RAG 检索增强生成实战:别让你的大模型闭卷考试了,给它开本书

上周我问 Claude:“我们项目的部署文档放哪了?” 它跟我扯了一通 Kubernetes 最佳实践,写得头头是道,就是跟我们项目没半毛钱关系。
还有一次让它查某个 API 的最新用法,它给了一段去年就废弃的代码,还说"亲测可用"。
AI 不是笨,是它在闭卷考试。RAG(检索增强生成)就是解决这个问题的:给大模型配一本参考书,让它查完再答。
大模型为什么会"编"答案
大模型训练的时候确实读了很多书,但它有两个硬伤。
记忆有截止日期。Claude 的训练数据到 2025 年初,你问它 2026 年的事,它只能靠猜。就像你让一个 2020 年毕业的学生回答 2026 年的时事题,他总不能说"我翻翻课本"吧。
另一个问题是它不认识你家的数据。你公司的内部文档、产品手册、客户记录,大模型压根没见过。据 Gartner 2025 年的报告,企业 80% 以上的数据属于非公开的内部数据。你让大模型回答相关问题,相当于让刚入职的实习生回答"公司上个季度的退款率是多少",他不编才怪。
那怎么办?给它一本参考书,让它开卷考试。
这就是 RAG – 检索增强生成(Retrieval-Augmented Generation)。
RAG 检索增强生成是什么
RAG 的思路朴素到有点不好意思讲。你上学考试那会儿:
闭卷考试:老师问什么,全靠脑子里记住的东西。记不住就瞎编,编得像模像样但经不起推敲。
开卷考试:先翻书找到相关的章节,读一遍,再根据找到的内容回答。靠谱得多。
RAG 就是把 AI 从闭卷模式切换到开卷模式。流程也不复杂:
- 你提问:“PostgreSQL 18 的异步 IO 性能提升了多少?”
- 系统帮你翻书:从你的知识库里找到最相关的几段内容
- AI 带着资料答题:Claude 读完这些内容,再给你一个有理有据的回答
整个过程就像你去图书馆查资料。你不会把整个图书馆的书都搬回家,而是先查目录,找到相关的那几本,翻到对应的章节,然后写你的报告。
Embedding 向量搜索:怎么"翻书"的
这里要讲一个东西:Embedding,中文叫嵌入向量。也是 RAG 系统的核心组件。
名字唬人,原理直觉。
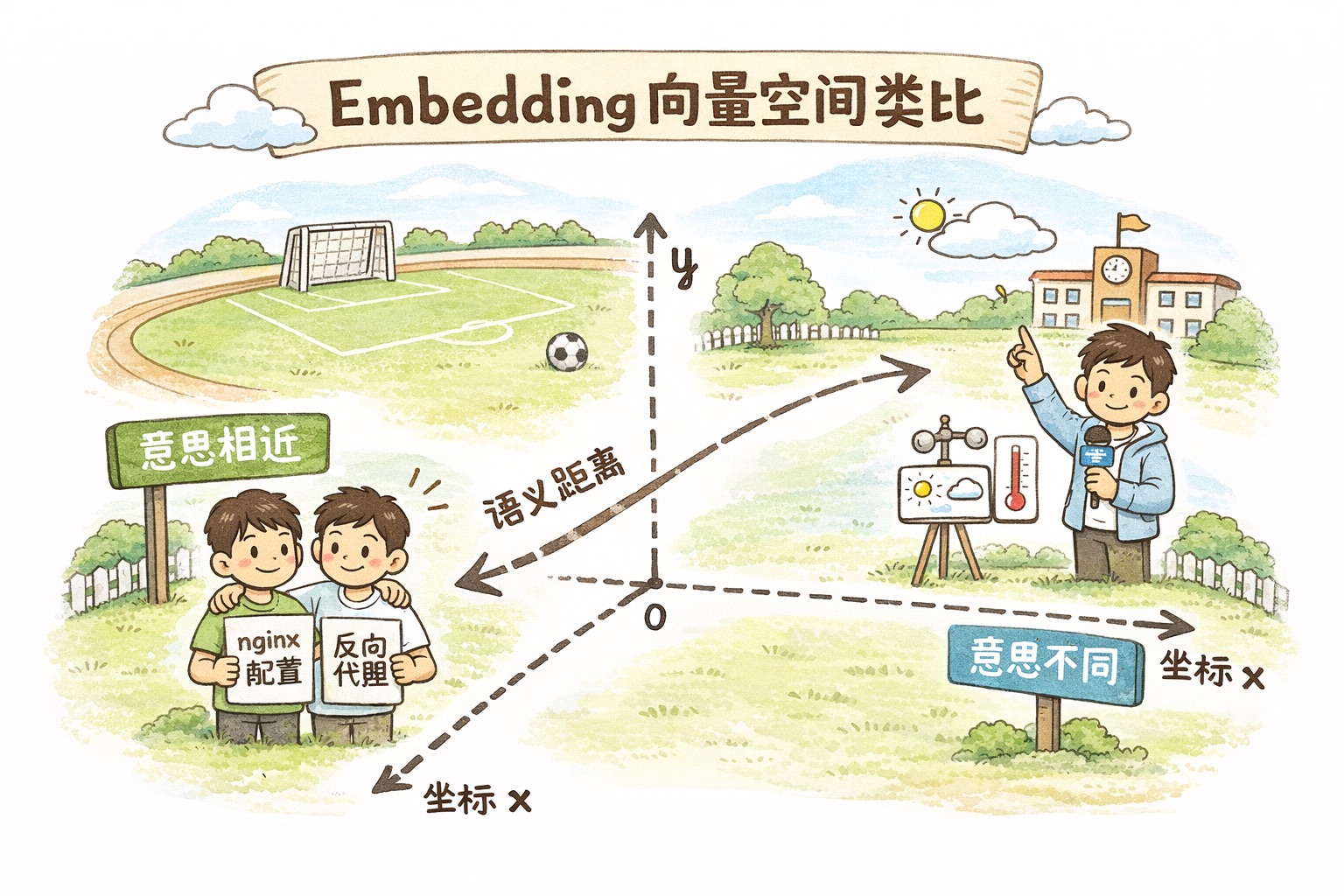
想象每段文字都是一个人,站在一个巨大的操场上。意思相近的人站得近,意思不同的人站得远。“如何配置 nginx"和"nginx 反向代理设置"这两个人几乎肩并肩,而"今天天气真好"则站在操场对角线的另一头。
Embedding 做的事情就是给每段文字分配一个"坐标”。这个坐标不是二维的,而是上千维的(别试图想象,想象不了),但道理是一样的:语义越接近,坐标距离越近。
有了坐标,搜索就变成了"找最近的邻居"。你的提问被转换成一个坐标,然后在所有文档的坐标中找最近的几个。
这比关键词搜索强在哪?关键词搜索只认字面匹配,你搜"怎么让网站变快",它找不到"Web 性能优化指南"这篇文章,因为一个词都没对上。Embedding 搜索能理解两句话说的是同一件事。
四步搭建 RAG 系统(附完整代码)
原理讲完了,上代码。
第一步,把你的文档切成小块。
一整本书塞给 AI 不现实,上下文窗口塞不下。你得把文档切成合适大小的块,每块大概 200-500 个 token。
def chunk_text(text, chunk_size=400, overlap=50):
"""把长文本切成有重叠的小块"""
words = text.split()
chunks = []
for i in range(0, len(words), chunk_size - overlap):
chunk = ' '.join(words[i:i + chunk_size])
chunks.append(chunk)
return chunks
# 把你的文档切块
documents = [
"PostgreSQL 18 引入了基于 io_uring 的异步 IO...",
"Redis 缓存层的真实延迟不是命中时的延迟...",
"B 树跳跃扫描可以跳过复合索引的前导列...",
]
这里有个细节:块和块之间要有重叠。不然一个关键信息正好被切成两半,两边都不完整,搜索的时候就找不到了。就像你撕报纸叠鞋垫,撕的时候尽量别从文章正中间下手。
第二步,给每块文档生成 Embedding。
Anthropic 推荐用 Voyage AI
的 Embedding 模型,当前最新的是 voyage-3.5,支持 32000 token 的上下文长度,生成 1024 维的向量。
import voyageai
import numpy as np
vo = voyageai.Client()
# 给文档生成向量(注意 input_type="document")
doc_embeddings = vo.embed(
documents,
model="voyage-3.5",
input_type="document"
).embeddings
注意 input_type="document" 这个参数别丢。Voyage 会根据类型在文本前面加不同的指令前缀,查询用 "query",文档用 "document"。加了类型标注比不加检索质量更高,Voyage 自己测过。
第三步,用户提问时,搜索最相关的块。
def search(query, doc_embeddings, documents, top_k=3):
"""语义搜索:找到最相关的文档块"""
# 给问题也生成向量
query_embd = vo.embed(
[query],
model="voyage-3.5",
input_type="query"
).embeddings[0]
# 算相似度(Voyage 的向量已经归一化了,点积就是余弦相似度)
similarities = np.dot(doc_embeddings, query_embd)
# 取最相关的 top_k 个
top_indices = np.argsort(similarities)[-top_k:][::-1]
return [(documents[i], similarities[i]) for i in top_indices]
results = search("io_uring 性能提升多少", doc_embeddings, documents)
第四步,把检索结果塞给 Claude,让它开卷答题。
import anthropic
client = anthropic.Anthropic()
def rag_answer(query, retrieved_docs):
"""带着检索结果让 Claude 回答"""
context = "\n\n---\n\n".join([doc for doc, score in retrieved_docs])
response = client.messages.create(
model="claude-sonnet-4-5-20250514",
max_tokens=1024,
messages=[{
"role": "user",
"content": f"""根据以下参考资料回答问题。如果资料中没有相关信息,请明确说明。
参考资料:
{context}
问题:{query}"""
}]
)
return response.content[0].text
四步走完,一个基础的 RAG 系统就搭好了。你的 AI 从此不用靠猜了。
Contextual Retrieval:检索失败率降低 67% 的方法
上面的基础版有个问题。
假设你的知识库里有一段话:“该公司第三季度的收入增长了 15%。” 你把它切成块之后,这段话就变成了一个孤零零的句子。“该公司"是哪家公司?“第三季度"是哪一年的?上下文丢了。
传统 RAG 就像你从一本书里撕下一页纸,光看这一页你可能搞不清楚它在说什么。
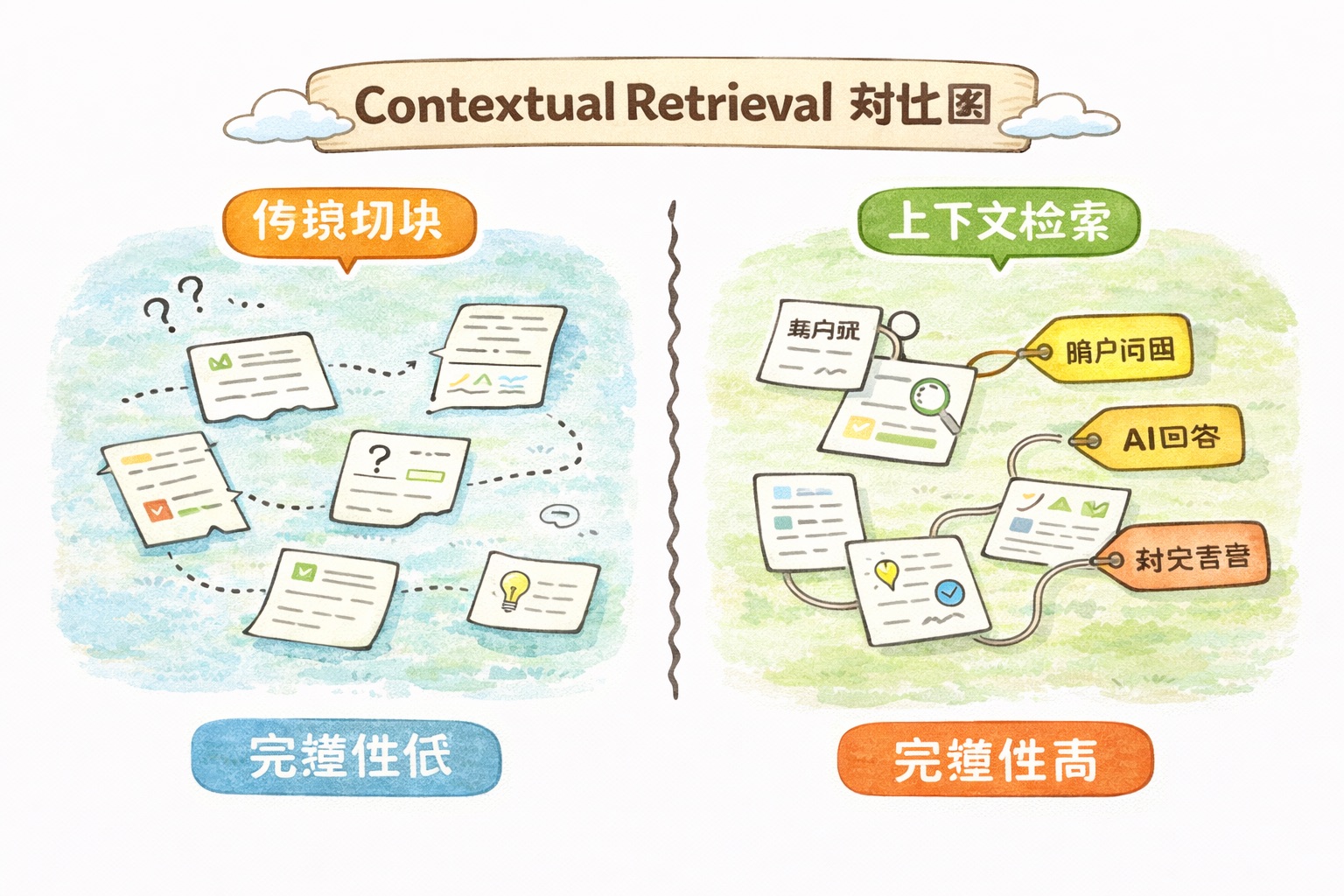
Anthropic 在 2024 年底提出了 Contextual Retrieval (上下文检索)来解决这个问题。做法不复杂:切块之后、生成 Embedding 之前,先让 Claude 给每个块加一段"上下文说明”。
比如那段"该公司第三季度的收入增长了 15%",Claude 会在前面加上:“这段内容来自苹果公司 2025 年度财报,讨论的是 2025 年第三季度的财务表现。” 这样一来,即使块被单独拿出来,信息也是完整的。
效果怎么样?Anthropic 的实测数据:
| 方案 | 检索失败率 |
|---|---|
| 传统 Embedding | 5.7% |
| Contextual Embedding | 3.7%(降低 35%) |
| Contextual Embedding + BM25 | 2.9%(降低 49%) |
| 上面全加上 Reranking | 1.9%(降低 67%) |
检索失败率从 5.7% 降到 1.9%。
成本也低。利用 Claude 的 Prompt Caching(提示缓存),给一百万 token 的文档做上下文标注大约 1 美元。一本 30 万字的技术手册,几块钱处理完。
RAG 适用场景判断
别什么场景都上 RAG。
知识库小于 20 万 token(大约 15 万字)的,直接塞进提示词就行。Claude 的上下文窗口有 200K token,一本小书直接放进去,比搞一套 RAG 管线简单太多了。你家厨房就三个抽屉,没必要建一套仓库管理系统来找开瓶器。
需要 RAG 的场景:
- 企业知识库,几十万到几百万字的文档
- 频繁更新的内容,比如产品手册、API 文档
- 需要精确引用来源的场景,比如法律、医疗咨询
- 多个不同来源的知识需要整合
不太需要 RAG 的场景:
- 通用知识问答,大模型自己就知道
- 数据量很小,直接塞上下文更简单
- 需要推理而不是检索的任务
RAG 常见问题和避坑指南
块切得太小或太大。
切太小,每块信息不完整,AI 答得支离破碎。切太大,检索精度下降,一大段里面有用的就一句话。一般 200-500 token 是个比较好的范围,但具体要根据你的文档类型调。技术文档可以切大一点,因为一个概念往往需要一段完整的描述;FAQ 类的可以切小一点,一问一答就是一块。
只用语义搜索。
Embedding 搜索擅长理解意思,但对精确术语匹配不太行。你搜"ERR_CONNECTION_REFUSED”,语义搜索可能给你返回一堆关于"网络连接问题"的泛泛内容,而不是精确匹配这个错误码的解决方案。
办法是语义搜索 + BM25 关键词搜索混合使用。两种方式各取 top-20,合并去重,再用 Reranking 模型排序。Anthropic 的数据显示,混合方案比单用语义搜索检索失败率降 49%。
检索到了不相关的内容还硬用。
有时候知识库里确实没有答案,但系统还是会返回"最相关"的几个块(只是相似度最高的,不代表真的相关)。AI 拿到这些似是而非的内容,可能会生成一个看起来合理但实际上驴唇不对马嘴的回答。
办法是设一个相似度阈值。低于阈值的检索结果直接丢掉,让 AI 老老实实说"我在现有资料中没有找到相关信息"。诚实比瞎编值钱。
忘了更新索引。
文档更新了但 Embedding 没重新生成,AI 还在用旧信息回答。这种错误隐蔽,AI 的回答格式完美、逻辑通顺,就是内容过时了。定时任务跑起来,文档有变动就重新索引。
Voyage AI Embedding 模型选型对比
Anthropic 官方推荐 Voyage AI 的模型,目前有几个选择:
| 模型 | 适用场景 | 上下文长度 |
|---|---|---|
| voyage-3.5 | 通用检索,性价比最优 | 32,000 token |
| voyage-3-large | 最高检索质量 | 32,000 token |
| voyage-3.5-lite | 低延迟、低成本 | 32,000 token |
| voyage-code-3 | 代码检索 | 32,000 token |
| voyage-finance-2 | 金融领域 | 32,000 token |
| voyage-law-2 | 法律领域 | 16,000 token |
如果你不知道选哪个,voyage-3.5 稳。做代码相关的用 voyage-code-3,做金融用 voyage-finance-2。专用模型在对应领域的检索质量比通用模型高不少。
Voyage 还支持向量量化。原始的 32 位浮点向量可以压缩成 8 位整数甚至 1 位二进制,存储空间分别缩小 4 倍和 32 倍。大规模知识库省存储,检索也更快。
今天就能动手
看到这里别光收藏。
选你团队最常查的一份文档,用上面的代码切块、生成 Embedding、存到一个 numpy 数组里。半小时的事。四步代码拼在一起不到 50 行,跑起来对着你的文档问几个问题,感受一下。
然后拿同一个问题,分别用纯 Claude 和 RAG + Claude 回答,对比差别。特别是涉及你们公司内部信息的问题,差距会让你想骂人 – 为什么不早点搞。
说白了 RAG 就是给 AI 配了一本参考书。这本书可以是你的产品文档、公司 Wiki、历史工单,甚至整个维基百科。AI 不用再靠那些可能过时的"记忆"硬撑了。
你的业务场景里,最想让 AI “翻"哪本书?是公司的内部文档,还是某个技术领域的知识库?评论区聊聊,说不定你的需求也是别人正在解决的问题。
下一篇聊聊 Claude 的 Tool Use,让 AI 不光能查资料,还能调接口、查数据库、发通知。从"只会说"到"能动手”。
参考资料:
- Anthropic: Contextual Retrieval
- Anthropic Docs: Embeddings
- Anthropic Cookbook: Wikipedia Search
- Voyage AI Embedding Models
觉得有用就点个赞。有朋友也在折腾 AI 应用的,转给他看看。关注梦兽编程,后面还有更多实战内容。