简历上只写'会Python'?2026年面试官已经不吃这套了

Table of Contents
2026年了,你投了100份Python简历,每份都写着"熟悉Python",然后呢
说个真事。我一个朋友去年转行学Python,三个月速成,简历上写了"精通Python",投了上百份简历。结果呢?两个面试机会,都在第一轮技术面挂了。
他跟我抱怨:Python不是最火的语言吗?怎么市场上找工作这么难?
我看了眼他的简历和GitHub,一下子明白了。他的项目全是"学生管理系统"“爬虫抓取豆瓣Top250"“Todo List”。代码能跑,但你让他解释一下GIL是什么、asyncio和多线程怎么选、为什么生产环境不能用print调试,他就卡壳了。
这就是2026年Python求职市场的现实:会Python的人多如牛毛,但能用Python干活的人,公司还是抢着要。
差别在哪?下面这9个方向,我一个一个给你拆。
“会Python"为什么变成了白开水
打个比方。十年前你说"我会开车”,这是个技能。现在呢?驾照几乎人手一本,你说你会开车,HR连头都不会抬。人家想听的是:你能不能跑长途?暴雨天你敢不敢上高速?爆胎了你知道怎么靠边停车换备胎吗?
Python也一样。根据2026年的招聘数据,Python开发者的平均年薪在美国市场是$99K到$212K,但这个范围之所以这么大,是因为"Python开发者"这四个字本身太模糊了。写个脚本自动改文件名的人是Python开发者,设计分布式AI推理管线的人也是Python开发者。薪资差3倍,技能树差的可不止3倍。
面试官现在问的早就不是"你会不会Python"了。他们想知道你能用Python交付什么,你的代码扛不扛得住生产环境。你写的API,一万个人同时访问会不会崩?
接下来拆解的9个方向,就是从"会开车"到"能当老司机"的升级路径。
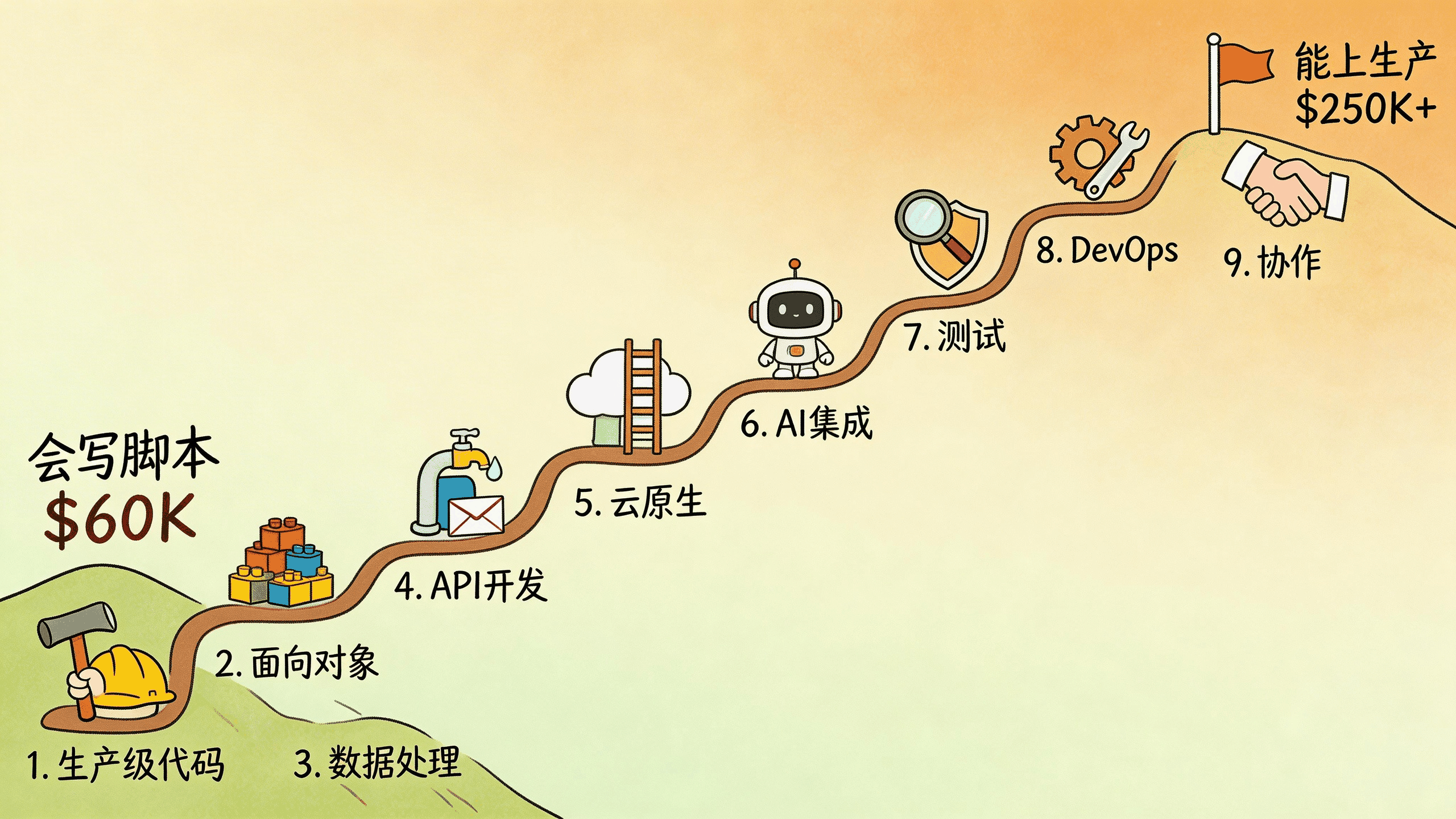
一、生产级代码:你的代码能上战场吗

很多人的Python代码就像大学生做的课程设计——能演示,不能用。
区别在哪?看几个细节:
类型提示不是装饰品。 Python是动态类型语言,但到了大型项目里,没有类型提示的代码就像没有路标的高速公路。你自己写的时候觉得一清二楚,同事接手的时候想骂人。
# 这样写,三个月后你自己都看不懂
def process(data, flag):
if flag:
return data.split(",")
return len(data)
# 这样写,意图一目了然
def process_input(data: str, should_split: bool) -> list[str] | int:
if should_split:
return data.split(",")
return len(data)
异常处理不是套个try/except就完事。 我见过最离谱的代码,整个函数用一个try/except: pass包起来。出了错?静默吞掉,日志里干干净净。等到生产环境出问题,排查起来像在黑屋子里找黑猫。
生产级的做法是建立异常层级,用上下文管理器处理资源,用结构化日志替代print:
import logging
from contextlib import contextmanager
logger = logging.getLogger(__name__)
@contextmanager
def database_connection(config: dict):
conn = None
try:
conn = create_connection(config)
yield conn
except ConnectionError as e:
logger.error("数据库连接失败", extra={
"host": config.get("host"),
"error_type": type(e).__name__
})
raise
finally:
if conn:
conn.close()
配置管理别硬编码。 把数据库密码写在代码里这种事,说出来你可能觉得搞笑,但每年都有公司因为这个上新闻。用Pydantic Settings管理配置,环境变量分环境,这是基本功。
公司在乎这些,是因为你笔记本上跑得好好的代码,到了服务器上可能因为内存泄漏、竞态条件、没处理的边界情况直接炸掉。懂Python的内存模型、GIL的局限性、asyncio和multiprocessing的适用场景,这些才是值钱的技能点。
二、面向对象:别背设计模式了,学会什么时候不用类
Python社区有个老笑话:Java程序员转Python,写出来的代码还是Java风格,到处都是类,到处都是继承链。
面试官其实很在意你能不能分辨"该用类"和"不该用类"的场景。一个简单的数据容器,用dataclass就够了,没必要写一个完整的类;一个只有一个方法的类,通常写成函数更清晰。
真正要掌握的是这些:
组合优于继承。 继承链超过两层,维护起来就像拆俄罗斯套娃。用Protocol定义接口,用依赖注入组装行为:
from dataclasses import dataclass
from typing import Protocol
class Notifier(Protocol):
def send(self, message: str) -> None: ...
@dataclass
class SlackNotifier:
webhook_url: str
def send(self, message: str) -> None:
# 发送到Slack
...
@dataclass
class OrderService:
notifier: Notifier # 注入,不继承
def place_order(self, order_id: str) -> None:
# 处理订单逻辑
self.notifier.send(f"订单 {order_id} 已创建")
魔术方法要会用。 __repr__让调试不抓瞎,__eq__让比较有意义,__enter__和__exit__让资源管理自动化。这些不是炫技,是实打实的工程能力。
检验标准很简单:给你一个500行的脚本,你能不能拆成几个模块化的、可测试的组件,而不是搞出一个"上帝类"把所有逻辑都塞进去?
三、数据处理:从"能读CSV"到"能扛住一个亿”
大部分Python教程教数据处理,上来就是pd.read_csv("data.csv")。数据量小的时候没问题。但你的数据文件有10个GB呢?电脑直接卡死。
2026年的数据处理技能栈已经进化了:
Polars来了。 用Rust写的DataFrame库,多核并行,比Pandas快5到10倍。同样的分组聚合操作,Pandas在1GB数据上要跑4.6秒,Polars只要1秒。内存占用也更少,因为底层用了Apache Arrow的列式存储格式。
import polars as pl
# Polars的惰性求值 - 先描述操作,最后一次性执行
result = (
pl.scan_csv("huge_dataset.csv")
.filter(pl.col("amount") > 1000)
.group_by("category")
.agg(pl.col("amount").mean().alias("avg_amount"))
.sort("avg_amount", descending=True)
.collect() # 这一步才真正执行
)
数据校验不能等到出bug才做。 用Pydantic或Pandera给数据定义schema,脏数据在进入系统的那一刻就被拦住,而不是三天后有人发现报表数字对不上才开始排查。
SQL不能丢。 ORM好用,但不能成为你不学SQL的借口。复杂查询、索引优化、执行计划分析,这些事ORM帮不了你。SQLAlchemy 2.0是当前的标准选择。
ETL管线要会设计。 Apache Airflow、Prefect、Dagster,这些工具负责把数据处理流程编排成可监控、可重试的管线。你在公司里跑一次性脚本处理数据的时代过去了。
四、API开发:2026年写后端基本就是写API
现在的后端开发,说白了就是写API。前端一个请求过来,你返回JSON。移动端一个请求过来,你还是返回JSON。
FastAPI已经是行业标准了。 异步支持、自动生成OpenAPI文档、Pydantic数据校验一条龙。Flask还能用,Django适合做大型单体应用,但新项目十有八九选FastAPI。
from fastapi import FastAPI, HTTPException, Depends
from pydantic import BaseModel
app = FastAPI()
class UserCreate(BaseModel):
username: str
email: str
@app.post("/users", status_code=201)
async def create_user(user: UserCreate):
# Pydantic自动校验请求体
# 如果email格式不对,还没进函数就返回422了
existing = await find_user_by_email(user.email)
if existing:
raise HTTPException(status_code=409, detail="邮箱已注册")
return await save_user(user)
但光会写CRUD不够。面试官还会问你:
- 怎么做认证?JWT怎么刷新token?OAuth2的授权码流程画得出来吗?
- 一万并发打过来怎么办?限流策略是什么?
- 你的服务挂了,上下游受多大影响?熔断机制了解多少?
API不是孤岛。消息队列(RabbitMQ、Kafka)、服务发现、链路追踪,这些是你在微服务架构里绕不开的话题。
五、云原生:代码写完才走了一半路
我见过一种开发者:本地跑得好好的,一部署就炸。问他Docker用过没,说"看过教程还没试过"。
2026年了,代码写完只是完成了一半。另一半是让它跑在云上。
Docker是入门票。 多阶段构建优化镜像大小、理解layer缓存机制、写出合理的Dockerfile,这些是基本功:
# 多阶段构建:先安装依赖,再复制代码
# 改了代码不用重新装包,利用缓存加速
FROM python:3.12-slim AS builder
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
FROM python:3.12-slim
WORKDIR /app
COPY --from=builder /usr/local/lib/python3.12/site-packages /usr/local/lib/python3.12/site-packages
COPY . .
CMD ["uvicorn", "main:app", "--host", "0.0.0.0"]
Serverless要会玩。 AWS Lambda、Google Cloud Functions、Azure Functions。冷启动怎么优化、依赖怎么打包、本地怎么测试,这些坑踩过一遍才算入门。
基础设施即代码。 用Python的Pulumi或AWS CDK来定义云资源,比在控制台上点点点靠谱得多。环境一致性、版本管理、回滚能力,全靠这个。
说穿了:云上的Python和本地的Python是两种东西。你得处理无状态设计、配置CloudWatch日志、还得考虑每一行代码背后的账单。Lambda每跑一次都收钱,你的代码效率直接跟公司支出挂钩。
六、AI集成:不用当科学家,但得会当包工头
2026年最赚钱的Python岗位是什么?AI/LLM工程师,年薪$140K到$250K+。
好消息是,你不需要发论文、推公式。大部分公司不是在从头训练模型,他们是在把现有的AI能力集成到业务系统里。说白了,你负责搬砖和组装,模型架构师负责画图纸。
LLM编排是核心技能。 LangChain、LlamaIndex,或者直接调OpenAI和Anthropic的API。怎么写好prompt、怎么做对话记忆管理、怎么控制token消耗,这些是日常工作。
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field
class ProductReview(BaseModel):
sentiment: str = Field(description="正面/负面/中性")
key_points: list[str] = Field(description="核心观点")
confidence: float = Field(description="置信度0-1")
parser = PydanticOutputParser(pydantic_object=ProductReview)
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个产品评价分析助手。{format_instructions}"),
("human", "分析这条评价:{review}")
])
chain = prompt | ChatOpenAI(model="gpt-4") | parser
向量数据库要会用。 RAG(检索增强生成)是当前企业级AI应用最常见的模式。Pinecone、Weaviate、pgvector,你至少得熟一个。原理不复杂:把文档切块、转成向量、存起来,用户提问时检索相关内容喂给LLM。
模型部署的基本功。 用FastAPI封装模型接口,搞清楚批量推理和实时推理的区别,知道基本的MLOps流程。你不需要自己训练模型,但你得能把别人训好的模型变成可用的服务。
七、测试:你敢不敢裸奔上线
我跟一些初级开发者聊过,问他们为什么不写测试。最多的回答是"没时间"和"功能都做不完哪有空写测试"。
这就好比说"我忙着赶路哪有空看地图"。结果跑了三天发现方向反了。
pytest是标配。 不用unittest,太啰嗦了。pytest的fixture、参数化、插件生态,用过就回不去了:
import pytest
from httpx import AsyncClient
from app.main import app
@pytest.fixture
async def client():
async with AsyncClient(app=app, base_url="http://test") as ac:
yield ac
@pytest.mark.parametrize("email,expected_status", [
("valid@test.com", 201),
("not-an-email", 422),
("", 422),
])
async def test_create_user(client, email, expected_status):
response = await client.post("/users", json={
"username": "testuser",
"email": email
})
assert response.status_code == expected_status
测试得跟写代码同步进行。 最好的习惯是边写边测。改了一行代码,跑一下测试。CI管线里配好GitHub Actions或GitLab CI,每次push自动跑测试、跑linting(ruff比flake8快得多)、跑类型检查(mypy)。
覆盖率不要追数字,要追关键路径。100%覆盖率不代表没有bug,但核心业务逻辑的覆盖率低于80%,大概率有坑等着你。
八、DevOps和自动化:能帮团队省时间的人最值钱
Python在DevOps领域的地位很稳。运维自动化、日志解析、工具链集成,Python写脚本的体验确实好用。
但这里说的不是写个脚本改改文件名那种自动化。而是:
- 用Prometheus客户端库暴露自定义指标,搭建监控告警
- 用GitPython自动化代码审查流程,或者写release管线
- 用Ansible编排服务器配置,或者直接用Python脚本做服务器批量操作
能把重复劳动自动化掉的人,在团队里地位很高。 想象一下,每周大家要花4小时做一个手动操作,你写了个脚本把它变成了一键执行。一年下来给团队省了200个小时。这种贡献在绩效评估里是实打实的加分项。
九、协作能力:Git不只是push和pull
技术能力到了一定水平后,拉开差距的往往是协作能力。
Git工作流要熟练。 Feature branching、rebase和merge的区别和取舍、语义化版本号。这些不是理论,是每天要用的东西。
写PR要会讲故事。 一个好的PR描述包括:这个改动解决什么问题、为什么选这个方案、需要关注哪些风险点。而不是一行"fix bug"。
代码审查是双向的。 能写出好代码很重要,能指出别人代码里的问题同样重要。审查代码不是挑风格问题,是找逻辑漏洞。
依赖管理跟上时代。 Poetry用了好几年了,但现在uv(用Rust写的Python包管理器)的速度快得离谱。lock文件保证可复现,再配合pip-audit做依赖安全扫描,这套组合拳是标配。
学习路线:四个阶段从零到能面试

光知道要学什么不够,还得知道按什么顺序学。下面这个路线是根据当前行业的实际招聘要求整理的。
第一阶段:打地基(第1-30天)
目标:能独立写脚本,遇到报错能自己排查。
核心内容:变量和数据类型、控制流(if/for/while/列表推导)、函数(参数、返回值、作用域)、数据结构(列表、字典、集合、元组的使用场景)、文件读写(文本、CSV、JSON)、异常处理、虚拟环境(venv或uv)。
练手项目建议:
- 带错误处理的计算器
- 根据用户偏好生成密码的工具
- Downloads文件夹自动整理脚本
- CSV数据清洗(去重、处理缺失值)
每天1-2小时,跟着教程敲完之后自己改,改到能跑出不一样的结果。如果一个概念你没法用大白话给别人讲清楚,那你还没真正理解。
第二阶段:连接真实世界(第31-60天)
目标:从孤立脚本进化到能和外部系统交互的工具。
核心内容:面向对象编程(类、继承、魔术方法)、模块和包(怎么组织自己的代码)、API调用(requests库、HTTP方法、JSON解析)、正则表达式(文本提取和验证的利器)、数据库基础(SQLite本地存储、SQL基础语法)、Git工作流(commit、branch、merge、GitHub操作)。
练手项目建议:
- 天气看板:调API获取数据,存到SQLite,展示历史趋势
- 命令行记账工具:数据持久化、分类统计
- 爬虫:抓取招聘信息或商品价格(遵守robots.txt)
- 批量邮件发送工具
每个项目写完都push到GitHub,认真写README。这些就是你作品集的起点。
第三阶段:选方向,练专业(第61-90天)
该选路线了。三条主流方向选一条深入:
方向A - 后端开发: FastAPI或Flask深入学习、SQLAlchemy ORM + Alembic做数据库迁移、JWT认证和密码哈希、pytest写API测试、Docker容器化 + Gunicorn + Nginx反向代理部署。
方向B - 数据科学/AI: NumPy向量化运算、Pandas数据清洗和分组操作、Matplotlib/Seaborn做可视化、Scikit-learn做回归/分类/聚类、Jupyter Notebook写可复现的分析报告。
方向C - 自动化/DevOps: 系统自动化脚本(SSH用Paramiko、FTP操作)、Excel/Word自动生成(OpenPyXL、python-docx)、CI/CD管线(GitHub Actions、pre-commit hooks)、AWS基础操作(S3、Lambda、EC2)。
这个阶段的终点是一个完整的毕业项目。不是那种跟着教程做的,是你自己从头到尾设计、开发、部署的。
第四阶段:进阶打磨(第4-6个月)
目标:知道"为什么",不只是知道"怎么做"。
高级话题:asyncio异步编程和并发模式、设计模式在Python里的实际应用(Factory、Strategy等)、性能优化(cProfile分析、内存优化、Cython基础)、高级测试(Hypothesis做属性测试、变异测试)、给开源项目提PR。
同时开始打磨作品集:用新学到的知识重构之前的项目、写技术博客分享你的解决方案、在社区里活跃起来。
薪资参考:技能方向决定天花板
同样写Python,薪资差距大得吓人。下面是2026年美国科技中心的数据:
| 岗位 | 经验要求 | 年薪范围(美元) | 关键技能 |
|---|---|---|---|
| 初级Python开发 | 0-2年 | $60K-$90K | 基础Python、Git、SQL |
| 后端工程师 | 2-4年 | $90K-$140K | FastAPI/Django、PostgreSQL、Docker、AWS |
| 数据工程师 | 2-5年 | $95K-$150K | Pandas、Spark、Airflow、SQL |
| ML工程师 | 3-5年 | $120K-$180K | Scikit-learn、TensorFlow/PyTorch、MLOps |
| AI/LLM工程师 | 3-6年 | $140K-$250K+ | LangChain、RAG、向量数据库、模型微调 |
国内市场虽然数字不同,但趋势一致:越靠近AI和云原生方向,天花板越高。
最后说句实在的
Python这门语言的入门门槛确实低。正因为低,才有那么多人涌进来。当所有人都站在同一个起跑线上时,决定谁能拿到offer的,是你能不能写出别人看得懂的代码,你的服务能不能在凌晨三点自己跑着不出问题。面试官不关心你看了多少小时教程,他们关心你GitHub上那个项目是不是你从零搭起来的。
2026年找Python工作,最有效的方法就是打开编辑器,建个空项目,开始写代码解决一个你自己在意的问题。写得丑没关系。写完了,部署了,能用了,你就比大多数光看教程的人走得远了。
常见问题
Python零基础,多久能找到工作?
按上面的四阶段路线走,全职学习大概4-6个月可以开始投简历。兼职学习翻倍。但"多久"这个问题其实不太准确,关键看你的GitHub上能不能拿出2-3个完整项目。有个朋友没学满三个月,但他做了一个真正能用的招聘数据分析工具,面试直接拿这个项目讲了20分钟,当场过了。时间不是衡量标准,作品才是。
2026年Python还值得学吗?会不会被AI取代?
短期内不会。Python在AI/ML领域反而越来越重要了。AI工具确实能帮你写不少样板代码,但架构设计、性能调优、生产环境排障这些事,还得靠人来做判断。与其担心被取代,不如学会怎么用AI工具提升自己的开发效率。根据2026年的调研数据,会用GitHub Copilot等AI辅助工具的Python开发者,生产力比不用的高出30%左右。
后端、数据、AI三个方向选哪个?
看你的兴趣和背景。如果你喜欢搭系统、做产品,后端方向上手快,岗位数量也最多。如果你有数学或统计背景,数据方向的天花板很高。如果你想追薪资天花板,AI/LLM工程师目前给得最猛($140K-$250K+),但对综合能力要求也最高,得同时懂后端、懂数据、懂模型部署。没有标准答案,先选一个做三个月,不合适再换,比在门口犹豫半年强。