把整个人生塞进一个数据库:380万行数据背后的量化自我实验
你有没有过这种感觉:周一明明喝了三杯咖啡,周五回忆起来却只记得"好像喝了不少"?或者觉得自己最近"老是熬夜",但真问起来又说不出具体几点睡的?
人类的记忆不太靠谱,擅长编故事,却不擅长记数字。
Felix Krause —— 对,就是那个做 Fastlane 的家伙 —— 干了件更狠的事。他把整个人生塞进了一个数据库。三年下来,攒了38万条记录,48张可视化图表,全都开源在 GitHub 上。
这不是什么极客的强迫症发作。这是一场关于"认识自己"的硬核实验。
数据库里的"我"长什么样
Felix 的项目叫 FxLifeSheet,听起来像什么理财产品的名字,实际上是个 Quantified Self(量化自我)系统。
什么叫量化自我?说白了就是用数据记录生活。
你每天走多少步?Apple Health 知道。你在电脑前坐多久?RescueTime 知道。你去过哪些地方?Foursquare Swarm 知道。今天天气怎么样?气象 API 知道。
Felix 做的事情,就是把这些散落各处的数据全都"搬"到一个 Postgres 数据库里,再加上自己手动记录的一些东西——心情、咖啡摄入、社交活动、阅读时间等等。
结果呢?380万行数据。
这是什么概念?假设你从出生开始每天记日记,每篇写1000字,记到80岁,大约是2900万字。380万行数据换算成文字量,大概相当于把你的人生翻倍记录了一遍。
量化自我追踪了哪些数据
看一眼这张"人生清单",你会发现 Felix 真的把"量化"这件事做到了变态级别。
自动追踪的数据:
- 电脑使用时间(RescueTime 自动记录)
- 地理位置(Foursquare Swarm 签到)
- 天气(气象 API 每天拉取)
- 健康数据(Apple Health 同步)
手动记录的数据:
- 每日心情评分(1-5分)
- 咖啡摄入量
- 睡眠质量和时长
- 运动类型和强度
- 社交活动(见朋友、参加活动)
- 阅读时间
- 冥想时间
- 生病状态
- …还有90多项
他甚至记录了自己每次"觉得今天特别有成就感"的时刻。
这不是记日记。这是在给人生装监控摄像头。
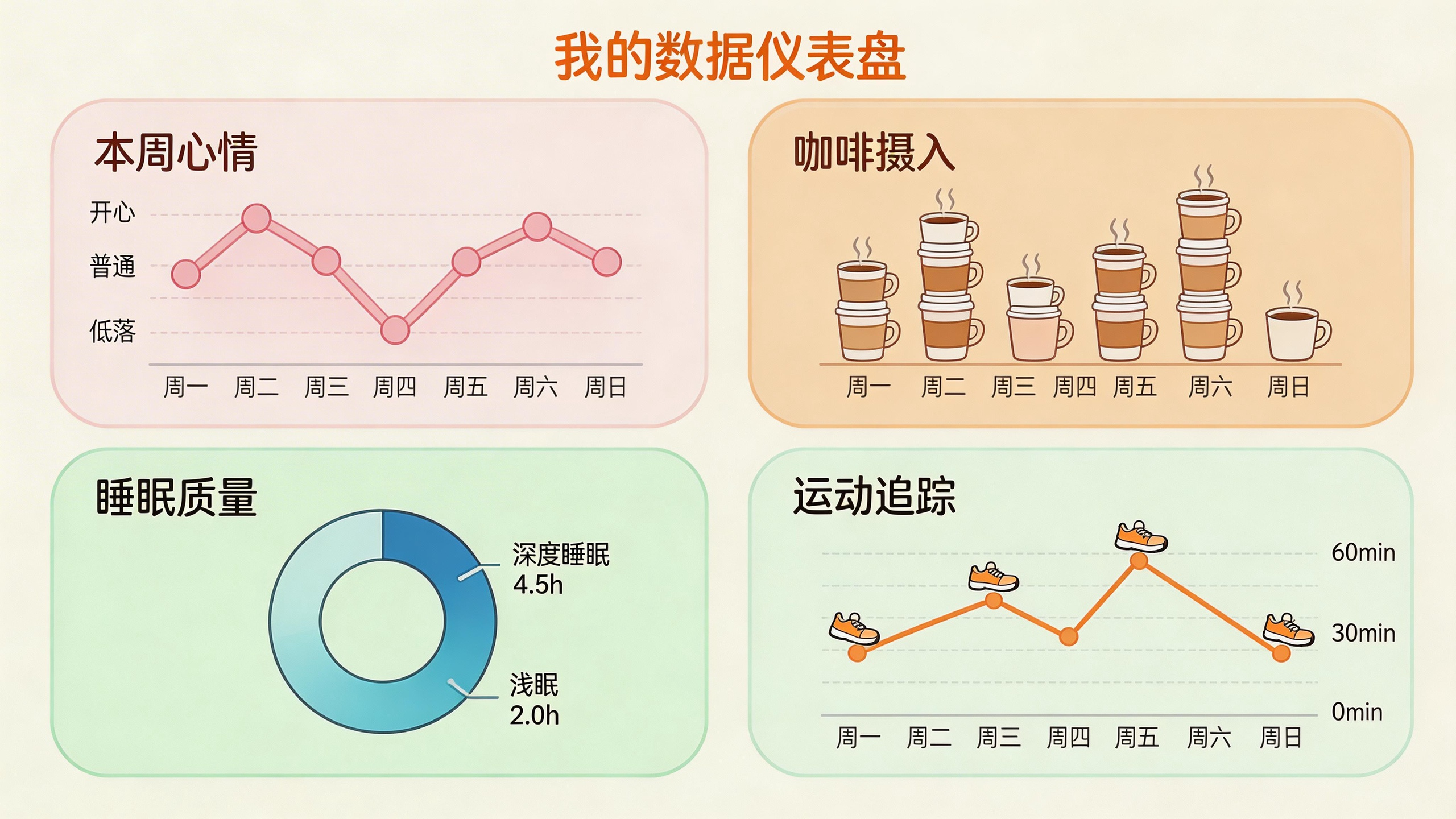
48张图表告诉你什么
有了数据,下一步就是让它"说话"。Felix 用 Ruby + JavaScript + Plotly 搭了一套可视化系统,生成了48张图表。
这些图表能回答一些你从来不敢问自己的问题:
“我什么时候心情最好?” 不是周末,不是发工资那天。数据显示,Felix 心情最高分的时刻通常出现在户外运动后的下午。运动+阳光的组合,比任何"自我提升"技巧都管用。
“咖啡真的让我更清醒吗?” 数据说不一定。Felix 发现咖啡摄入量和工作效率的相关性几乎为零。有时候喝完咖啡反而更困——可能是咖啡因耐受性在作祟。
“天气会影响我的社交吗?” 会。晴天的时候,Felix 的社交活动数量比雨天高出40%。人类果然是光合作用生物。
“我到底在电脑前坐了多久?” 平均每天8.6小时。最高纪录是14小时。看到这个数字的时候,Felix 说他"被吓到了"。
这些发现有什么用?
用处在于:这些是事实,不是感觉。
“我觉得自己最近老是熬夜"和"数据显示你过去一周平均睡眠时间减少了23%",后者的冲击力完全不同。数据不会说谎,也不会给自己找借口。
FxLifeSheet 技术栈解析
你可能会想,搭建这样一套系统肯定很复杂吧?
实际上,Felix 的技术选型相当朴素:
- 数据库:PostgreSQL(关系型数据库,稳定可靠)
- 后端:Ruby(各种 API 拉取脚本)
- 前端可视化:JavaScript + Plotly(图表库)
- 数据采集:RescueTime、Foursquare、Apple Health 的 API,加上手动录入
整个项目的代码量不算大,核心难点在数据清洗和标准化。
比如,RescueTime 用的是 UTC 时间,Apple Health 用的是本地时间,气象 API 返回的是 Unix 时间戳。要把这些数据对齐到同一条时间线上,需要做不少脏活累活。
再比如,如何定义"社交活动”?见朋友算,那参加线下活动算吗?在咖啡店偶遇熟人算吗?这些都需要在录入数据时定义清楚,否则后期分析就是垃圾进垃圾出。
开源的意义
FxLifeSheet 在 GitHub 上以 MIT 协议开源。Felix 不是在炫技,而是想告诉所有人:
这件事,你也能做。
项目仓库里有完整的数据库 schema、数据采集脚本、可视化代码。你只需要做三件事:
- 搭一个 Postgres 数据库
- 申请各种 API key(RescueTime、Foursquare 等)
- 每天花5分钟手动记录一些数据
三个月后,你就能看到自己的人生仪表盘了。
当然,Felix 也提醒了一些"坑":
- 数据录入的摩擦力:手动记录越复杂,越容易放弃。他建议只追踪真正关心的指标
- 隐私问题:这些数据一旦泄露,比身份证号还危险。务必做好安全措施
- 分析瘫痪:有了数据不代表就能得出结论。过度分析反而会让人焦虑
量化自我,然后呢
回到最初的问题:为什么要做这件事?
Felix 在项目 README 里写了一段话,大意是:
我不是为了追踪而追踪。我是想知道自己的行为模式,然后做出改变。
数据只是工具,行动才是目的。
知道了"运动后心情会变好",他就会在心情低落的时候强制自己出去跑步。知道了"咖啡对工作效率影响不大",他就开始尝试减少咖啡摄入。
量化自我的目的不是把生活变成Excel表格,而是从"我觉得"升级到"我知道"。
人类的直觉系统在演化过程中被设计成"快速反应模式",适合应对狮子的突袭,却不适合回答"我最近为什么总是疲惫"这种需要长期观察的问题。
数据库就是那个帮你记录一切的"外置记忆体"。它不会累,不会遗忘,也不会因为心情不好而篡改数据。
你需要这套系统吗
老实说,不是每个人都适合玩量化自我。
如果你连记账都坚持不下来,大概率也坚持不了每天记录心情和睡眠时间。问题不在意志力,而是这件事本身对你来说价值不够大。
但如果你曾经有过这些困惑:
- “我总觉得时间不够用,但不知道时间去哪了”
- “我想改善睡眠,但不知道到底是哪个因素影响了它”
- “我想知道运动对我的心情到底有多大帮助”
那 FxLifeSheet 这样的系统可能值得一试。
从最简单的开始:先只追踪一件事。比如每天的心情评分,或者每天的睡眠时长。坚持一个月,看看数据会告诉你什么。
你可能会惊讶地发现,那个"总是熬夜的自己",其实只有30%的时间是真的在熬夜。或者那个"从来不运动"的自己,其实每周都有在走路,只是你没把散步当成运动。
数据有时候会推翻你的自我认知。这恰恰是它最有价值的地方。
常见问题
Q:这套系统需要多少技术基础? A:基础的数据库操作能力和简单的编程知识就够了。如果你会用 SQL 查询数据,能写一点 Python 或 Ruby 脚本,就能跑起来。Felix 的代码注释很详细,照着改改配置就能用。
Q:数据隐私怎么保证? A:所有数据都存在你自己的数据库里,不依赖任何云服务。只要你的服务器安全,数据就是安全的。当然,这也意味着你需要自己负责备份。
Q:手动记录太麻烦了怎么办? A:可以只追踪能自动采集的数据。RescueTime、Apple Health 这些都不需要手动操作。手动记录的部分,可以从每天3-5个指标开始,养成习惯再加量。
Q:数据分析需要统计学基础吗? A:基本的图表能看懂就行。Felix 的可视化系统已经做好了,你只需要解读结果。如果想做更深入的分析(比如相关性检验),可能需要学一点基础知识。
Q:这个项目还在维护吗? A:截至2026年初,FxLifeSheet 仍在 GitHub 上活跃维护。Felix 会不定期更新文档和代码。项目地址:github.com/KrauseFx/FxLifeSheet