从800ms到90ms:Rust的Rayon库如何拯救了我的多线程噩梦
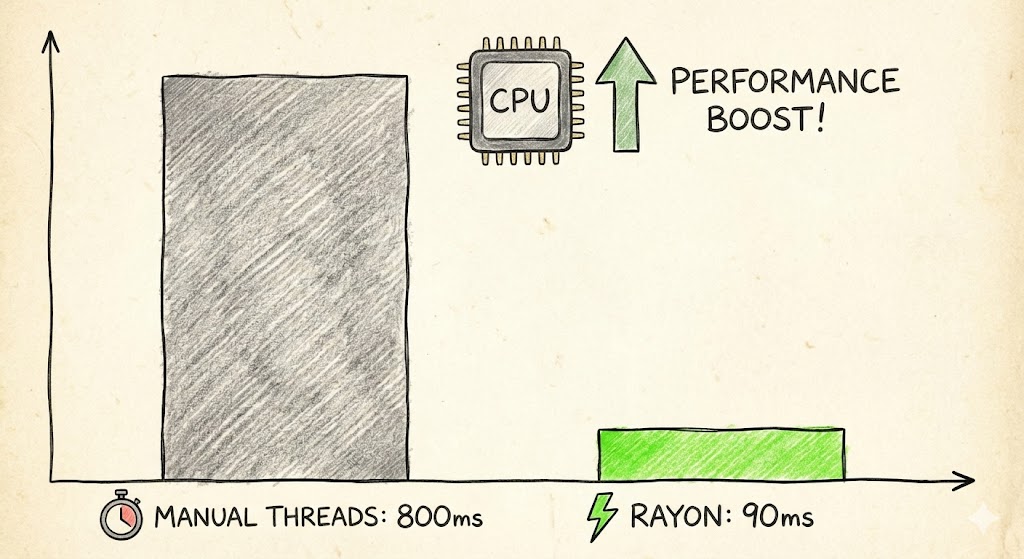
800毫秒,说长不长说短不短
在Rust并发编程的世界里,性能优化是个绑不开的话题。
老实说,当我第一次看到程序跑完一个批处理任务要800毫秒的时候,我是不当回事的。
800毫秒嘛,不到一秒钟,喝口水的功夫就过去了。我甚至安慰自己:这点时间算什么,用户根本感觉不出来。
但是,当这个任务在生产环境里被调用几百上千次的时候,问题就大了。用户开始反馈"系统有点慢",老板开始问"能不能优化一下"。
我看着自己精心编写的多线程代码,陷入了沉思。
我的"精心设计"是怎么写的
来,让我给你看看我当时写的代码,典型的"教科书式"多线程实现:
use std::thread;
fn process_data(v: &Vec<i32>) -> i32 {
v.iter().map(|x| x * 2).sum()
}
fn main() {
let data: Vec<i32> = (0..1_000_000).collect();
let chunks: Vec<&[i32]> = data.chunks(250_000).collect();
let mut handles = vec![];
for chunk in chunks {
handles.push(thread::spawn(move || {
process_data(&chunk.to_vec())
}));
}
let mut total = 0;
for h in handles {
total += h.join().unwrap();
}
println!("Result: {}", total);
}
看起来挺标准的对吧?把数据分成4块,每块25万个元素,开4个线程并行处理,最后汇总结果。
这代码写出来的时候,我还挺得意的。心想:这不就是多线程的精髓吗?分而治之,并行计算,完美!
然而现实给了我一巴掌。
问题出在哪?
跑了基准测试之后,结果是:800毫秒 ± 10毫秒。
我的第一反应是:不对啊,4个线程应该快4倍才对,怎么还这么慢?
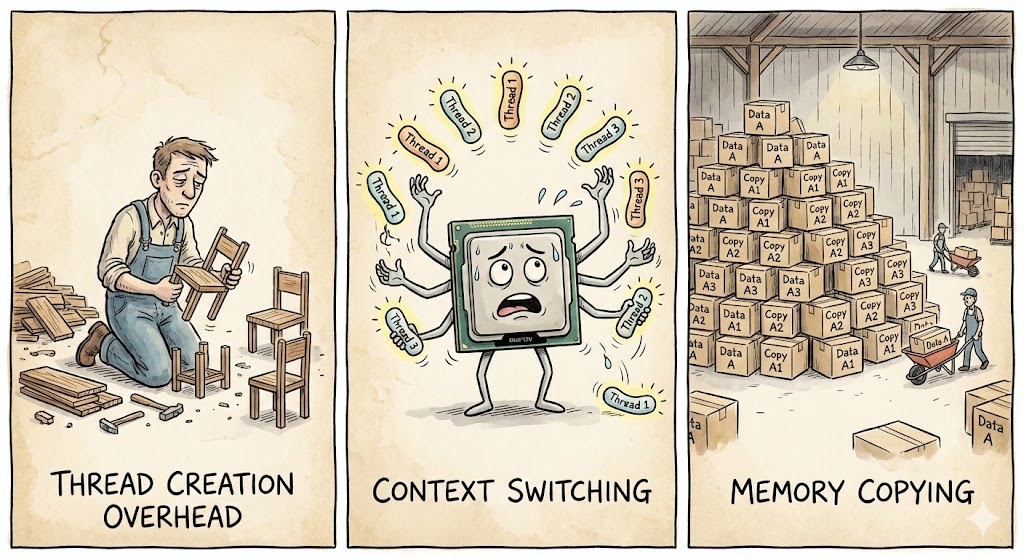
后来我仔细琢磨了一下,问题其实很明显:
第一,线程创建的开销。每次跑任务都要新建线程,这个开销可不小。就像你每次搬家都重新买一套家具,用完就扔,下次再买。
第二,上下文切换的成本。操作系统在多个线程之间来回切换,每次切换都要保存和恢复状态,这时间都是白白浪费的。
第三,内存拷贝。注意到代码里的chunk.to_vec()了吗?每个chunk都要拷贝一份数据到新线程,100万个数字要拷贝4次,这内存带宽就这么耗没了。
这三个问题叠加在一起,直接把我的并发性能优化努力变成了无用功。
遇见Rayon:从此世界不一样
后来有个同事给我推荐了Rayon这个库。说实话,我一开始是抱着"又一个轮子"的心态去看的。
直到我把代码改成这样:
use rayon::prelude::*;
fn main() {
let data: Vec<i32> = (0..1_000_000).collect();
let total: i32 = data.par_iter()
.map(|x| x * 2)
.sum();
println!("Result: {}", total);
}
跑了一下基准测试:90毫秒 ± 5毫秒。
我当时就愣住了。
同样的功能,代码少了一半还多,性能快了将近9倍。这什么鬼?
Rayon到底做了什么魔法?
说Rayon是魔法其实不准确,人家是有真本事的。作为Rust生态中最流行的并发库之一,Rayon的核心技术叫工作窃取调度器(Work-Stealing Scheduler)。
简单来说,就是这么个意思:
+-------------------+ +-------------------+
| 线程池 |<----->| 任务队列 |
+-------------------+ +-------------------+
| ^
v |
CPU核心1 ←——工作窃取——→ CPU核心N
传统做法是把数据预先分成固定的几块,每个线程处理一块。但问题是,如果某个线程的任务先完成了怎么办?它就只能干等着,看着别的线程忙活。
Rayon的做法不一样。它把任务动态分配给线程,当一个线程干完自己的活,发现还有别的线程没干完,它就会"偷"一部分工作过来自己干。
这就像一群人包饺子,传统做法是每人分一堆馅儿,包完就坐着等。Rayon的工作窃取算法就不一样了,包完自己的就去帮别人包,大家一起干到所有馅儿都包完为止。这种动态负载均衡才是真正高效的并发模式。
什么时候该用Rayon?
说到这儿你可能已经摩拳擦掌准备重写所有代码了。别急,有几个注意事项:
Rayon适合的场景:
- 数据量够大(至少几万条记录),就像请来一桌朋友包饺子,馅多才好分工
- 每个元素的处理逻辑差不多,大家都在包同一个馅,不用有人切菜有人烧水
- CPU密集型计算,主要是在桌边干活,不用跑去外面取快递
不太适合的场景:
- 数据量太小(几百几千条),就几盘饺子,自己包完的时间可能比喊人还快
- 处理逻辑涉及大量IO操作,一会儿等磁盘一会儿等网络,帮手来了也只能干等
- 任务之间有复杂的依赖关系,像要先调味再擀皮,环节一多并行反而容易乱
小数据量用Rayon反而可能更慢,因为并行调度本身也有开销。就像你叫了10个快递小哥来送一个包裹,协调他们的时间比你自己送还长。
最后的性能对比
来看看最终的数据:
| 版本 | 耗时(ms) | 提升倍数 |
|---|---|---|
| 手动线程管理 | 800 | 1x |
| Rayon并行迭代器 | 90 | ~8.9x |

将近9倍的性能提升,代码量还少了一半。这买卖,划算。
总结一下
这次性能优化给我最大的教训是:最好的优化不一定是微调代码细节,有时候是选对工具。
我花了好几个小时琢磨怎么调整线程数量、怎么优化数据分块策略,结果发现换个库就解决了。这种感觉怎么说呢,有点像你蹲在那儿用手拧螺丝,旁边有人递过来一把电钻。
如果你还在Rust里手动管理线程做并发编程,建议停下来想想:真的有必要吗?
Rayon已经帮你做好了绝大部分脏活累活,包括线程池管理、工作窃取调度、负载均衡。你只需要把iter()换成par_iter(),剩下的交给它就行。
当然,也别忘了测试。优化的第一原则永远是:先测量,再动手。
如果这篇文章对你有帮助,欢迎点赞、转发、收藏三连。关注我,后续还会分享更多Rust实战经验和性能优化技巧。
有问题可以在评论区留言,我们一起讨论。