PostgreSQL 查询解析慢成狗?PgDog 把 Protobuf 扔了,直接快 5 倍

你的 SQL 代理慢?可能不是解析慢,是中间商赚差价
前两天看到 PgDog 团队发了篇博客,标题挺直接的:《Replacing Protobuf with Rust to go 5 times faster》。
PgDog 是个用 Rust 写的 PostgreSQL 代理,干分库分表和查询重写的活。他们发现一个挺离谱的事情:SQL 解析慢,不是 PostgreSQL 解析器本身慢,而是 Protobuf 序列化在中间拖后腿。
然后他们把 Protobuf 扔了。
一个代理为什么要在乎 SQL 解析?
PgDog 是个 PostgreSQL 代理,放在应用和数据库中间。它拿到一条 SQL,要解析成 SQL 语法树,做指纹识别、查询重写,有时候还要把语法树转回 SQL 文本。
作为代理,延迟预算很紧。多耽误一毫秒,用户都能感觉到。
PgDog 用的是 pg_query.rs 来干这活,底层调的是 libpg_query,也就是 PostgreSQL 原生解析器的一层包装。但 pg_query.rs 为了跨语言兼容(Ruby、Go 那些也能用同一套结构),中间加了一层 Protobuf 来序列化 AST。
Protobuf 快不快?快。但它得先把 C 的结构体序列化成字节,再反序列化成 Rust 能用的结构。
PgDog 团队拿 samply 采样了一下火焰图,pg_query_parse_protobuf 这个函数占了大把 CPU 时间。真正的 PostgreSQL 解析器 pg_query_raw_parse?几乎看不见。
打个比方:你让同事传个文件,他不直接发邮箱,偏要先打印出来,扫描成 PDF,再发给你。能快才怪。
缓存试过了,不够
加缓存是第一反应。LRU 缓存,查询文本当 Key,AST 当 Value。用 Prepared Statement 的场景效果不错,因为查询文本固定,不用重复解析。
但两个情况会让缓存失灵:
有些 ORM 会生成一堆不同的查询。比如:
-- ORM 生成的,每次参数个数不一样,缓存直接打水漂
SELECT * FROM users WHERE id IN ($1, $2, $3, $4, $5, ...);
-- 其实应该写成这样
SELECT * FROM users WHERE id = ANY($1);
还有老旧客户端驱动根本不支持 Prepared Statement,每次发的 SQL 都不一样。
缓存帮了一点忙,但火焰图里 Protobuf 还是大户。
把 Protobuf 扔了,直接连 C
PgDog 团队 fork 了 pg_query.rs,把 Protobuf 序列化那层换成了直接的 C 到 Rust 绑定:
- 用
bindgen从libpg_query的 C 头文件直接生成 Rust 结构体 - 手写
unsafe包装函数,把 C 的 AST 节点转成 Rust 结构 - 原来的 Protobuf 结构体没删,留着做对比测试
这活很枯燥,6000 行递归 Rust 代码,手动映射 C 类型到 Rust 类型。但好处是结果完全可以验证:对每个测试用例同时跑 parse(Protobuf 路径)和 parse_raw(直接 FFI 路径),只要有一个字节不一样,测试就挂掉。
他们用 Claude 生成了不少这类重复性的胶水代码。给定明确的输入输出规范,让 AI 干这种可验证的苦力活,效果确实不错。
为什么用递归?
转换 C 结构体到 Rust 结构体,PgDog 选了递归。AST 本身就是树,每个节点可能有子节点,碰到子节点就递归调用。
unsafe fn convert_node(node_ptr: *mut bindings_raw::Node) -> Option<protobuf::Node> {
if node_ptr.is_null() {
return None;
}
match (*node_ptr).type_ {
bindings_raw::NodeTag_T_SelectStmt => {
let stmt = node_ptr as *mut bindings_raw::SelectStmt;
Some(protobuf::node::Node::SelectStmt(
Box::new(convert_select_stmt(&*stmt))
))
}
// ... 还有上百种节点类型
_ => None,
}
}
递归在这个场景下比迭代快。栈空间程序启动就分配好了,不用额外堆分配;同一函数的指令在 CPU 缓存里热着;而且树结构用递归写出来,人看着也直觉。
他们试过迭代版本,反而更慢 – 多了 HashMap 查找和额外的内存分配,开销比 Protobuf 还大。
数字说话
PgDog 在 GitHub 上放了 benchmark:
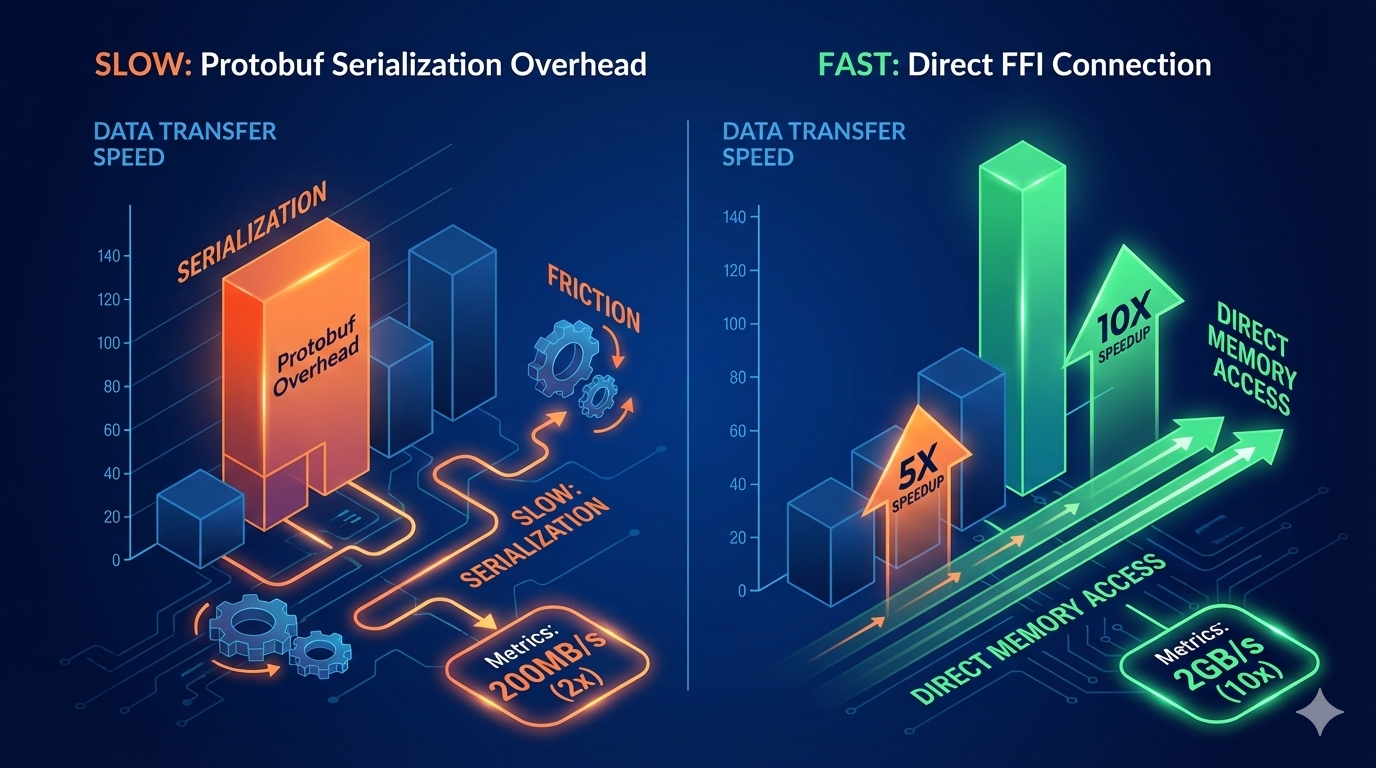
| 功能 | Protobuf 路径 | 直接 FFI 路径 | 提升倍数 |
|---|---|---|---|
| 解析 (parse) | 613 查询/秒 | 3,357 查询/秒 | 5.45x |
| 反解析 (deparse) | 759 查询/秒 | 7,319 查询/秒 | 9.64x |
实际跑 pgbench,整体吞吐量提了 25%。解析本身快了,查询重写引擎压力小了,缓存命中也更稳定。
踩过的坑
ABI 漂移。 PostgreSQL 升级可能改 AST 节点定义。bindgen 生成的代码跟着变,不锁版本的话,升个数据库就编译不过了。他们在 CI 里锁死了 PostgreSQL 头文件版本。
空指针。 FFI 这块,每个指针都得当敌人看。C 传过来的东西,不检查 is_null() 就用,迟早出事。他们的做法是每个 unsafe 块尽量小,进来先验指针,出去就是 safe 的 Rust 类型。
跨语言兼容。 如果团队里有 Ruby、Go、Python 的人依赖 Protobuf 结构,schema 还是得留着。PgDog 只是自己内部不走 Protobuf 了。
要抄作业的话
PgDog 给了几条建议,我觉得挺实在的:
先拿 samply 加 Firefox profiler 跑个火焰图,别猜。保留 Protobuf 做对照测试,新老路径输出必须完全一致。CI 里锁定 PostgreSQL 头文件版本,AST 结构变了要有人 review。加个 feature flag 或者环境变量,能随时切回 Protobuf 路径。unsafe 块写小点,对外只暴露 safe 接口。
他们还建议弄双路径实现,环境变量控制走哪条路,出了问题秒级回滚,不用重新发版。
最后
这个案例挺有意思的。性能瓶颈不在你觉得会慢的地方(PostgreSQL 解析器),而在一个看起来"标准"的中间层(Protobuf 序列化)。在 SQL 解析这种高频调用的场景下,每一层抽象都有成本。PgDog 选择为了性能优化放弃跨语言的便利,直接把 C 和 Rust 连起来,效果立竿见影。
当然,不是所有场景都值得这么干。如果你的解析频率没那么高,Protobuf 的那点开销根本不是问题。工程就是取舍。
觉得有用的话,点个赞或者转发一下,让更多人看到。有问题评论区聊。
你项目里遇到过什么"看着不起眼但拖了大后腿"的性能问题?