四叉树:从暴力搜索到空间索引的逆袭之路
假设你在做一个地图应用。数据库里躺着几百万家餐厅、加油站、景点,每个都有经纬度。用户在屏幕上点了一下,问:“我附近有什么?”
这种场景,正是四叉树(Quadtree)这个空间索引数据结构的用武之地。但在讲它之前,我们先看看最直接的做法:把每个点都算一遍距离,保留够近的,扔掉远的。
这法子能用,就是慢。
一千个点还好,一百万个点呢?每次查询都要算一百万次距离。用户手指一滑,地图跟着动,每秒触发好几次查询。手机 CPU 直接原地爆炸。
找钥匙的智慧
你想想,要是你在一个大房子里找丢了的钥匙,你会怎么找?
肯定不是从门口开始,一寸一寸地毯式搜索。你会先把房子分成几个区域:客厅、卧室、厨房、卫生间。然后想一下:“我刚才去过哪?” 厨房没去,直接跳过。卫生间没进,不用看。精力集中在你确实待过的那几个区域。
四叉树干的就是这件事,只不过它针对的是二维空间。
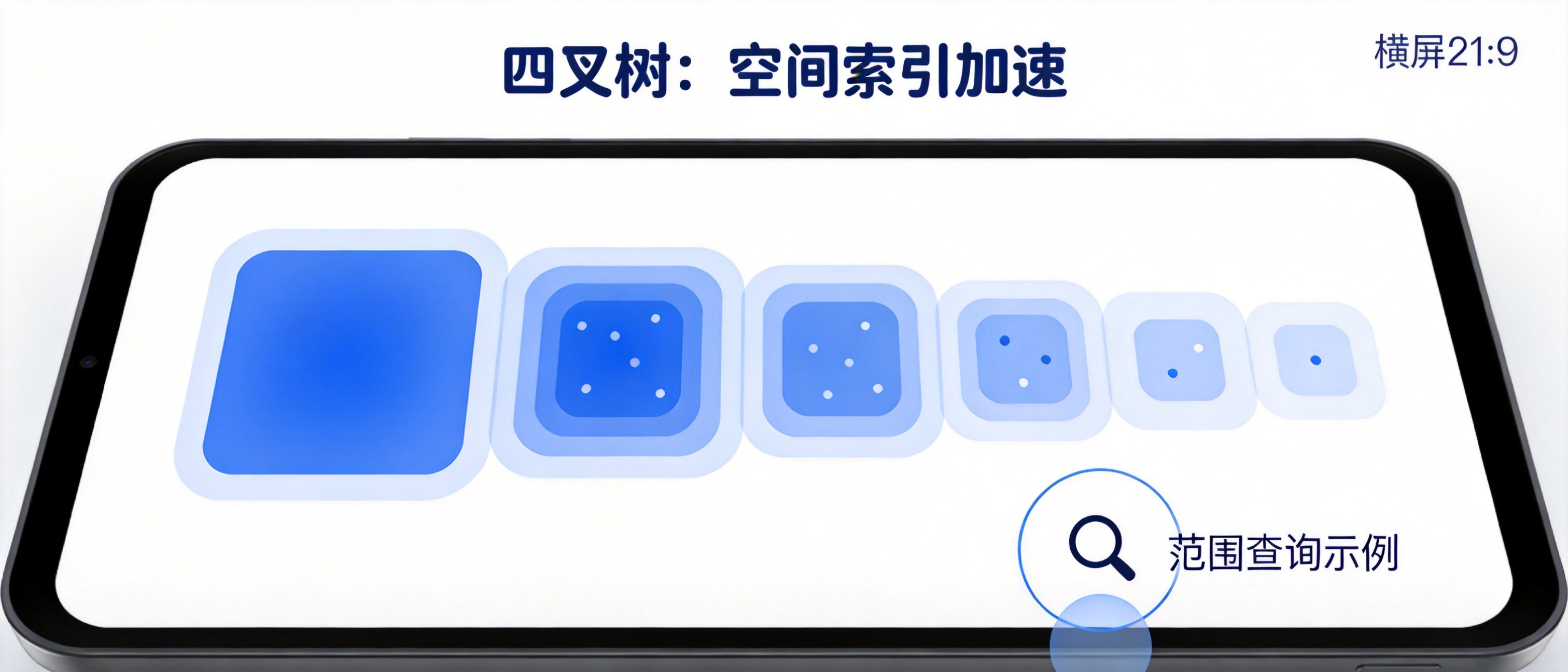
它的工作方式是这样的:拿一块矩形区域,切成四等份——左上、右上、左下、右下。如果某个象限里的点太多了,就继续切,再切成四份。切到什么时候停?等每个格子里点的数量都够少了,就不再细分了。
这样一来,点密集的地方格子小,点稀疏的地方格子大。树的结构会跟着数据的分布自动调整。
暴力搜索 vs 四叉树
咱们来直观感受一下差距。
暴力搜索是怎么干的:不管你问的是哪个区域,它都把所有点遍历一遍。地图右上角的点,跟你问的左下角区域八竿子打不着?照样要检查。做了大量无用功。
四叉树的思路是:先判断这个格子的范围跟你要查的区域有没有交集。没有?那这个格子连同它底下所有的点,直接跳过。有交集?再往下细分,一层层筛选。
结果就是:本来要检查一百万个点,现在可能只检查几千个。查询时间从秒级降到了毫秒级。
怎么建一棵四叉树
建树的过程其实挺直观:
- 开始时,整张地图就是一个大方块
- 来一个点,往里放
- 方块里的点超过容量上限了?切成四份,把里面的点重新分配到各自的象限
- 重复步骤 2-3
容量上限怎么设?常见的做法是 4 到 16 之间。设小了,树深,格子多,查询快但占内存。设大了,树浅,省内存但每个格子里要线性扫描的点也多。根据你的数据分布和查询模式来调。
有个细节值得提一下:四叉树的切分线是固定的,永远在正中间。这跟 KD 树不一样,KD 树会根据点的实际位置来决定在哪切。四叉树的好处是切分位置可预测,坏处是如果点分布不均匀,可能会出现有些格子很挤、有些格子很空的情况。
范围查询:怎么找出区域内的所有点
这是四叉树最常用的操作。给你一个矩形,找出里面所有的点。
算法逻辑是递归的:
def range_query(node, rect):
if node.region 跟 rect 没交集:
return [] # 整个分支直接剪掉
if node 是叶子节点:
return [p for p in node.points if p 在 rect 里]
result = []
for child in node.children:
result += range_query(child, rect)
return result
关键点在于第一行的判断:如果当前格子的范围跟查询矩形压根不沾边,那这个格子底下所有的点都不用看了。这一步剪枝能省掉巨量的计算。
最近邻查询:怎么找最近的点
有时候你不知道搜索范围该设多大。你想问的是:“离我最近的那个点在哪?”
算法的思路是这样的:
- 维护一个"当前最近距离",一开始设成无穷大
- 遍历树的节点,每找到一个点就更新最近距离
- 在进入某个子节点之前,先判断:这个子节点的范围里,有没有可能存在比当前最近的点更近的点?如果不可能,整棵子树都跳过
这里有个优化技巧:按距离排序访问子节点。先查离查询点最近的那个象限,这样能更快找到一个"还不错"的候选点,然后就能更激进地剪掉其他分支。
理想情况下,最近邻查询的时间复杂度接近 O(log n)。一百万个点,大概十几次比较就能找到最近的那个。
碰撞检测:游戏引擎的好帮手
游戏里经常要判断哪些物体撞在一起了。假设有 n 个物体,暴力做法是每对都检查一遍,复杂度是 O(n²)。100 个物体要检查将近 5000 次,1000 个物体要检查将近 50 万次。
用四叉树可以大幅优化:每一帧重建一次树,然后对每个物体只查询它附近的区域。远处的物体压根不会进候选列表。
实际游戏引擎里,四叉树(或者它的 3D 版本八叉树)用于"粗筛"阶段:快速找出可能碰撞的物体对,然后再用精确的几何计算做"细筛"。
图像压缩:四叉树的另一个面孔
四叉树不光能处理点数据,还能处理连续的区域,比如图像。
思路是这样的:看一块图像区域,如果这块区域里的像素颜色都差不多(差异小于某个阈值),就用一个平均值代表整块。如果差异太大,就切成四份,递归处理。
结果是:颜色单一的区域(比如蓝天、白墙)用大块存储,颜色复杂的区域(比如边缘、纹理)切成小块保留细节。
这跟 JPEG 的思路有点像:在信息量低的地方省空间,在信息量高的地方保质量。当然,真正的 JPEG 用的是离散余弦变换和熵编码,比四叉树复杂得多,但核心思想是一致的——别均匀用力,把资源花在刀刃上。
四叉树的亲戚们
四叉树是空间分割数据结构家族的一员。这个家族还有几个成员:
**八叉树(Octree)**是四叉树的 3D 版本,每次切成八份,游戏引擎、体积渲染里经常用它。KD 树的切法不一样,每次只切一个维度——先沿 x 轴切,再沿 y 轴切,交替进行,切分点的位置可以根据数据分布灵活调整。
还有个 R 树,把附近的对象打包成一个包围盒,层层嵌套。PostGIS 里的 GiST 索引就是它的变种,特别适合存储多边形、线段这类非点数据。
各有各的适用场景。四叉树胜在简单直观,切分位置固定让实现和调试都容易。KD 树在分布不均匀的数据上可能更平衡。R 树在处理非点数据(比如区域、线段)时更灵活。
什么时候该用四叉树
总结一下四叉树适合的场景:
- 空间查询多,经常问"这个区域里有什么"或"离这个点最近的是什么"
- 数据分布相对均匀,不会所有点都挤在一条线上
- 数据相对静态,或者更新不频繁,可以接受重建树的代价
- 查询局部性强,每次只查一小块区域
地图应用、游戏物理、空间数据库,这些场景都符合。
如果你的数据更新特别频繁,或者查询经常覆盖大范围,可能要考虑其他方案。没有银弹,合适的工具干合适的事。
常见问题
Q:四叉树和哈希表有什么区别?什么时候用哪个?
A:哈希表适合精确查找(给我 key 为 X 的记录),四叉树适合范围查找(给我坐标 (x, y) 附近 1 公里内的记录)。如果你要查的是"等于",用哈希表;要查的是"在附近",用四叉树。
Q:四叉树的查询时间复杂度到底是多少?
A:理想情况(数据分布均匀)下,点查询和范围查询都是 O(log n)。但最坏情况(所有点都在一条线上)可能退化为 O(n)。实际应用中,空间数据通常有一定的聚集性,四叉树的表现会比暴力搜索好得多。
Q:动态更新数据怎么办?每次都重建树太慢了。
A:有几种方案。一种是惰性更新:标记删除,批量重建。一种是增量更新:只重建受影响的分支。还有一种是用更适合动态数据的结构,比如 R 树,它的分裂和合并操作更局部化。