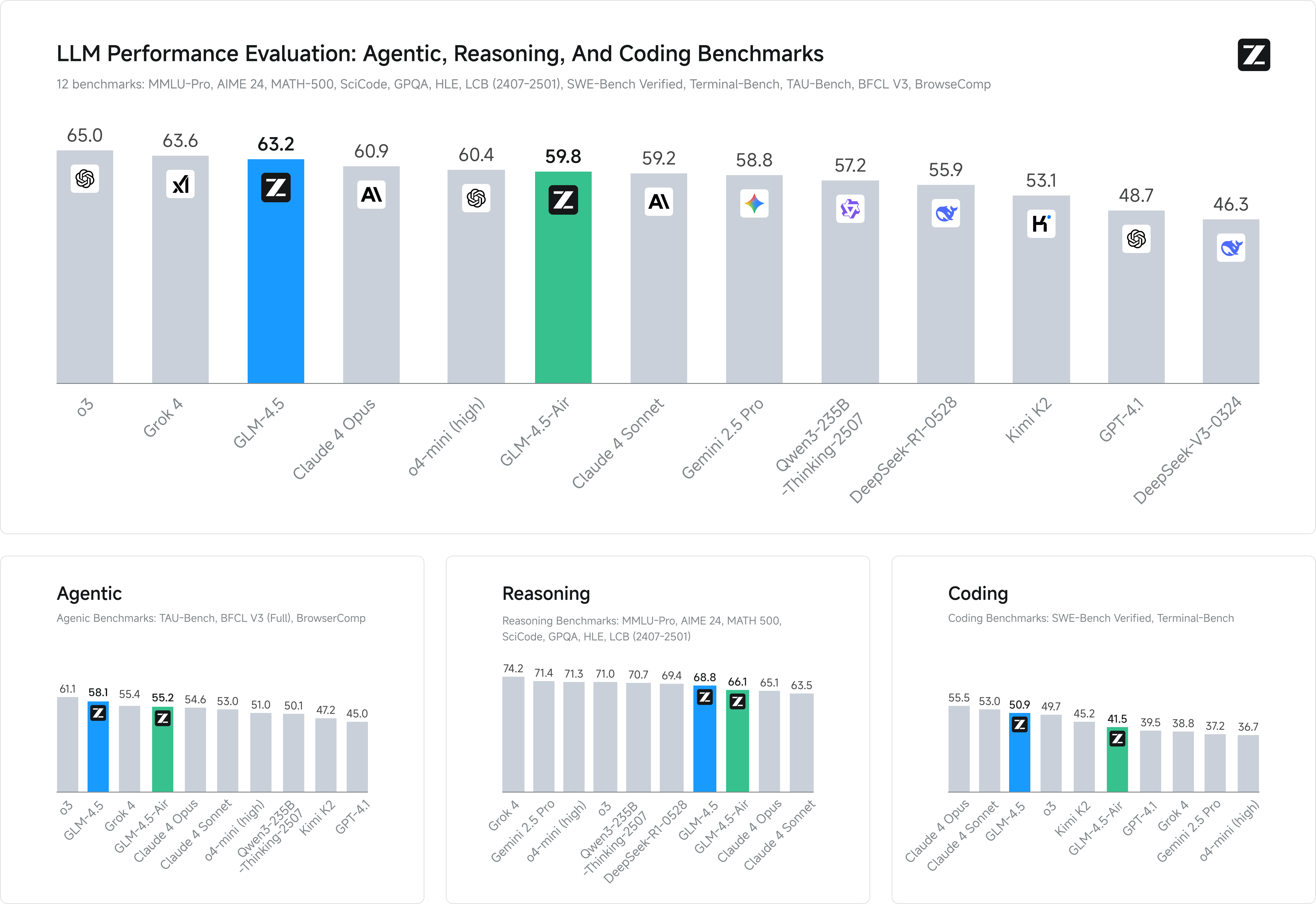
代码能力测试成绩
在专业的代码能力测评(SWE-bench)中,GLM-4.5的成绩(64.2%)已经超过了像Claude 4 Sonnet(70.4%对配置要求更高)和**GPT-4.1(48.6%)**这样的强大对手,在同等规模的模型里,它的表现堪称恐怖。
强大的推理能力
推理能力:它像个"老谋深算"的军师
这次GLM-4.5内置了一种"思考模式"。当你遇到复杂的数学题、科学问题或逻辑谜题时,它不再是凭"语感"瞎猜,而是会像一个真正的专家一样,启动深度思考,一步步推导演算,最后给出答案。
在**AIME(美国数学邀请赛)和GPQA(谷歌出品的高难度问答)**这类考验智商天花板的测试中,它的表现稳居第一梯队,证明了它不光"能干活",还"有脑子"。
全球AI模型排名对比
硬碰硬!全球AI华山论剑,它排第几?
当然,说得再好,不如直接上战绩。
智谱AI这次非常"讲武德",直接把GLM-4.5拉到了一个包含12项权威基准测试的"角斗场"里,和来自OpenAI、Anthropic、谷歌、阿里、月之暗面等全球顶级玩家的旗舰模型进行了一场全方位大比拼。
结果如何?
- GLM-4.5,综合排名全球第三。
- GLM-4.5-Air,综合排名全球第六。
这意味着什么?这意味着在全球AI的牌桌上,已经有了一个不容忽视的中国玩家,它用实力证明了自己,不是"另一个GPT",而是真正的"顶级挑战者"。
技术架构创新
揭秘"黑科技":它为什么这么强?
强大的能力背后,是技术的革新。智谱这次也亮出了他们的"武功秘籍":
更聪明的"专家混合(MoE)“架构: 如果把普通模型比作一个全科医生,MoE就是组建了一个"专家委员会”。GLM-4.5不仅用了MoE,还把它建得"更高"了(更多的网络层数),让模型思考得更深。就像一个公司,不仅专家多,层级管理也更高效,决策质量自然就高。
独门训练秘法
slime: 为了训练出强大的"智能体",智谱自研了一套强化学习框架,代号slime(史莱姆)。这个框架解决了训练大型智能体时效率低下的核心痛点,通过一种"异步解耦"的模式,让数据生成和模型训练互不干扰,把GPU的性能压榨到极致。
未来展望与影响
风暴已至,你准备好了吗?
GLM-4.5的发布,不仅仅是一个新模型的诞生,它更像一个信号:AI正在从"聊天机器人"进化为"数字雇员"和"创意伙伴"。它能做的事情,已经远远超出了我们的想象。
从今天起,我们评价一个AI,或许不应再问"它知道什么",而应该问"它能做什么"。
智谱AI已经将GLM-4.5的API、开源模型权重和本地部署指南全部公开。对于开发者和企业来说,这是一个前所未有的机遇。而对于我们每一个普通人来说,这既是挑战,也是一次重新思考如何与AI共存的契机。
一个新的时代,已经拉开序幕。
关注梦兽编程微信公众号,解锁更多黑科技。