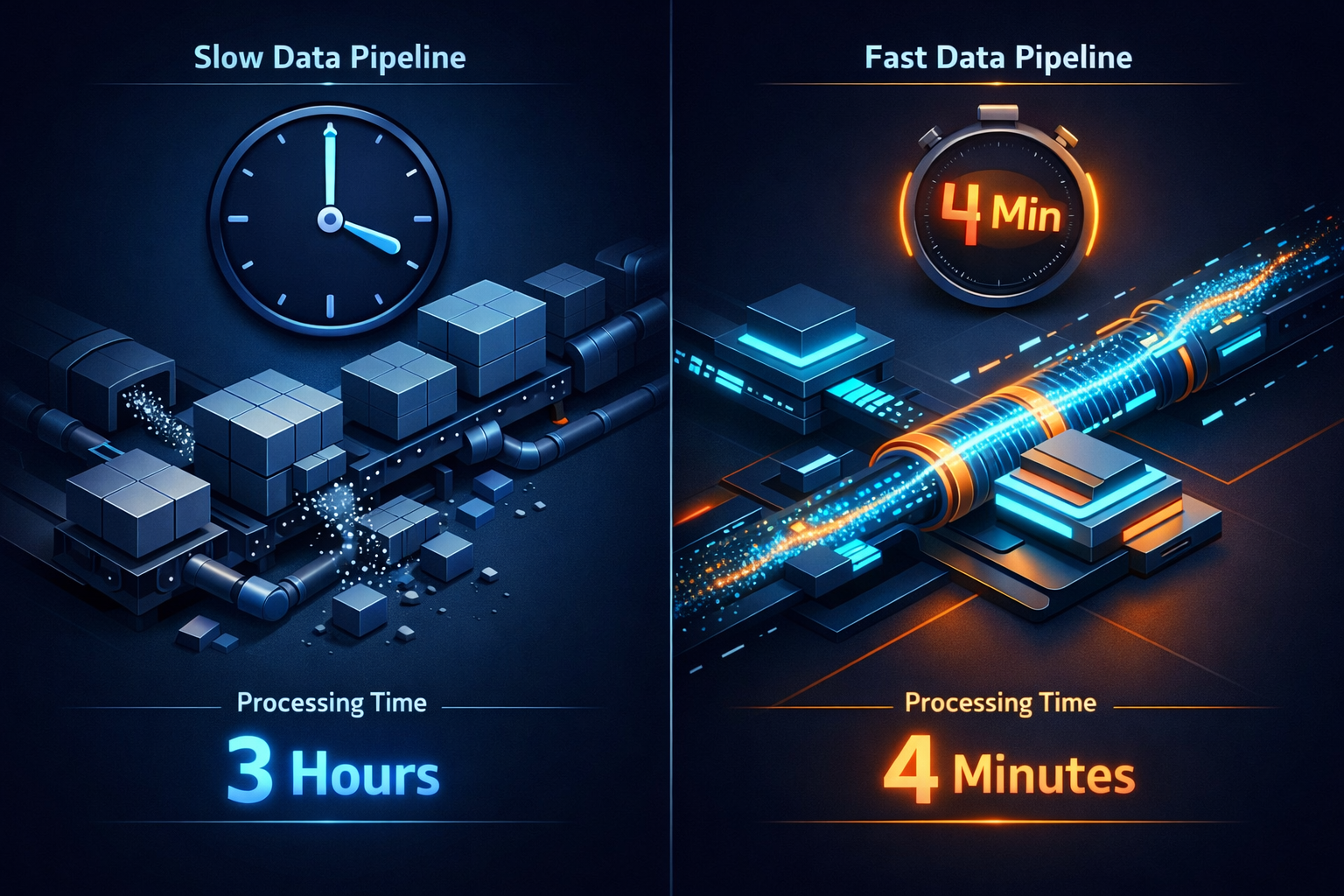
数据管道正在慢慢死去
不是那种轰轰烈烈的崩溃,是那种就像看着油漆一点点干掉,同时你的服务器账单蹭蹭往上涨的那种死法。每天早上 6 点,我们的 Python 脚本准时醒来,开始它漫长的三小时旅程——处理 50GB 的 CSV 文件。到早上 9 点,它终于跑完,12GB 内存吃掉了,一个月下来服务器费用烧掉好几千。我就这么忍了八个月。
然后有一个周五,老板问我:“能不能改成每小时处理一次,而不是每天一次?“我笑了,然后我发现他是认真的。
那个周末,我用 Rust 和 DuckDB 把整个管道重写了。周一早上,同样的任务跑完了——4 分半钟,600MB 内存。来,我给你讲讲这是怎么回事。
那个跑不动的 Python 管道
先给你看看我们原来的代码长什么样,看起来挺人畜无害的:
import pandas as pd
import glob
files = glob.glob("data/*.csv")
dfs = [pd.read_csv(f) for f in files]
df = pd.concat(dfs, ignore_index=True)
df = df.dropna()
df['date'] = pd.to_datetime(df['date'], errors='coerce')
df = df[df['quantity'] > 100]
result = df.groupby('product_id')['revenue'].mean()
result.to_parquet('output.parquet')
代码干净,可读性好,但在生产环境里这玩意儿就是个噩梦。问题出在 Pandas 的"贪婪加载"上——虽然我们可以试着搞一些复杂的分块策略,或者手动管理内存,但 Python 终究还是在试图把 50GB 的原始数据、200 多个文件全部塞进内存里。还没等 CPU 成为瓶颈呢,Python 的内存模型和执行机制就先扛不住了。数据量一大,Python 不只是变慢,它开始疯狂 swap 磁盘,然后直接把我们配置低一点的云服务器给搞崩了。
“用 Spark 啊”——这个话题
在你留言之前,是的,我们考虑过 Spark,我们甚至试了。Spark 确实能跑,但这意味着:跑一个集群(至少 3 个节点才能保证稳定),学 JVM 调参和 Spark 的执行模型,空闲的时候也得付基础设施的钱,又多了一层复杂度。
对于我们的场景——一个简单直接的 ETL 任务,需要跑得快但不需要分布式——Spark 就是在用火箭炮打蚊子。我们需要的是:单机能跑,不浪费资源,喝完第一杯咖啡之前能跑完。
Rust + DuckDB 登场
我一直听说 DuckDB,号称"分析界的 SQLite”,它承诺用 Pandas 几分之一的内存,跑出更快的速度。但光有 DuckDB 还不够,我需要编排整个管道、优雅地处理错误、维护业务逻辑,这就是 Rust 出场的地方。新管道长这样:
use duckdb::{params, Connection, Result};
fn main() -> Result<()> {
let conn = Connection::open("analytics.db")?;
conn.execute("
SELECT
product_id,
AVG(revenue) as avg_revenue
FROM read_csv_auto('data/*.csv')
WHERE quantity > 100
GROUP BY product_id
", params![])?;
let mut stmt = conn.prepare(
"COPY (SELECT * FROM results) TO 'output.parquet' (FORMAT PARQUET)"
)?;
stmt.execute(params![])?;
Ok(())
}
编排代码少了一大截,大部分重活都交给了 DuckDB 的执行引擎。但最妙的是:DuckDB 不会把所有东西都加载进内存,它流式处理数据,分块处理,用列式存储来优化分析查询。
数据不会说谎
我在生产数据集上跑了两个管道,同样的数据,同样的机器(8核16G的云服务器),各跑五次:
Python + Pandas: 平均时间 2 小时 47 分钟,内存峰值 11.8 GB,CPU 使用率 95%(单核)
Rust + DuckDB: 平均时间 4 分 12 秒,内存峰值 580 MB,CPU 使用率 85%(多核)
提升?40 倍速,95% 内存节省。这就是 Rust 性能优化的威力。但真正让我惊喜的是成本——我们的"每小时处理一次"突然变得可能了。原来跑三小时的数据管道,现在五分钟不到就跑完,我们从每天批处理,变成了实时洞察。
DuckDB 为什么是秘密武器
DuckDB 不只是快,它聪明。当你写 read_csv_auto('*.csv') 的时候,DuckDB 会自动检测 schema(再也不用头疼 dtype 了),只读需要的列(列式处理),自动在多个 CPU 核心上并行(你什么都不用做),分块流式处理数据(内存占用恒定)。对比一下 Pandas,它会先把所有东西都加载进内存,再开始处理。
来看个实际的例子,这个 DuckDB 查询:
SELECT
product_id,
AVG(revenue) as avg_revenue
FROM read_csv_auto('data/*.csv')
WHERE quantity > 100
GROUP BY product_id
用 Pandas 要这么写:
# 先把所有文件加载进内存
dfs = [pd.read_csv(f) for f in files]
combined = pd.concat(dfs)
# 然后过滤和聚合
result = combined[combined['quantity'] > 100] \
.groupby('product_id')['revenue'] \
.mean()
DuckDB 处理这个,根本不需要把整个数据集加载进内存,它读、过滤、聚合,一次流式完成。

Rust 学习曲线(说点实话)
我不会假装 Rust 很容易。借用检查器连着骂了我两天,用 Result<T> 处理错误感觉好啰嗦,我想念 Python 的鸭子类型。但这是我得到的:没有垃圾回收的内存安全,再也不会因为 Python 的 GC 在处理中途突然启动,导致莫名其妙的性能抖动;无畏并发,当我需要加并行文件校验的时候,Rust 的类型系统在编译期就帮我抓住了竞态条件;零成本抽象,代码读起来很干净,但编译出来的机器码能和手写优化的 C 媲美。
一个星期之后,我不再跟编译器较劲了,开始信任它,每一条报错信息都变成了一堂如何写更好代码的课。
处理真实世界的脏数据
生产数据从来都不干净。我们的 CSV 有不统一的日期格式、缺失值、损坏的行、处理过程中突然出现的新文件。Rust 版本优雅地处理了这些——DuckDB 的 ignore_errors 参数意味着损坏的行会被跳过,而不是让整个管道崩溃;文件在处理过程中出现怎么办?glob 模式 'data/*.csv' 会在下一次运行时自动识别到它们,不需要复杂的文件监控。
迁移策略
我们没有一键切换,这是我们实际的推进方式:第一周构建 Rust 管道,验证输出和 Python 版本完全一致;第二周两个管道并行跑,每天对比结果;第三周 Rust 管道转正,Python 作为备用;第四周下线 Python 管道。关键是字节级的输出对比,我写了一个简单的验证器。这给了我们信心,当利益相关方问"你确定这玩意儿能跑?“的时候,我直接把验证报告甩给他们看。
如果让我重来
如果今天重新开始,我会:先在 Python 里用 DuckDB,你可以在 Python 里用 DuckDB(import duckdb),先拿到性能提升,不用重写所有东西;优化之前先 profile,我以为我知道瓶颈在哪,profile 之后发现了惊喜——30% 的时间花在日期解析上;尽早投入日志,Rust 的 tracing crate 很强大,但我加得太晚了,没有合适的日志来调试,真的很痛苦;从第一天就写集成测试,单元测试很好,但对于数据管道,你需要端到端的验证。
最后说几句
这不是 Rust vs Python 或者黑 Pandas,两个工具在各自的场景下都很强。但当你要反复处理几十个 GB 的数据时,性能差距就很重要了——对你的服务器账单重要,对你团队的生产力重要,对等着看新鲜数据的用户重要。
Rust + DuckDB 这套组合给了我们 40 倍的处理速度提升(从小时级到分钟级),95% 的内存节省(12GB 到 600MB),67% 的成本降低(更小的实例,更短的运行时间),实时更新能力(从每天一次到每小时一次)。更重要的是,这次性能优化释放了我的心智负担,不用再盯着失败的 ETL 任务,不用再解释为什么报告又延迟了。
我会用 Rust 重写所有东西吗?不会。但对于那些反复运行的数据密集型 ETL 管道,这套性能优化组合真的很难被打败。
如果你也想试试,建议先从 Python 里的 DuckDB 开始,把你的 pd.read_csv() 换成 DuckDB 的 read_csv_auto(),不用重写所有东西,性能提升立竿见影。
觉得有用的话,顺手点个赞让更多人看到。身边有同事还在被数据管道折磨的,转发给他看看。关注梦兽编程,咱们下篇见。你的数据管道一般要跑多久?评论区聊聊,说不定下次就写你的故事。