pgvector 0.8.0 来了,PostgreSQL 用户还需要专用向量数据库吗?
你的 CTO 刚批了一份 5 万美元的 Pinecone 年度合同。
两周后,你们的实习生用 47 分钟,把向量搜索加到了现有的 PostgreSQL 数据库里。免费的。
这个场景正在无数公司上演。
向量数据库的"黄金时代"
还记得 2023 年那会儿吗?ChatGPT 火了之后,所有人都在说你需要一个专门的向量数据库来存 embedding。Pinecone 融了 1.38 亿美元,Weaviate 成了独角兽,每个创业公司的 PPT 第三页都写着"Powered by XXX 向量数据库"。
那时候的销售话术很简单:传统数据库搞不定这个,你需要专门的基础设施,你需要我们。
听起来很有道理。HNSW 算法、近似最近邻搜索这些词,听着就很高大上。
但大多数公司本来就有一个很好用的数据库:PostgreSQL。
PostgreSQL 说:其实你可以的
开发者们问了一个很朴素的问题:能不能直接在 Postgres 里加向量搜索?
向量数据库厂商说不行,还写了一堆博客解释为什么你需要专门的基础设施。
然后 pgvector 来了,说其实可以。
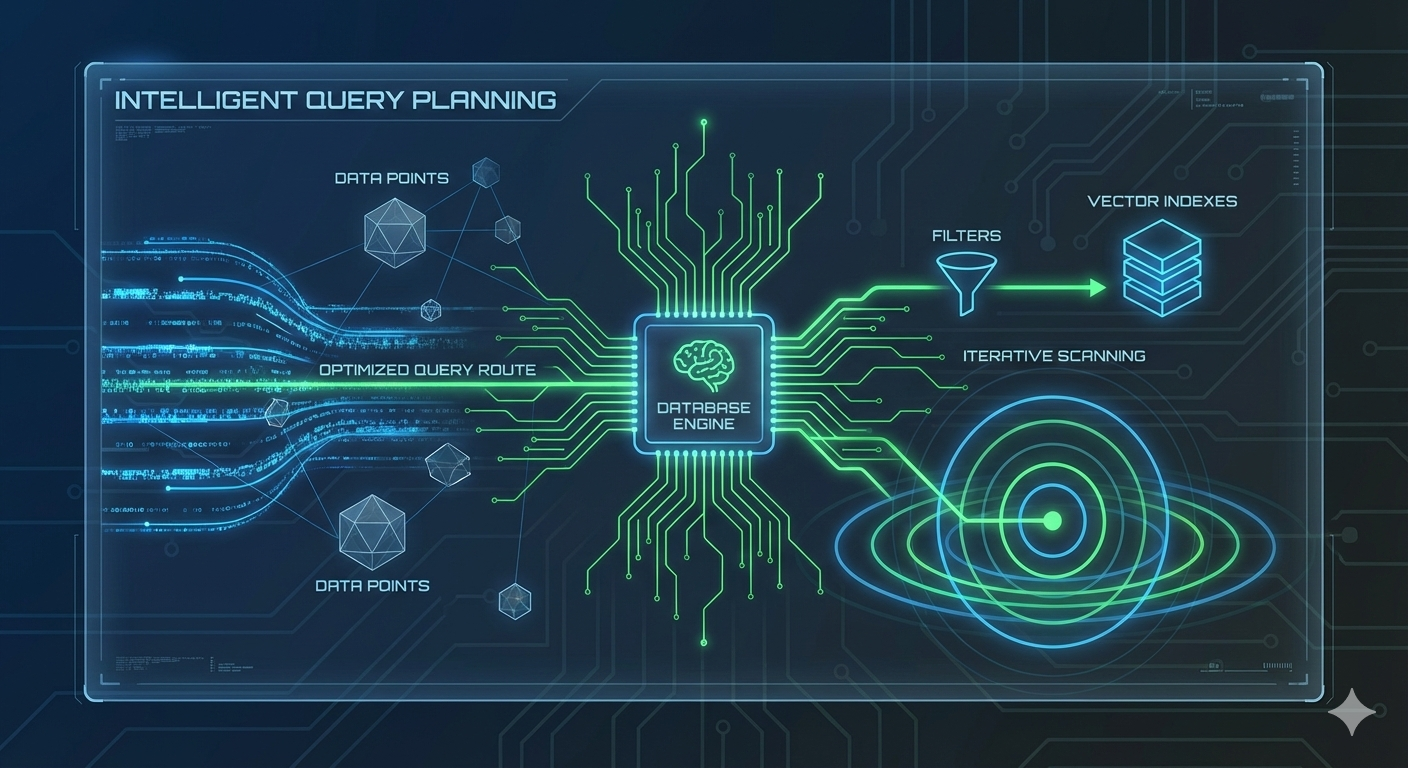
pgvector 0.8.0 版本加了两个改变游戏规则的功能。
迭代式索引扫描。当你用元数据过滤向量的时候,比如"找相似的产品,但价格要低于 50 块",pgvector 现在可以增量扫描,直到找到足够的结果。以前可能因为过滤条件太严格就返回空结果,现在不会了。
更智能的查询规划。Postgres 现在知道什么时候该用普通索引、什么时候该用向量索引。比如你查"价格在 10-20 块之间的相似商品",它会先用价格索引过滤,再做向量搜索。
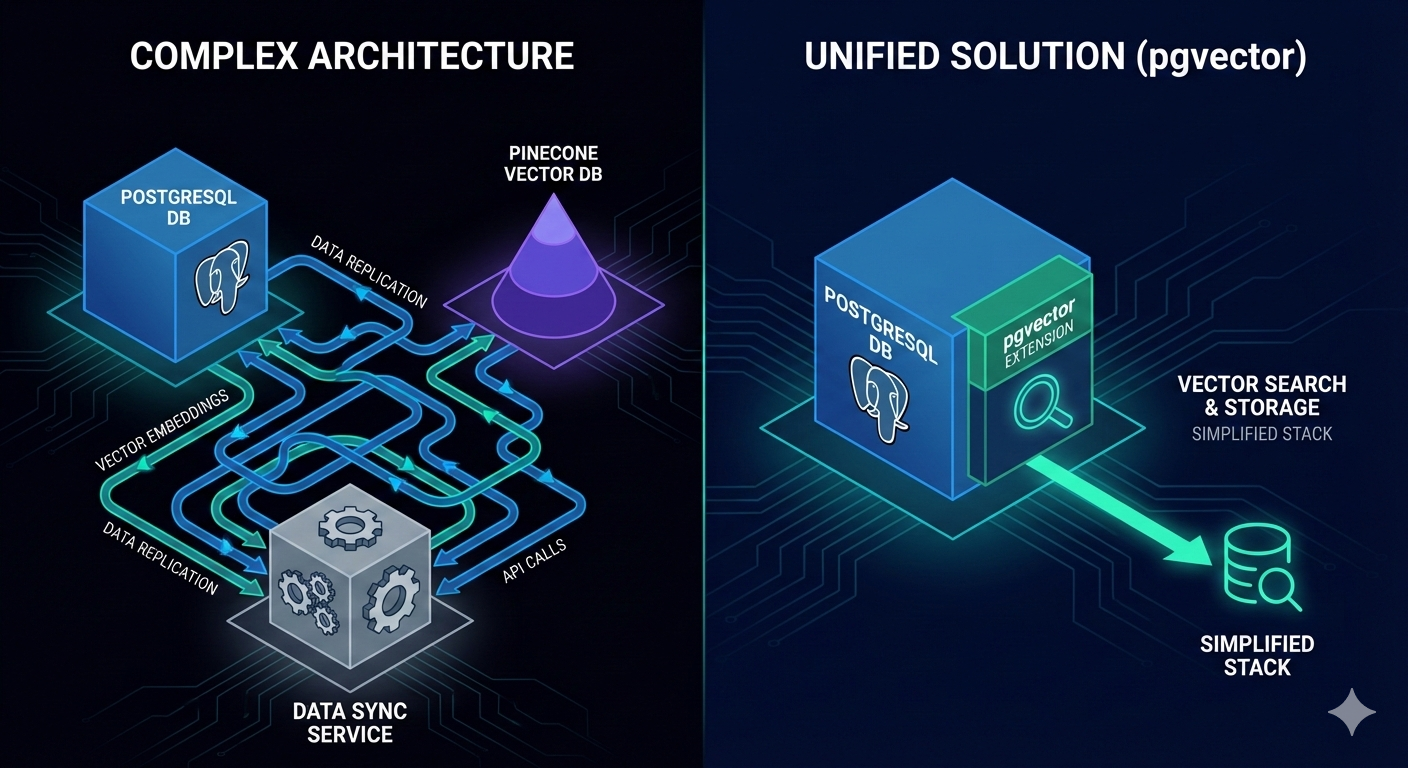
一个数据库搞定所有事
用专用向量数据库的架构是这样的:
应用 → PostgreSQL(业务数据)
→ Pinecone/Weaviate(向量数据)
→ 数据同步服务(保持两边一致)
用 pgvector 的架构是这样的:
应用 → PostgreSQL + pgvector(全部搞定)
没有数据同步,没有最终一致性的 bug,没有第二个数据库要监控、备份、扩容。就一个数据库,干数据库该干的事。
这就像你本来有个全能的瑞士军刀,非要再买一把专门开瓶盖的开瓶器。大多数时候没必要。
性能差距在缩小
向量数据库厂商最爱聊性能基准测试。
但他们不告诉你的是:pgvector 0.7.0 就已经支持半精度向量、最高 4000 维的索引、以及最高 64000 维的二进制量化。
原始搜索速度往往不是你的瓶颈。真正的瓶颈是应用服务器和向量数据库之间的网络延迟,是 Postgres 和向量存储之间的数据同步延迟,是不理解你过滤条件的查询规划。
pgvector 把这些问题全解决了,因为数据就在同一个地方。
什么时候还需要专用向量数据库?
向量数据库不是完全没用。几十亿条向量需要分布式架构、每一毫秒都很重要的实时推荐系统、或者没有现成的 Postgres 基础设施,这些场景确实需要专门的方案。
但大多数公司有几百万条向量、复杂的过滤条件、现成的 Postgres 基础设施。对他们来说,pgvector 不是妥协,是更好的选择。
怎么开始?
如果你已经在用 Postgres,三步搞定:
-- 1. 安装扩展
CREATE EXTENSION vector;
-- 2. 给表加个向量列
ALTER TABLE products ADD COLUMN embedding vector(1536);
-- 3. 建个索引
CREATE INDEX ON products USING ivfflat (embedding vector_cosine_ops);
没有新数据库,没有数据迁移,没有运维复杂度。
记住这三点
- pgvector 0.8.0 的迭代扫描和智能查询规划,让 Postgres 原生向量搜索真正可用了
- 对于百万级向量加复杂过滤的场景,pgvector 性能完全够用,还省了数据同步的麻烦
- 在签那份向量数据库合同之前,先问问自己:我真的需要另一个数据库吗
向量数据库的炒作周期结束了。不是因为它们不好,而是因为对大多数场景来说,它们没必要。
Postgres 已经在生产环境跑了 30 年,它还能继续跑下去。
你现在的 AI 应用用的是什么方案? 是专用向量数据库,还是已经在用 pgvector 了?欢迎在评论区聊聊你的选择和踩过的坑。
下一篇我们聊聊 pgvector 的进阶用法:如何针对不同场景选择 IVFFlat 还是 HNSW 索引,以及怎么调参让查询更快。