GLM-5来了:花1块钱干15块钱的活,你的AI订阅还续不续?

一个月花多少钱让AI帮你写代码
先问你一个问题:你上个月在AI工具上花了多少钱?智谱AI刚发布的GLM-5,每百万token只要1美元,而Claude Opus 4.6的API价格是它的5倍。这个价格差让我坐下来认真算了一笔账。
如果你跟我一样,Claude Pro每月20美元是固定开支,API调用多的时候再加个三五十,一个月下来七八十美元不在话下。换成人民币,五六百块。这钱够干什么?够请你的程序员同事吃两顿不错的火锅。
但你把这五六百块拿去请AI干活,它确实也干得不错。重构一个异步函数、写个单元测试、分析一段800行的遗留代码——Claude Opus 4.6做这些事就像一个拿着高薪的外包工程师,活儿细,但账单也不含糊。
然后2026年2月11号,智谱AI放出了GLM-5。
这东西一出来,我的第一反应不是"又一个新模型",而是打开计算器算了一笔账。算完之后盯着屏幕愣了一会儿,因为这个数字确实有点离谱。
先看硬指标:GLM-5到底什么来头
GLM-5是智谱AI(Z.ai)的第五代旗舰模型。光说名字你可能没感觉,我换个说法:
想象一个公司有744个员工(744B参数),但每次接活儿只派40个人上(40B激活参数)。这就是MoE(混合专家)架构的做法,用对的人干对的事,不搞全员出动那一套。

几个关键数字:
- 总参数量:744B(256个专家,每次激活40B)
- 训练数据:28.5万亿token
- 上下文窗口:200K token
- 训练硬件:华为昇腾芯片 + MindSpore框架,全程没用一块英伟达的卡
- 开源协议:MIT(真开源,商用、修改、分发随便来)
- 发布日期:2026年2月11日
最后一条重复一遍:MIT协议。你不光能用它的API,还能把模型权重下载到自己机器上跑。哪天智谱改价格了、改条款了,你手里有模型有代码,完全不用看别人脸色。
数据摆上桌:跟Claude Opus 4.6差多少
说个模型好不好,光吹没用,得看数据。我把几个主流编程基准测试的分数拉出来对比了一下:
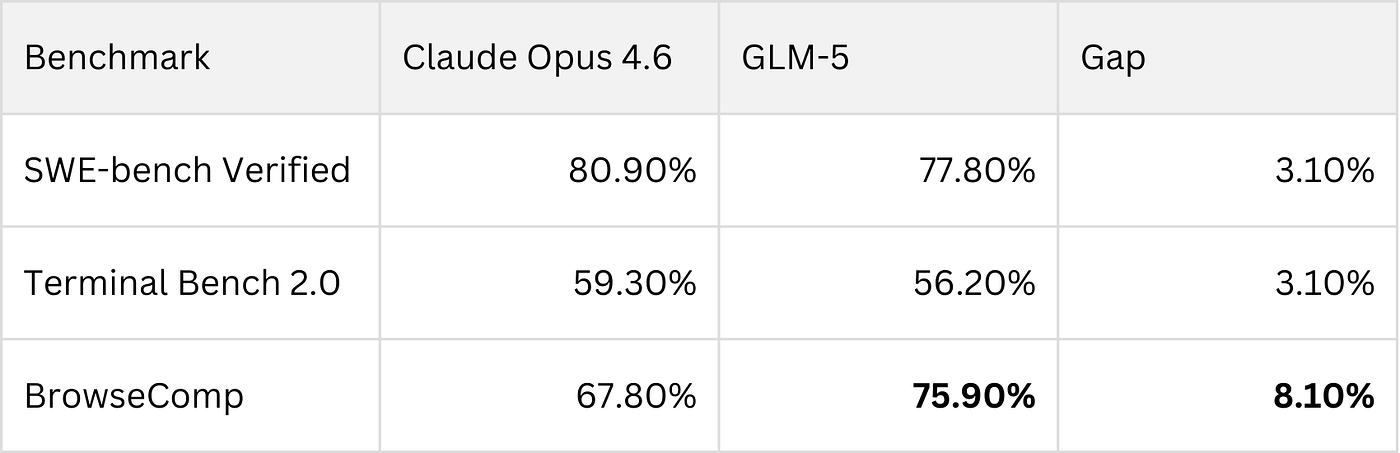
| 基准测试 | Claude Opus 4.6 | GLM-5 | 差距 |
|---|---|---|---|
| SWE-bench Verified | 80.9% | 77.8% | 3.1% |
| Terminal Bench 2.0 | 65.4% | 56.2% | 9.2% |
| BrowseComp | 67.8% | 75.9% | GLM-5赢8.1% |
SWE-bench Verified是目前公认最权威的编程能力测试——你可以把它理解成程序员界的高考。Claude拿了80.9分,GLM-5拿了77.8分。3.1分的差距,说大不大,说小也不算小,放在日常写代码的场景里,大部分时候你感觉不到区别。
Terminal Bench 2.0测的是模型在终端环境里调试和执行命令的能力,这块Claude领先比较明显,差了将近10个点。如果你的工作场景里需要大量跟shell打交道、跨文件debug,Claude的优势是实打实的。
但BrowseComp这个测试就有意思了。这个基准测试考的是模型在多步骤任务中使用工具、浏览网页、检索信息的能力——说白了就是"当智能体"的能力。GLM-5拿了75.9%,反过来赢了Claude 8个多点。
再看一张更全面的对比图:
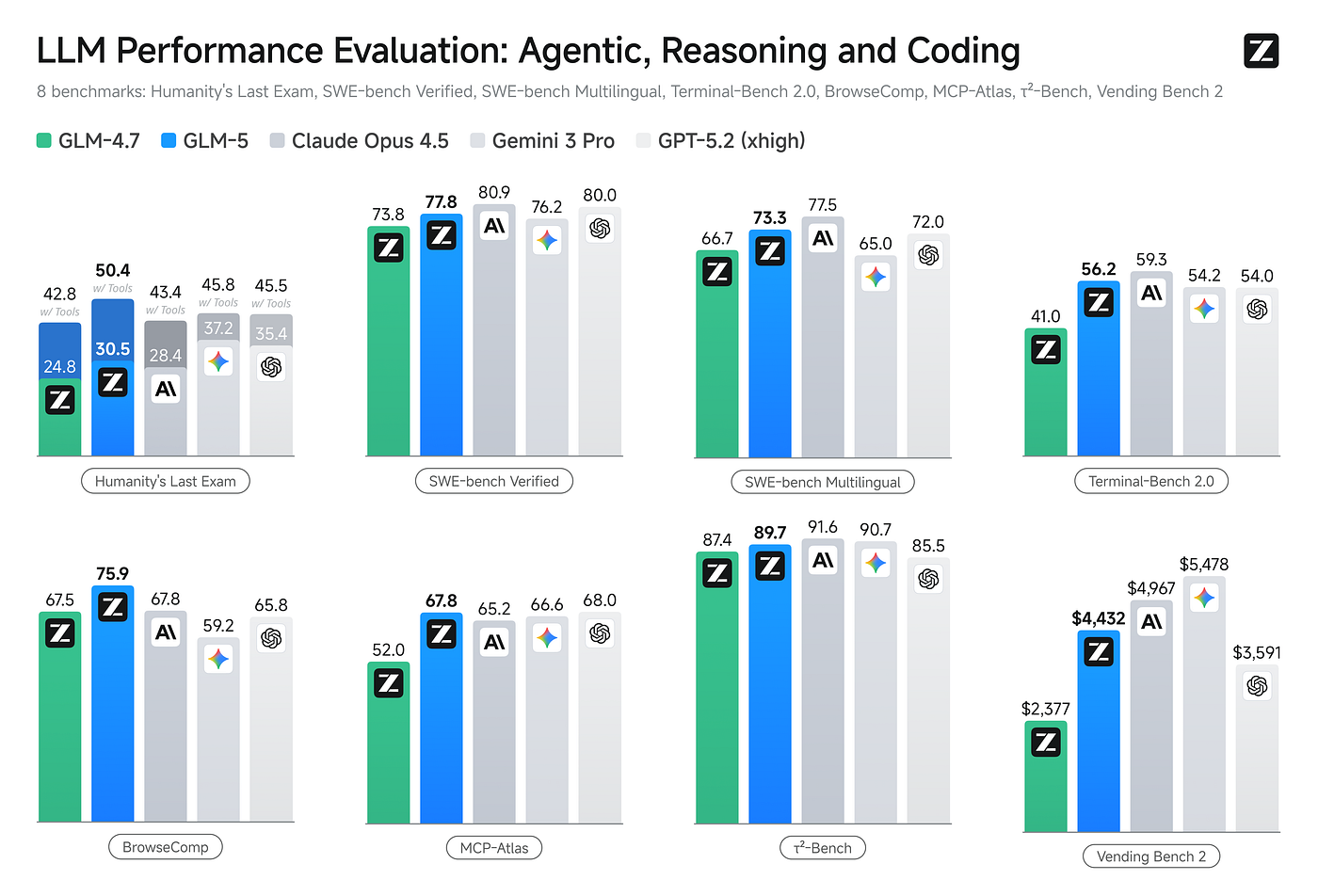
整体来看,GLM-5在编程能力上跟Claude Opus 4.6处于同一梯队,在智能体和工具调用方面甚至更强。一个开源模型做到这个程度,放在两年前根本不敢想。
真正扎心的:GLM-5和Claude Opus价格差了多少倍
技术指标只差一个身位,但价格差出了一条街:

| 模型 | 输入价格(每百万token) | 输出价格(每百万token) |
|---|---|---|
| Claude Opus 4.6 | $5.00 | $25.00 |
| GLM-5 | $1.00 | $3.20 |
我拿上个月自己的用量算了一笔账。我大概用了1000万输入token和150万输出token(主要是代码重构和分析任务)。
用Claude Opus 4.6:输入50美元 + 输出37.5美元 = 87.5美元
用GLM-5:输入10美元 + 输出4.8美元 = 14.8美元
同样的工作量,费用从87.5美元降到14.8美元。省下来的72.7美元,够我请同事吃三顿火锅,还能给自己买杯星巴克。
你可能会说:那3.1%的编程能力差距呢?这个差距换算成钱就是——你愿意多花6倍的钱,买那3%的质量提升吗?
对于大部分开发者的日常工作来说,这笔账不太划算。但如果你在做安全审计、金融系统这类容错率极低的事情,那3%可能是值得买单的。
华为芯片训练出来的模型,能打?
GLM-5有个特别值得聊的背景:它是完全在华为昇腾芯片上训练出来的。
这件事为什么重要?打个比方:如果AI芯片是做菜的灶台,英伟达的GPU就是行业公认的顶配灶台。过去几年,不管你是哪家AI公司,想训练大模型基本都得用英伟达的卡。这就像全世界的厨师都得去一家店买灶台,价格它说了算,产能也它说了算。
然后美国对华为的芯片实施了出口管制。很多人觉得中国的AI训练会因此掉队。
但GLM-5用华为的昇腾芯片和MindSpore框架,从头到尾训练了一个744B参数的前沿模型,而且跑分跟英伟达芯片训练出来的模型在一个水平线上。这就像有个厨师说"我自己搭了个灶台,做出来的菜你尝不出区别"。
这对整个行业来说,意义可能比GLM-5这个模型本身还大。AI训练的芯片选项多了一个,竞争格局就不一样了。
实测:GLM-5写代码到底怎么样
光看跑分不够,我拿了几个自己日常工作中的场景测了一下。
场景一:Python异步代码重构
我有一段大概200行的Python脚本,里面有个典型的异步竞态条件(就是两个异步任务抢同一个资源,偶尔会出bug的那种)。扔给GLM-5,8秒出结果。
它做了什么:
- 指出了竞态条件的位置和原因
- 用
asyncio.Lock重写了关键段 - 给出了三种不同的异步上下文管理器方案,标注了各自的取舍
- 带上了完整的type hints和单元测试
测试用例第一次运行就过了。说实话,跟Claude给出的方案质量差不多,但Claude用的时间也差不多,而费用差了好几倍。
场景二:多步骤工具调用
让GLM-5帮我做一个自动化任务:先查一个npm包的最新版本,再读取项目的package.json,然后生成升级方案。这种需要多步骤工具调用的场景,GLM-5的BrowseComp高分就体现出来了——步骤拆解清晰,工具调用顺序合理,没有走弯路。
要注意的是,GLM-5对提示词的格式比较挑剔。用Claude那种"帮我重构一下这段代码"的随意风格,效果一般。但如果你用结构化的方式告诉它:
<role>资深后端工程师</role>
<task>重构以下函数为async/await模式</task>
<rules>
- 保留现有行为不变
- 所有参数加上type hints
- 包含3个单元测试
</rules>
<output_format>diff格式,带行内注释</output_format>
效果就完全不一样了。GLM-5吃结构化输入的能力很强,它不太擅长猜你的意思,但你把要求说清楚,它执行起来很利索。
GLM-5还是Claude Opus:该选哪个?
聊了这么多,给你一个直接的参考:
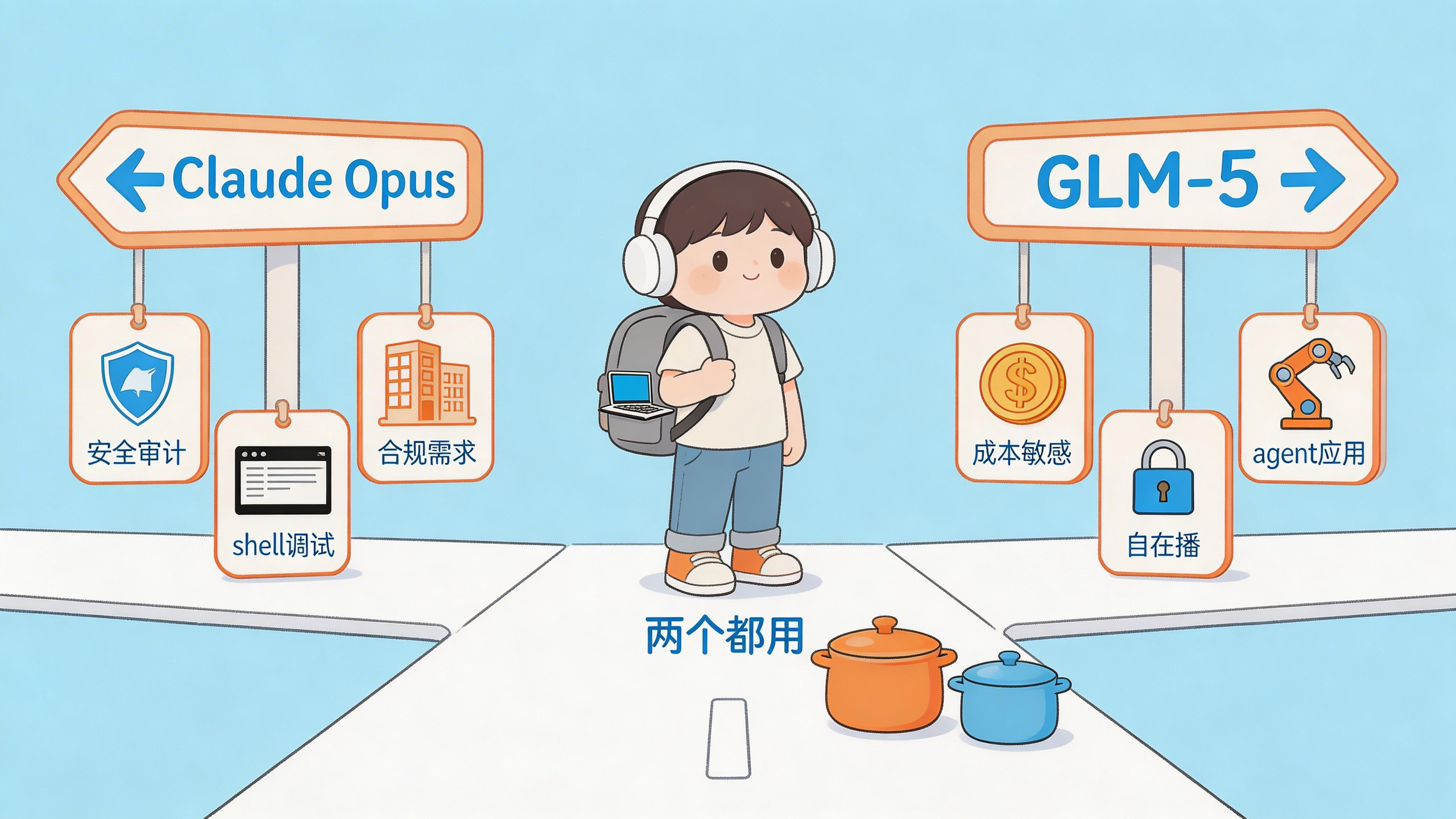
选Claude Opus 4.6的场景:
- 你在做安全审计、金融系统,需要最高的推理准确率
- 你的工作涉及大量终端调试和跨文件分析
- 你们团队已经围绕Claude建了工作流,迁移成本高
- 你需要Anthropic的安全合规文档(企业场景)
选GLM-5的场景:
- 你是独立开发者或小团队,对成本敏感
- 你的任务以代码生成、重构、分析为主
- 你需要自托管模型,不想被API厂商锁定
- 你做的是多步骤agent类应用,工具调用是核心需求
两个都用的场景(我现在的方案):
- 重要的、一次性的架构决策扔给Claude Opus 4.6
- 日常批量的代码生成和重构交给GLM-5
- 涉及安全合规的代码审查,还是让Claude来
- 跟家里做饭一个道理,不同的菜用不同的锅,没必要一口锅炒所有
所以Claude那20美元的订阅省不省
回到开头的问题。GLM-5出来之后,你的AI订阅该怎么办?
我的答案是:看你的用量和场景。
如果你每个月AI消费在20美元以内(就一个Claude Pro订阅),说实话差别不大,Claude的体验更丝滑,生态更成熟。
但如果你像我一样,Pro加API一个月花六七十美元甚至更多,那GLM-5值得认真评估。把批量任务切到GLM-5上,每个月能省下五六十美元。一年下来就是六七百美元,够买一个不错的机械键盘了。
不过别急着全切。我的建议是这样操作:
- 先在 Z.ai的API 上注册,拿到API key
- 把你日常最常见的3个任务分别在两个模型上跑一遍
- 记录质量和耗时,自己做个对比
- 根据结果决定哪些任务可以迁移
别看了某篇测评就急着冲,你自己的场景、你自己的数据,跑一遍才知道。
GLM-5跑了77.8%的SWE-bench分数,MIT开源,每百万token一美元。开源模型走到今天这一步,已经不是"差不多能用"的水平了,它在很多场景下就是能替你省钱办事。
至于我自己?Claude的订阅还留着,但上个月的API账单确实比之前薄了不少。省下来的钱干了什么?买了把新键盘,打字的时候心情好了不少。
常见问题
GLM-5能完全替代Claude Opus 4.6吗?
看场景。日常代码生成、重构、分析这些任务,GLM-5完全够用,SWE-bench只差3.1个百分点。但如果你需要复杂的终端调试(Terminal Bench差9.2个点)或者企业级安全合规文档,Claude的优势还在。我的做法是两个搭配用,把成本压下来的同时不牺牲关键任务的质量。
GLM-5是免费的吗?怎么开始用?
模型本身MIT开源,你可以从Hugging Face下载权重自己部署。但大部分人会选择用API,价格是每百万输入token 1美元、输出token 3.2美元。去Z.ai注册账号就能拿到API key,接口格式跟OpenAI兼容,迁移成本很低。
华为芯片训练的模型,性能靠谱吗?
从跑分来看,完全靠谱。GLM-5在SWE-bench Verified上拿到77.8%,BrowseComp拿到75.9%(这项还赢了Claude),这些成绩跟英伟达芯片训练出来的顶级模型在一个量级。训练芯片的品牌不影响最终模型的推理质量,关键看训练框架和数据的功夫下得够不够深。
参考来源: