Go内存分配器:一个仓库经理的自我修养
你写了一行 make([]byte, 100),然后这100字节就凭空出现了。但你有没有想过,这100字节从哪来?谁给你的?为什么这么快?
Go的内存分配器就像一个仓库经理。你的程序每天都在要各种大小的箱子,有时候要一个装硬币的小盒子,有时候要一个装冰箱的大箱子,而且要得特别急。仓库经理的工作就是在毫秒级的时间里把箱子递给你,同时保证仓库不乱,还得配合清洁工把没人用的箱子收回来。
今天就来扒一扒这个仓库经理是怎么干活的。
什么时候需要找内存分配器
不是你程序里的每个变量都要经过仓库经理。Go有两个放东西的地方:栈和堆。
栈就像你办公桌上的便签纸。每次调用函数,就在桌上放一张新便签,函数里临时用的变量就写在便签上。函数执行完,这张便签直接撕掉扔了,根本不需要仓库经理插手。快得很。
但有些东西不能写在便签上。比如你函数里创建了一个对象,然后把这个对象的指针返回出去了。这时候这个对象不能随着便签一起被撕掉,它得活着,因为外面还有人要用。这种数据就得放到堆上,堆就像是仓库里的正式货架,能长期存放东西。
Go编译器会自动帮你判断哪些东西该放栈上、哪些该放堆上,这个分析过程叫逃逸分析。只有最终落到堆上的东西,才会惊动内存分配器。
为什么不直接找操作系统要内存
你可能会说,内存不是操作系统管的吗?直接找OS要不就完了?
问题在于找操作系统要内存太慢了。每次要内存都得发起系统调用,从用户态切到内核态,操作系统做完记录再切回来。这一套下来,够你程序干好多活了。
更要命的是,Go程序动辄几千个goroutine同时跑。如果每个goroutine要内存都得排队找OS,那这个队伍能排到停车场去。
所以Go runtime的做法是:一次性找操作系统要一大块内存,然后自己内部分发。你程序要100字节?从已经拿到的大块内存里切100字节给你,不用惊动OS。只有手里的内存用完了,才去找OS再要一块。
这就是内存分配器的核心价值:做你程序和操作系统之间的中间商,让分配变快。
仓库的结构:Arena和Page
Go找操作系统要的大块内存叫Arena。在64位系统上,每个Arena是64MB。
但你先别慌,Go不是一上来就占你64MB物理内存。它只是先占64MB的地址空间,相当于先在地图上圈一块地,写着"这块地归我了"。至于真正的物理内存,是等你真正往里写东西的时候,操作系统才按需分配的。这就是虚拟内存的好处。
64MB还是太大了,没法直接分给调用方。所以Go把每个Arena切成8KB的小块,这些小块叫Page。注意这是Go自己的Page,不是操作系统的4KB页,是Go自己定义的管理单位。
一个64MB的Arena里有8192个Page(64MB / 8KB)。Go会记录每个Page的状态:哪些在用,哪些空闲。
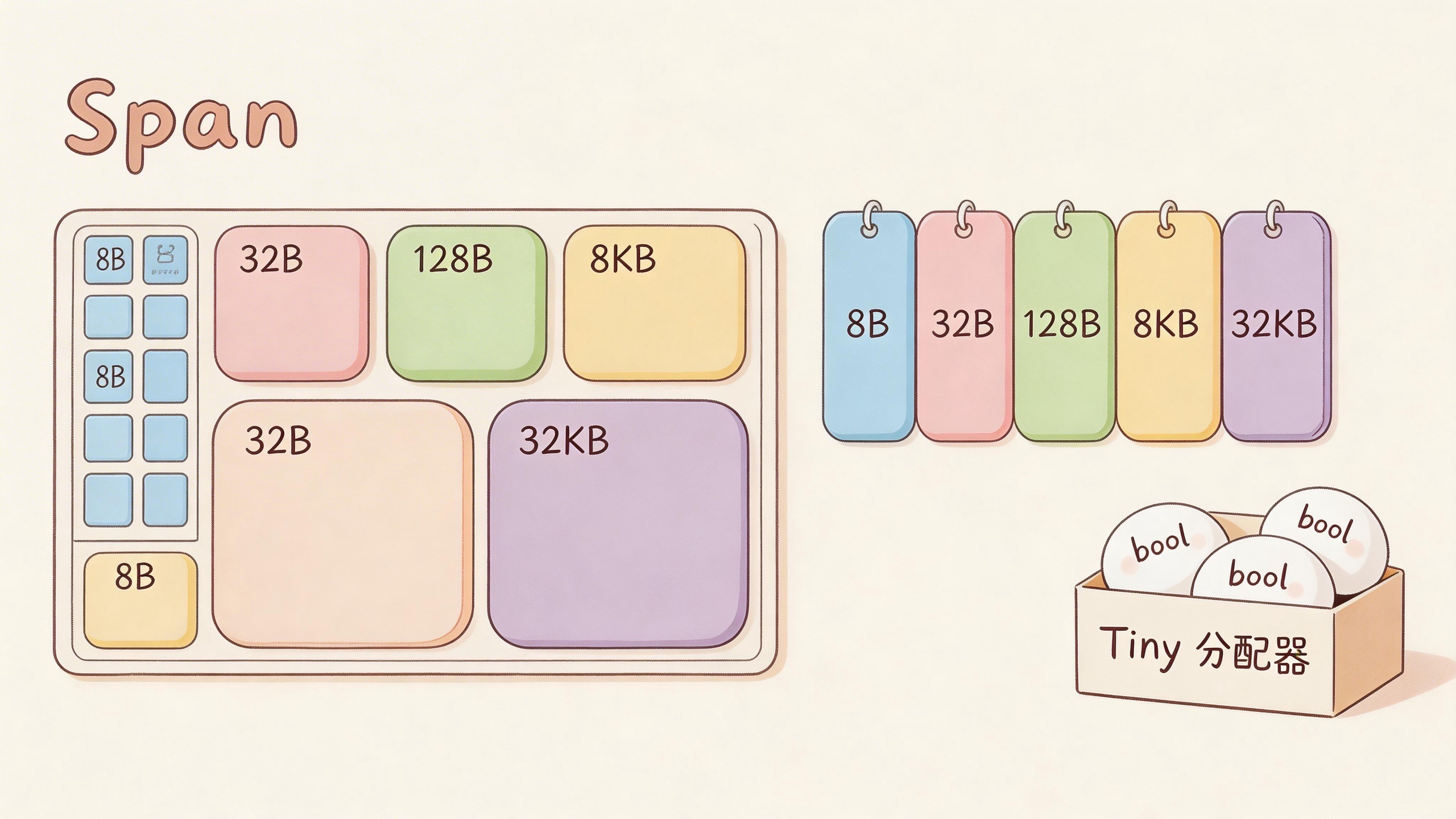
但8KB对于大多数分配来说还是太大了。你就要32字节,给你8KB不是浪费吗?这时候就需要Span出场了。
Span:货架上的格子
Span是一个或多个连续的Page,专门用来存放固定大小的对象。
举个例子。假设你的程序需要很多32字节的对象。分配器会拿一个8KB的Page,把它变成一个专门放32字节对象的Span,然后把这个Page切成256个格子(8192 / 32 = 256)。每个格子正好32字节。
当你来要32字节的时候,分配器就在这个Span里找一个空格子给你。下一个要32字节的,给下一个空格子。简单高效。
为什么快?同一个Span里所有格子大小一样。不用找能放得下的块,也不用担心碎片,更不用合并相邻空闲块。找下一个空格子就完事。
每个Span用位图记录哪些格子被占用了。一位代表一个格子,1是占用,0是空闲。找空格子就是扫描位图找0。
Size Class:68种规格
既然每个Span只放一种大小的对象,那岂不是要有很多种Span?
确实,但Go不可能为每个可能的字节数都准备一种Span。那样太乱了。Go的做法是定义68种规格,叫Size Class,从8字节到32KB。
你分配20字节,Go会向上取整到24字节,用24字节的Size Class。浪费4字节,但换来了简单和速度。
看看几个典型的Size Class:
| Size Class | 对象大小 | 每个Span的Page数 | 每个Span的对象数 |
|---|---|---|---|
| 1 | 8B | 1 | 1024 |
| 4 | 32B | 1 | 256 |
| 10 | 128B | 1 | 64 |
| 32 | 1024B | 1 | 8 |
| 51 | 8192B | 1 | 1 |
| 67 | 32768B | 4 | 1 |
你会发现有的Size Class一个Span只能放一个对象,比如8KB的Size Class。这不是设计失误,而是权衡。大对象本来就很少,没必要为了多放几个对象而把Span搞很大,占着内存不用。
大对象和小对象的特殊处理
Size Class从8字节到32KB,但两头还有特殊情况。
比32KB还大的对象,走Size Class 0。它没有固定大小,需要多少Page就给多少Page,一个对象独占一个Span。这种大对象会跳过缓存层,直接找全局分配器要。
比8字节还小的对象呢?比如一个bool或者int8,只有1字节。给它8字节的格子太浪费了。
Go有个Tiny分配器,专门处理小于16字节且不含指针的对象。它会把多个小对象打包到一个16字节的格子里。一个bool占1字节,下一个bool紧接着放,不浪费空间。
Scan和NoScan:还要看有没有指针
Size Class只是大小。Go还关心一件事:对象里有没有指针。
为什么在意这个?因为垃圾回收器需要扫描有指针的对象来追踪引用。没有指针的对象(比如一个[100]byte数组)可以跳过扫描,省时间。
所以Go把每个Size Class又分成两种:scan(需要扫描)和noscan(不需要扫描)。68种Size Class乘以2,一共136种Span Class。
分开存放,垃圾回收的时候效率更高。
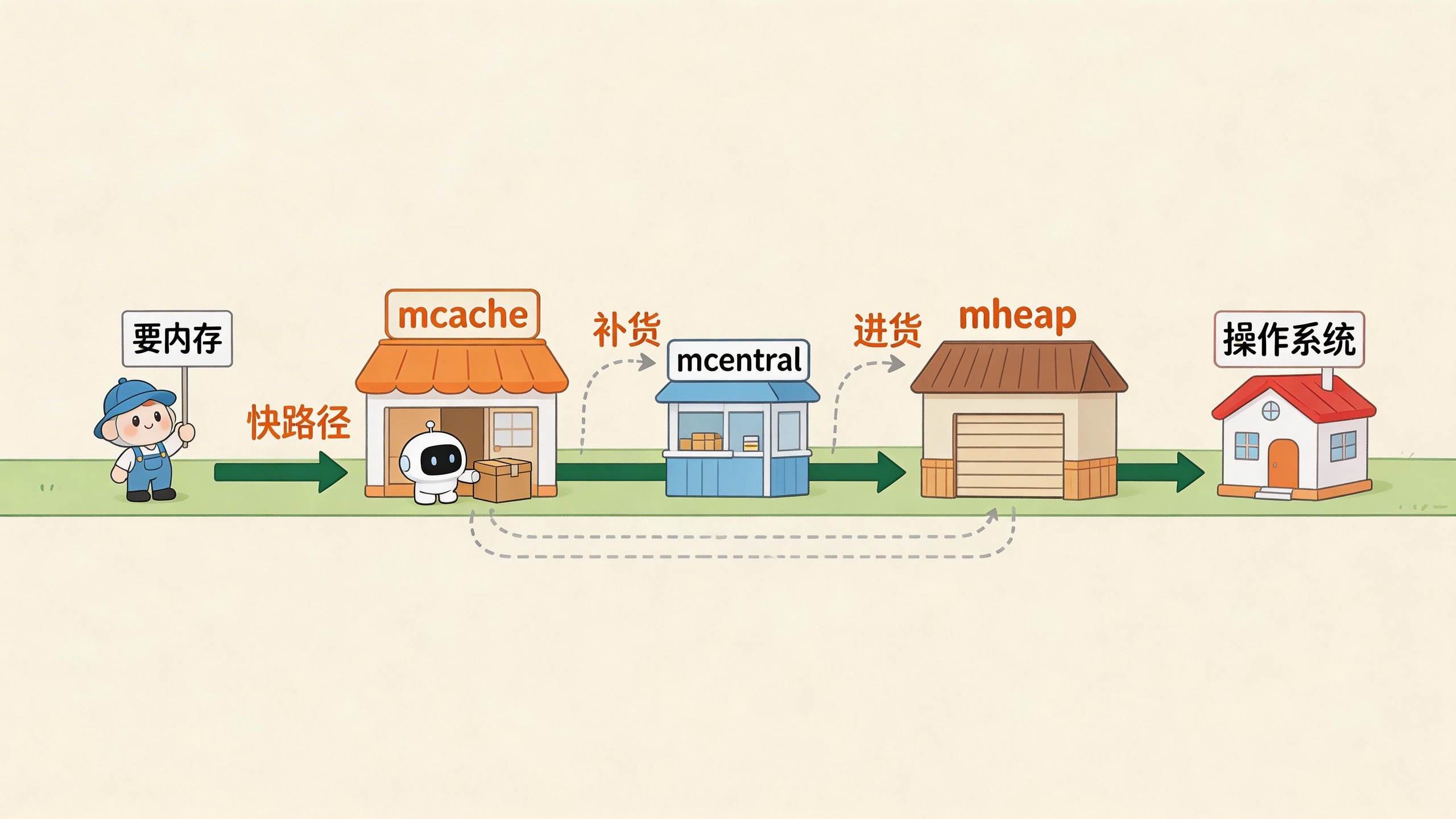
mcache、mcentral、mheap:三级缓存解决锁竞争
现在结构有了,但还有一个大问题:并发。
Go程序有几千个goroutine同时在跑,都要分配内存。如果只有一个全局的Span列表,每次分配都得抢一把锁,那排队都能排死。
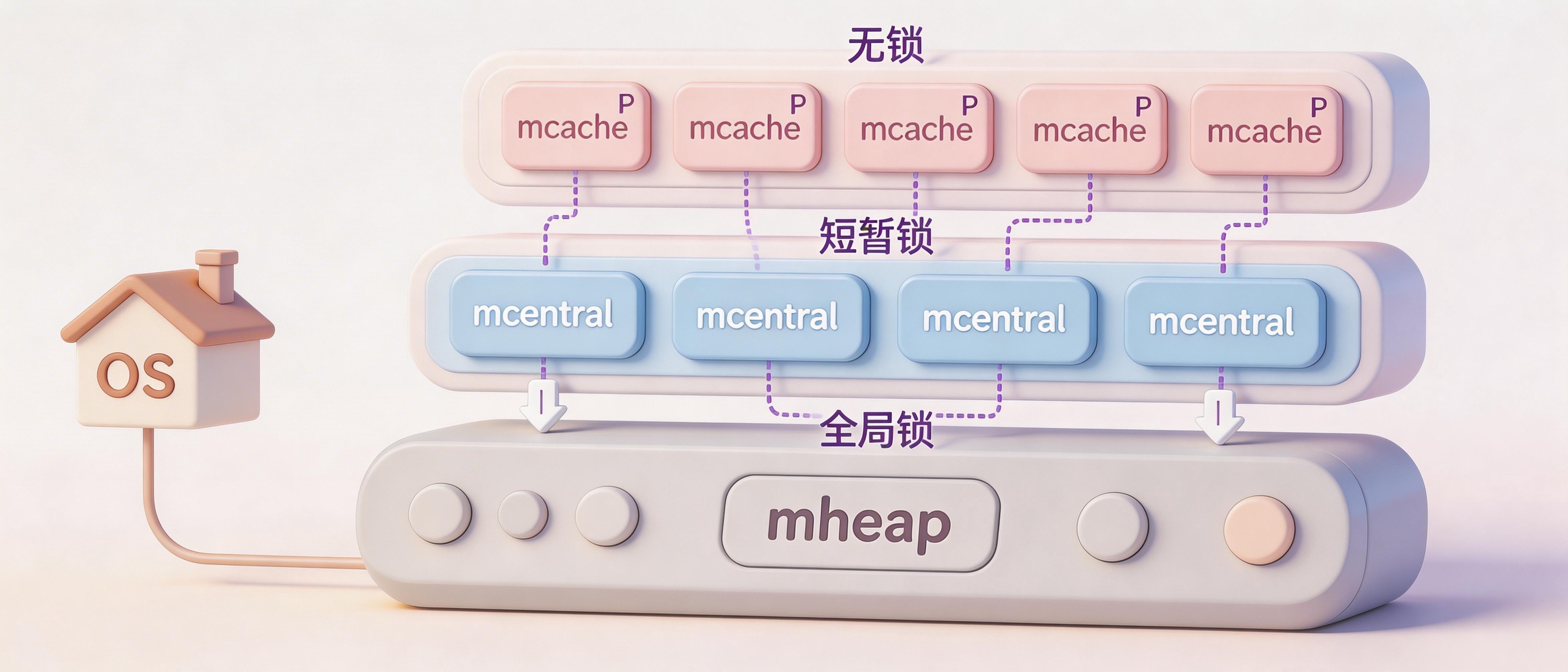
Go的解决方案是三级层次结构,灵感来自Google的tcmalloc设计。
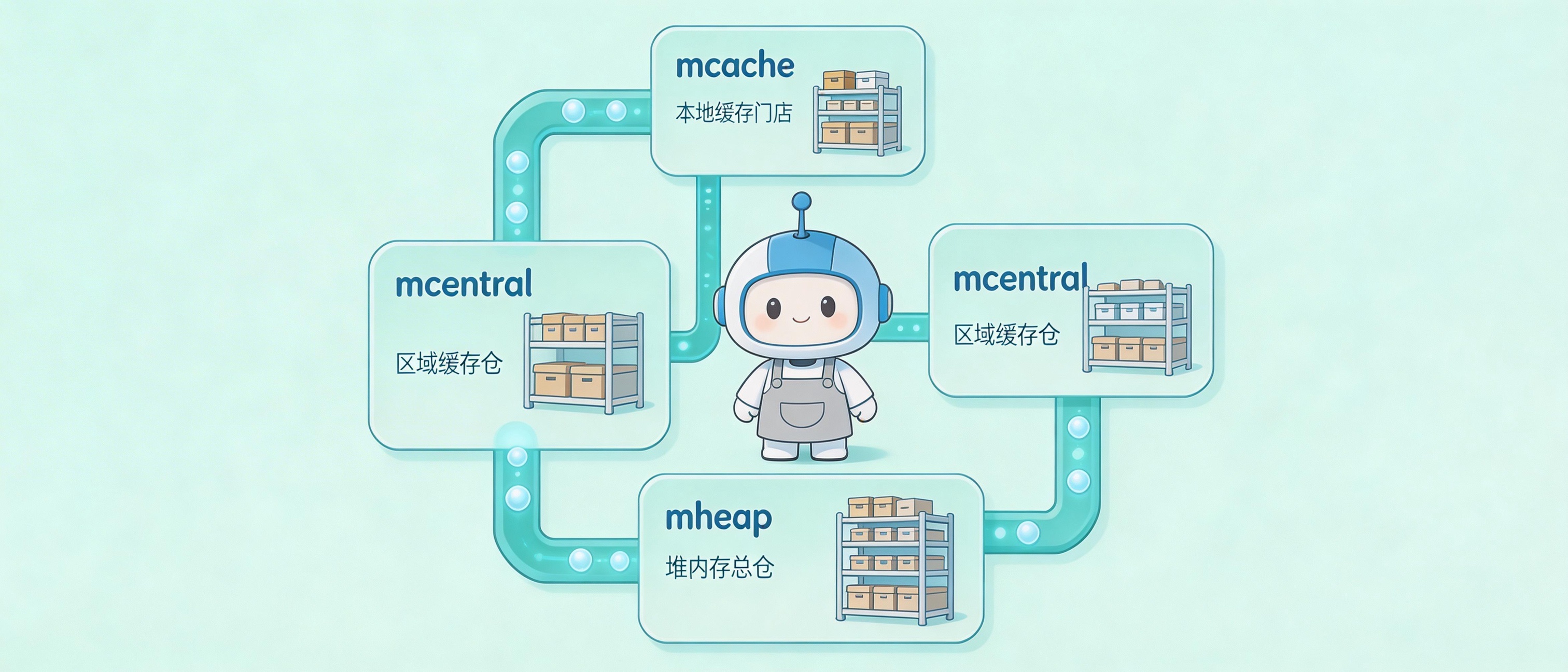
第一级:mcache,每个P一个,无锁
Go调度器有个概念叫P(Processor),通常每个CPU核心一个P。每个P都有自己的mcache,里面存着各种Span Class的Span。
当goroutine需要分配内存时,它运行在某个P上,直接从P的mcache里拿。因为同一个P同时只跑一个goroutine,所以完全不需要锁。这是最常用的路径,绝大多数分配都在这里完成。
第二级:mcentral,每个Span Class一个,短暂加锁
当mcache里某个Span Class的Span用光了,它得去mcentral拿新的。mcentral是每个Span Class一个,专门管理该类型的Span池。
mcache把用光的Span还给mcentral,换一个有空闲槽位的Span。这个过程需要加锁,但很快,就是换一下Span。而且不同Span Class的mcentral是分开的,分配不同大小对象的goroutine不会互相竞争。
第三级:mheap,全局唯一,代价最高
当mcentral也没Span了,它得找mheap要。mheap是全局的页分配器,访问它需要全局锁。这是最慢的路径,涉及寻找空闲页、可能向OS申请新Arena、初始化新Span。
但这条路很少走,因为上面两级已经吸收了绝大部分需求。
整个设计就像一个缓存链:mcache缓存mcentral,mcentral缓存mheap。最常用的路径无锁,偶尔需要的路径短锁,很少走的路径才用全局锁。
分配流程全解密
所有分配都走一个入口:mallocgc()函数。根据大小不同,走不同的路。
零大小对象
struct{}{}这种零大小对象,Go直接返回一个全局变量zerobase的地址。根本不分配内存,反正你也读不到任何东西。
Tiny对象(<16B,无指针)
走Tiny分配器。检查当前16字节块还能不能塞下,能就塞进去,不能就找mcache要一个新的16字节格子。
有个细节:如果当前块塞不下了,分配器会拿一个新格子,然后比较旧块和新块哪个剩余空间大。大的那个成为新的当前块,方便下次继续塞。主打一个不浪费。
小对象(16B到32KB)
这是最常见的情况,也是整个架构优化的重点。
- 向上取整到最近的Size Class,确定Span Class
- 找mcache里对应的Span,用位图找下一个空闲槽位
- 有空闲槽位?直接返回,无锁完成
- Span满了?找mcentral换一个
- mcentral也没有?找mheap分配新页
- mheap也没页了?找操作系统要新Arena
大多数分配在第2步就结束了,快得飞起。
大对象(>32KB)
直接跳过mcache和mcentral,找mheap分配恰好够用的页数。
和垃圾回收的配合
内存分配器不是单打独斗的,它和垃圾回收器(GC)紧密配合。
每个Span有两个位图:allocBits记录哪些槽位被分配了,gcmarkBits记录GC标记阶段哪些对象还活着。
GC运行的时候,会扫描所有可达对象,在gcmarkBits里标记。标记完成后,Go把两个位图互换。新的allocBits只包含活着的对象,没被标记的就是垃圾,槽位可以重用了。
这就是为什么mcentral有时候需要先sweep(清理)Span才能交给mcache。Sweep就是根据位图判断哪些槽位是空的。Go把清理工作推迟到需要的时候才做,把开销分摊到多次分配中。
如果一个Span清理后发现完全空了(所有对象都是垃圾),它的页会被还给mheap,可以重新分配给其他Span Class。
内存还能还回去吗
GC释放的对象只是把槽位标记为可重用,页还留在runtime手里。从操作系统角度看,你的程序还在用那么多内存。
但如果你的程序刚经历了一个内存使用高峰,现在大部分内存都是垃圾,难道就白白占着?
Go有个后台goroutine叫scavenger(清道夫),它会定期检查哪些页已经空闲很久了,然后告诉操作系统"这些内存我暂时不用了,你收回去吧"。
在Linux上用MADV_DONTNEED告诉内核。页还映射在程序的地址空间里(以后还能用,不用发系统调用),但内核可以把背后的物理内存收回给别人用。
这是个平衡:还太频繁会伤性能(以后要用还得重新申请),占太多不用浪费资源。Scavenger会找到合适的平衡点。
总结一下
Go内存分配器的设计哲学:
- 批量向OS要内存,内部分发,避免系统调用开销
- Arena切Page,Page组Span,Span分槽位,层次分明
- 68种Size Class加scan/noscan区分,精准匹配需求
- 三级缓存mcache-mcentral-mheap,无锁处理绝大多数分配
- Tiny分配器给小对象极致优化
- 和GC配合,用双位图实现高效回收
- Scavenger后台回收,不浪费系统资源
如果你有兴趣看源码,src/runtime/malloc.go、mheap.go、mcache.go、mcentral.go这些文件写得挺清楚,值得一读。
下次写make([]byte, 100)的时候,想想那个仓库经理正在疯狂工作,就为了让你这100字节快点到位。
常见问题FAQ
Q: Go内存分配器和Java的有啥区别?
A: Go用的是tcmalloc风格的多级缓存,每个P有自己的mcache无锁分配。Java的TLAB(Thread Local Allocation Buffer)类似,但Go的设计更激进地减少锁竞争,特别适合高并发goroutine场景。
Q: 逃逸分析怎么看?
A: 编译时加-gcflags='-m',比如go build -gcflags='-m' main.go,编译器会告诉你哪些变量逃逸到堆上了。
Q: mcache的内存什么时候释放?
A: mcache里的Span如果完全空了,会被mcentral收回。mcentral的空Span会被mheap收回。mheap的空闲页可能被scavenger还给OS。是个逐层回收的过程。
Q: 大对象分配为什么跳过缓存?
A: 大对象本身就不常见,而且占用的页多,缓存在mcache里太占地方。直接找mheap分配更合理,反正大对象分配本身就是慢路径。