性能优化
共 43 篇

JavaScript 真的跑不过 GPU 吗?三个真实场景的 benchmark 把我整不会了
粒子模拟、矩阵乘法、图像处理——WebGPU 和 JavaScript 的真实性能对比出人意料。不是所有场景都需要 GPU,有些事情 CPU 干得反而更利索。
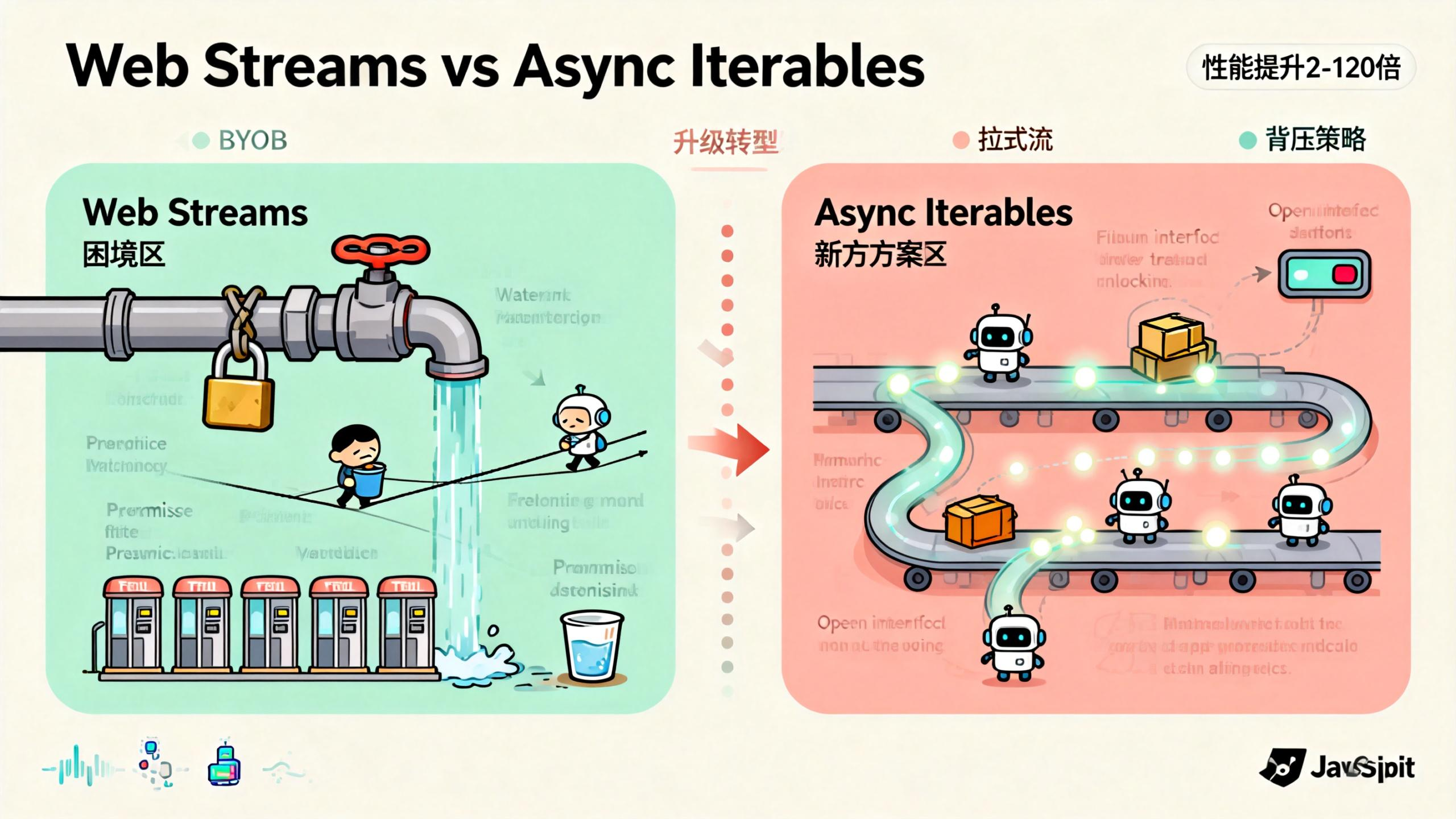
JavaScript流的困境:Web Streams API做错了什么
Web Streams API被锁住了?BYOB读法让人头大?Node.js核心贡献者James Snell提出了一套替代方案,用async iterables重新定义流处理,性能提升2到120倍。看pull与push两种模型如何影响你的代码性能。
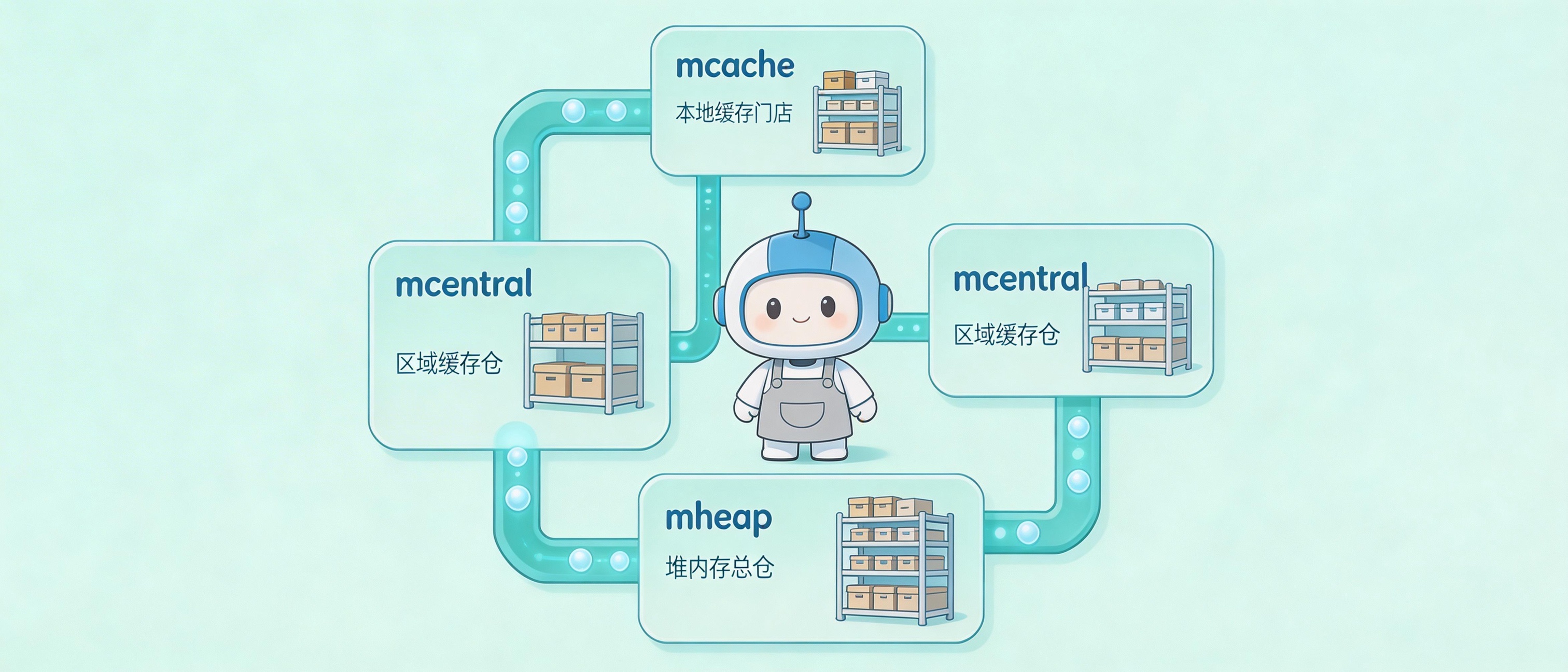
Go内存分配器:一个仓库经理的自我修养
从64MB仓库到8KB货架,揭秘Go如何用三级缓存架构让内存分配快到飞起。深入理解arena、span、size class的设计哲学,看懂tcmalloc思想在Go中的落地实践。

PostgreSQL 18 异步 IO 革命:为什么说这是五年内最重要的数据库更新?
PostgreSQL 18 异步 IO 深度解析:与传统同步IO相比,io_uring 如何让数据库性能飙升3.4倍?实际测试数据与升级指南全攻略。

Rust 里到处都是 Arc<Mutex<T>>?你可能把 Java 的架构搬过来了
Arc<Mutex> vs 消息传递:为什么 Rust 里的共享状态模式会成为性能瓶颈?深度解析 Tokio mpsc channel 替代方案、Actor 模式实战代码对比与性能测试数据。
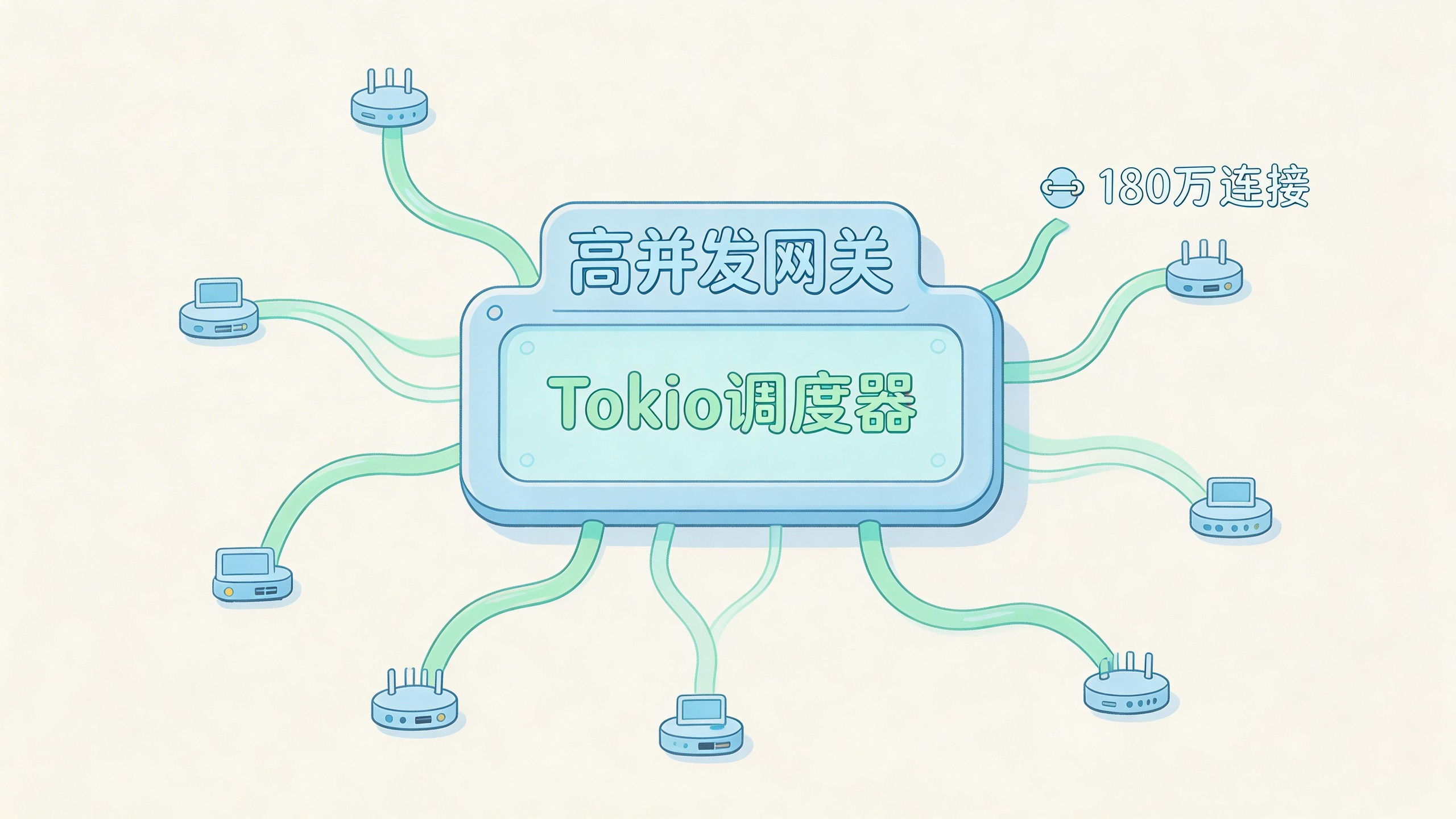
从0到180万连接:一个Rust/Tokio网关的真实扩展之路
这不是一个Rust多快的成功故事。这是一篇关于当并发连接数从几十万跨到百万级别时,调度器、背压和可观测性比原始效率更重要的后记。
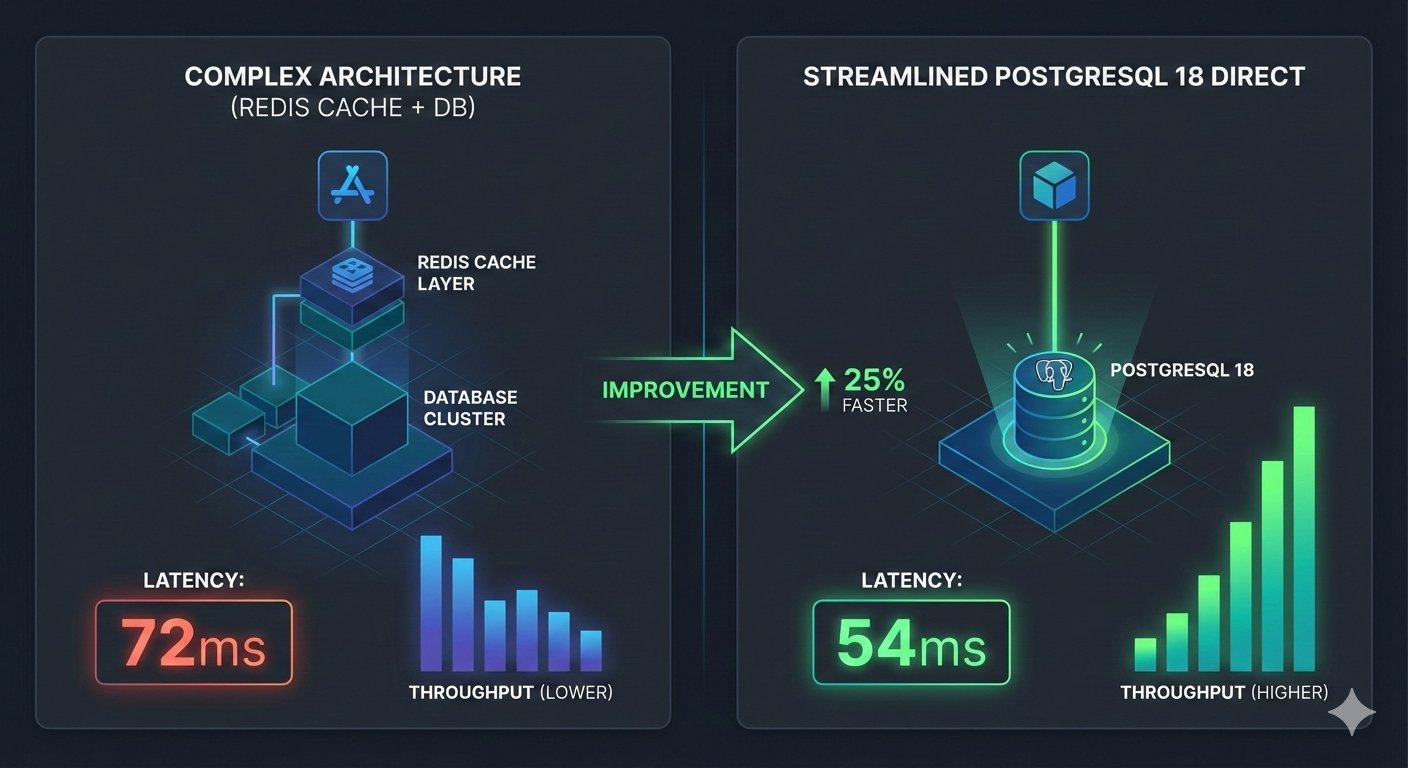
PostgreSQL 18 基准测试数据:上次说能干掉 Redis 缓存层,你们不信?
PostgreSQL 18 基准测试实测数据:异步IO + skip scan 带来的数据库性能飞跃。1K 并发用户生产环境对比,去掉 Redis 后 P95 延迟从 72ms 降到 54ms,第三方测试顺序扫描快 3.4 倍。

4秒生成4000页PDF!这个Rust开源库要把所有PDF工具干翻
oxidize-pdf:一个纯Rust写的PDF引擎,不依赖任何C库,5MB单文件,性能却干翻Chromium/Java全家桶。

PostgreSQL 查询解析慢成狗?PgDog 把 Protobuf 扔了,直接快 5 倍
PgDog 是一个用 Rust 写的 PostgreSQL 代理,他们发现解析 SQL 查询时,Protobuf 序列化居然是性能杀手。于是他们做了一个骚操作:直接抛弃 Protobuf,用原生 Rust 绑定 C 代码,结果解析速度快了 5 倍多。

Homebrew 太慢?试试这个 Rust 版本,速度快 20 倍
ZeroBrew 是一个用 Rust 写的 Homebrew 替代品,安装软件包快得像闪电。今天和你聊聊它为什么这么快,以及怎么安全地试用它。