500行Rust代码,10秒训练完成:从零手搓一个神经网络到底有多简单?

别被"神经网络"三个字吓住
说到神经网络,很多人脑子里立刻浮现的画面是:一个穿格子衫的博士,对着三块显卡嘀嘀咕咕,桌上堆满了线性代数的教材,显示器上飘着看不懂的希腊字母。
实际上呢?
神经网络的核心逻辑,跟你用Excel做一张成绩表差不多。输入一堆数字,乘以权重,加个偏差,看看结果对不对,不对就调整,反复来几百遍,完事。
今天我要带你做一件事:用Rust写一个能识别垃圾邮件的神经网络,一共500行代码,训练时间10秒,你家笔记本就能跑。 这可能是你见过最友好的Rust神经网络入门项目了。
不需要GPU,不需要Python。你需要的就是装好Rust的电脑和一点好奇心。
为什么选Rust搞机器学习?
很多人觉得Rust机器学习是个小众选择。但这个问题换个说法你就懂了:切牛排,你是拿菜刀还是拿塑料刀?塑料刀也能切,但那个手感差太远了。
Python搞机器学习确实方便,生态好,教程多。但它有几个让人抓狂的地方:
- Python跑推理就像老大爷遛弯,不急不慢。生产环境要的是百米冲刺。
- GIL锁就像一条单车道的桥,再多车也只能排队过。
- 你还得把整个PyTorch扛上服务器,光框架就好几个G,启动慢得让人心焦。
Rust呢?编译完就是一个二进制文件,扔到服务器直接跑。没有运行时开销,没有垃圾回收的停顿,内存用多少给多少。
而且Hugging Face专门给Rust写了一个轻量级机器学习框架叫 Candle。这个Candle框架在GitHub上拿了超过19000颗星,社区很活跃,算是目前Rust深度学习生态里最成熟的选择了。
Candle的想法很直接:API长得跟PyTorch很像,会写PyTorch的人上手几乎零成本,但底下跑的是Rust的速度。
我们要做什么?
目标很明确:一个垃圾邮件分类器。
你输入一句话,它告诉你这是垃圾邮件还是正常消息:
"Win money now" --> SPAM (100%)
"Hello friend" --> HAM (100%)
"Free iPhone click" --> SPAM (100%)
"See you tomorrow" --> HAM (100%)
就这么朴素。但别小看这个小项目,作为一个神经网络入门练手,你从中学到的东西,和那些动辄几百页教材讲的是同一套理论。
五步走完整个管道
整个系统的数据流长这样:
文本 --> 分词器 --> 嵌入层 --> 均值池化 --> 线性层 --> Softmax --> 预测结果
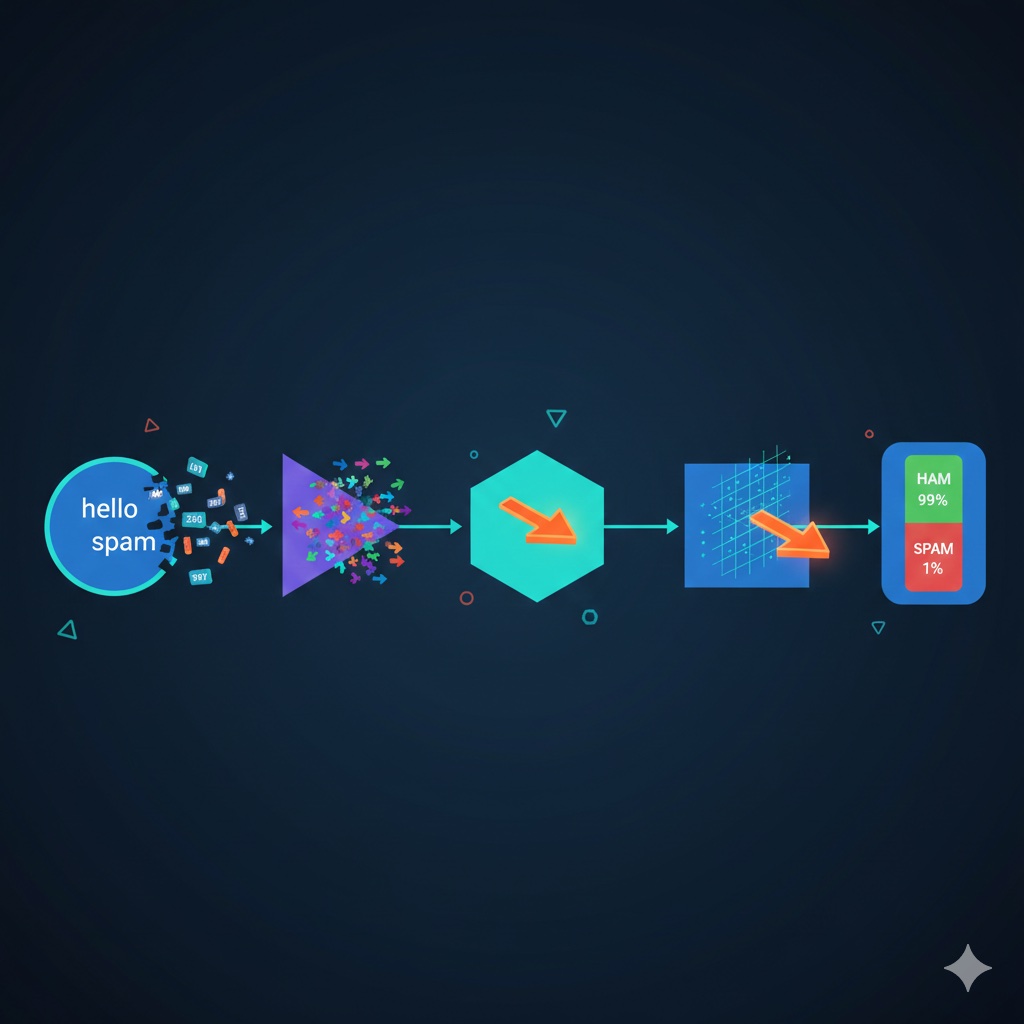
我打个比方。这就像一家餐厅处理点单的过程:
- 分词器是前台服务员,把顾客的话翻译成厨房看得懂的订单号
- 嵌入层是备料台,给每个食材编上一套营养数据
- 均值池化是搅拌机,把长短不一的食材打成统一大小的糊
- 线性层是大厨,看着这糊做出判断
- Softmax是出菜口,把大厨的判断变成一个明确的打分
下面每一步拆开讲。
第一步:分词器,把人话翻译成数字
神经网络不认字,只认数字。所以第一件事就是把文字翻译成数字。
怎么翻?很暴力,建一个字典,每个词分配一个编号:
"hello" --> 1
"friend" --> 2
"win" --> 3
"money" --> 4
这样"hello friend"就变成了[1, 2]。
没有什么黑科技。底层就是一个HashMap,键是单词,值是编号。你家里的电话簿其实就是个分词器——“老妈"对应"138xxxx”,“老板"对应"139xxxx”。
pub struct Tokenizer {
vocab: HashMap<String, u32>,
next_id: u32,
}
impl Tokenizer {
pub fn build_vocab(&mut self, texts: &[String]) {
for text in texts {
for word in text.to_lowercase().split_whitespace() {
if !self.vocab.contains_key(word) {
self.vocab.insert(word.to_string(), self.next_id);
self.next_id += 1;
}
}
}
}
pub fn encode(&self, text: &str) -> Vec<u32> {
text.to_lowercase()
.split_whitespace()
.filter_map(|w| self.vocab.get(w).copied())
.collect()
}
}
就这么几行,分词器完成了。
第二步:嵌入层,给每个词一个"性格"
光有编号还不够。编号1和编号2之间差1,编号1和编号100之间差99,但这不代表编号1和编号2更"像"。
嵌入层干的事是:给每个词分配一个16维的向量。你可以理解成给每个词写了一份16项的性格测试报告。
一开始这些性格是随机分配的,就像新生入学随便分宿舍。但训练几轮之后,意思相近的词会慢慢搬到一起住:
- “free”、“win”、“money"这些垃圾邮件常客,它们的向量会越来越接近
- “hello”、“friend”、“tomorrow"这些正常词,也会抱成一团
模型不是靠规则判断的,是自己发现了"什么样的词经常一起出现在垃圾邮件里”。
第三步:均值池化,把长短不一的句子统一规格
“Hi"是一个词,“Click here now free offer"是五个词。每个词都有一个16维向量。
问题来了:一个词产生一个16维向量,五个词产生五个16维向量。后面的线性层需要固定大小的输入,怎么办?
均值池化的做法简单粗暴:把所有词的向量加起来,取平均值。
不管你原来是一个词还是一百个词,出来都是一个16维向量。就像不管你拿来的水果是一个苹果还是一筐草莓,榨汁机出来都是一杯果汁,杯子大小一样。
第四步:线性层,做判断
拿到统一大小的向量之后,线性层做的事情本质上就是矩阵乘法加偏置。
16维的输入,乘以一个16x2的权重矩阵,加上偏置,输出两个分数,一个是"垃圾邮件的可能性”,一个是"正常邮件的可能性”。
这一步就是大厨看完配料表做判断的过程。权重矩阵就是大厨的经验,偏置就是他的直觉偏好。
第五步:Softmax,把分数变成概率
线性层输出的两个分数可能是任意数字,比如3.7和-1.2。人看着不直观。
Softmax把它们压成0到1之间的概率,加起来等于1。比如垃圾邮件0.99,正常邮件0.01。这下一目了然了,99%的把握认为是垃圾邮件。
训练过程:笨办法才是好办法
训练的代码核心长这样:
for epoch in 1..=300 {
for (tokens, label) in &training_data {
// 前向传播:输入数据,得到预测
let logits = model.forward(&tokens)?;
let probs = softmax(&logits, 0)?;
// 计算损失:预测和真实答案差多远
let loss = cross_entropy(&probs, label)?;
// 反向传播 + 更新权重:根据错误调整参数
optimizer.backward_step(&loss)?;
}
}
翻译成人话就是:
- 拿一条训练数据
- 让模型猜一下
- 看看猜对没有
- 没猜对就调整参数
- 重复300轮
就像学做菜:做一次,尝一口,咸了少放盐,淡了多放盐,做300次之后基本就稳了。
训练过程的损失值变化:
第 1 轮 | 损失: 0.5388
第 100 轮 | 损失: 0.0022
第 200 轮 | 损失: 0.0009
第 300 轮 | 损失: 0.0005
损失接近零,说明模型已经学会了。整个训练过程在普通笔记本上大约10秒。
项目文件结构
整个项目只有四个文件,加起来不到500行:
| 文件 | 职责 |
|---|---|
main.rs | 训练循环 + 推理入口 |
model.rs | 神经网络结构定义 |
tokenizer.rs | 分词器 |
dataset.rs | 训练数据集 |
训练完成后模型保存为spam_classifier.safetensors文件,下次直接加载,不用重新训练。
动手跑一下
git clone https://github.com/aarambh-darshan/spam_candle_ai.git
cd spam_candle_ai
cargo run
训练完成后进入交互模式,随便输入试试:
Enter text: hello friend
"hello friend" --> HAM (100.0%)
Enter text: click here free money
"click here free money" --> SPAM (99.9%)
Enter text: quit
Goodbye!
就是这么直接。
从这个Rust神经网络项目里你能悟到什么?
我自己搓完之后最大的感受是:动手做一遍,比看十篇教程管用。这也是我推荐用Rust机器学习入门的原因,Rust的类型系统逼着你把每一步都想清楚。
几个比较深的体会:
分词就是查字典。没有魔法,底层就是一个HashMap。你以为的高深NLP预处理,本质上跟你翻英汉词典没区别。
神经网络说白了就是矩阵乘法。剥掉所有术语的外衣,它就是一堆数字相乘再相加,一层又一层地乘。
反向传播是在找"谁该负责”。模型猜错了,沿着计算路径往回追,看看是哪个权重带偏了方向,然后微调它。就像考试考砸了复盘,是选择题扣太多还是大题没写好,针对性地补。
训练这事没有灵光一闪的时刻,就是一遍一遍地喂数据、算误差、调参数。从损失0.5到损失0.0005,靠的是耐心。
踩坑预警
训练数据太少
这个示例项目只用了40条训练数据。拿来学习够了,但放到真实场景里远远不够。真实的垃圾邮件分类器动辄需要几千上万条数据。建议先用这40条跑通全流程,再去Kaggle找真实的垃圾邮件数据集替换,别一上来就想搞大的。
模型太简单
这个模型没有隐藏层,只有一层线性层做分类。遇到复杂的文本模式,比如反讽、暗示,它搞不定。好在加一层ReLU激活的隐藏层就能显著提升表达能力,Candle完全支持,改动不到10行代码。
不认识新词
如果用户输入了训练数据里没出现过的词,分词器会直接忽略它,整句话可能变成空数组。可以加一个<UNK>(未知词)的兜底token,遇到生词就映射到它。不完美,但至少不会崩。
下一步可以怎么玩?
跑通了基础版之后,几个方向可以继续折腾:
- 加大数据量,40条数据只是开胃菜,换上真实数据集看看效果提升多少
- 加隐藏层,用ReLU激活函数增加模型的表达能力
- 搞成API,用Axum或Actix把模型包成Web服务,对外提供接口
- 上Transformer,Candle框架支持注意力机制,你可以在同一个框架里从简单垃圾邮件分类器一路升级到Transformer,深入Rust深度学习的世界
一句话总结:Candle管"跑得快",你管"想清楚"。
Cheatsheet:快速回顾
# 克隆项目
git clone https://github.com/aarambh-darshan/spam_candle_ai.git
# 运行训练 + 交互推理
cargo run
# 项目结构
main.rs --> 训练循环 + 推理
model.rs --> 网络定义(嵌入 + 线性层)
tokenizer.rs --> 分词器(HashMap查表)
dataset.rs --> 训练样本
# 核心管道
文本 --> 分词 --> 嵌入(16维) --> 均值池化 --> 线性层(2分类) --> Softmax --> 结果
# 关键依赖
candle-core --> 张量运算
candle-nn --> 神经网络模块
好了,今天带你从零手搓了一个Rust神经网络。500行代码,10秒训练,四个文件,一台笔记本就够了。
Rust机器学习说到底就是数学、代码和重复。没有什么神秘的。
自己动手写一遍,每一次权重更新你都看得见,每一个模式模型是怎么学会的你都清楚。这种理解是读论文读不来的。
你现在学机器学习最卡的一步是哪一步?数学基础、框架选型、还是不知道从哪个项目开始?欢迎在评论区聊聊,说不定你卡的那个点,正好是别人踩过的坑。
下一篇我们聊聊怎么给这个模型加上注意力机制,让它不光看单词出现了没有,还能理解词和词之间的关系。从"能用"到"好用",差的就是这一步。
如果觉得有帮助,转发给你身边对Rust或者机器学习感兴趣的朋友吧。写这种从零手搓的教程确实费时间,但每次看到有人说"终于搞懂了",就觉得值了。关注梦兽编程,后续还有更多Rust实战的干货。
参考资源: